The user part of an address is the part to the left of the
@ in an address. It is usually a single token
(such as george or
taka). The easiest way to match the user part
of an address is with the $- operator. For
example, the following rule looks for any username at our local
domain, and dequotes it.
R $- < @ $=w . > $: $(dequote $1 $) < @ $2 . >
Here, the intention is to take any quoted username (such as
"george" or
"george+nospam") and to change the
address using the dequote database-map type (dequote). The effect of this rule on a quoted user
workspace, then, might look like this:
"george"@wash.dc.gov becomes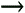 george@wash.dc.gov
"george+nospam"@wash.dc.gov becomes george+nospam@wash.dc.gov
george@wash.dc.gov
"george+nospam"@wash.dc.gov becomes george+nospam@wash.dc.gov
Because the quotation character is not a token,
"george+nospam" is seen as a single token and is
matched with the $- operator.
The -bt rule-testing mode offers an easy way to
determine if a character splits the user part of an address into more
than one token:
% echo '0 george+nospam' | /usr/sbin/sendmail -bt | head -3
ADDRESS TEST MODE (ruleset 3 NOT automatically invoked)
Enter <ruleset> <address>
> parse input: george + nospam  3 tokens
% echo '0 "george+nospam"' | /usr/sbin/sendmail -bt | head -3
ADDRESS TEST MODE (ruleset 3 NOT automatically invoked)
Enter <ruleset> <address>
> parse input: "george+nospam" 1 token
3 tokens
% echo '0 "george+nospam"' | /usr/sbin/sendmail -bt | head -3
ADDRESS TEST MODE (ruleset 3 NOT automatically invoked)
Enter <ruleset> <address>
> parse input: "george+nospam" 1 token
Note that the $- operator can be used only on the
LHS of rules, and that the $- operator can be
referenced by a $digit
operator on the RHS