kgp.py impiega alcuni trucchi che potrebbero esservi utili nella elaborazione XML. Il primo trucco consiste nel trarre vantaggio dalla consistente struttura dei documenti in input per costruire una cache di nodi.
Un file grammar definisce una serie di elementi ref. Ogni ref contiene uno o più elementi p, che possono contenere molte cose differenti, inclusi gli xrefs. Ogni volta che incontriamo un xref, cerchiamo un elemento ref corrispondente con lo stesso attributo id, scegliamo uno degli elementi ref figli e lo analizziamo. Vedremo come questa scelta venga fatta nella prossima sezione.
Ecco come costruiamo il nostro file grammar: definiamo elementi ref per il più piccolo pezzo, poi definiamo elementi ref che “includono” il primi elementi ref usando xref e così via. Quindi analizziamo il più “largo” riferimento e seguiamo ogni xref ed eventualmente stampiamo il testo reale. Il testo che stampiamo dipende dalla decisione (casuale) che facciamo ogni volta che riempiamo un xref, perciò l'output è differente ogni volta.
Tutto ciò è molto flessibile, ma c'è una contropartita: le performance. Quando troviamo un xref dobbiamo trovare il corrispondente elemento ref, ed incappiamo in un problema. xref ha un attributo id, noi vogliamo trovare l'elemento ref che ha lo stesso attributo id, ma non esiste un modo facile per farlo. La via lenta consiste nel considerare l'intera lista degli elementi ref ogni volta, e analizzare l'attributo id di ognuno di essi manualmente attraverso un ciclo. La via veloce consiste nel fare ciò una sola volta e costruire una cache, nella forma di un dizionario.
Esempio 6.37. loadGrammar
def loadGrammar(self, grammar):
self.grammar = self._load(grammar)
self.refs = {} 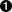 for ref in self.grammar.getElementsByTagName("ref"):
for ref in self.grammar.getElementsByTagName("ref"): 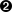 self.refs[ref.attributes["id"].value] = ref
self.refs[ref.attributes["id"].value] = ref 

| Iniziate a creare un dizionario vuoto, self.refs. | |
| Come abbiamo visto nella sezione Ricercare elementi, getElementsByTagName ritorna una lista di tutti gli elementi di un particolare nome. Possiamo facilmente ottenere una lista di tutti gli elementi ref e poi semplicemente eseguire un ciclo in quella lista. | |
| Come abbiamo visto nella sezione Accedere agli attributi di un elemento, possiamo accedere ad attributi individuali di un elemento per nome, usando la sintassi standard dei dizionari. Così le chiavi del nostro dizionario self.refs saranno i valori dell'attributo id di ogni elemento ref. | |
| I valori del nostro dizionario self.refs saranno gli stessi elementi ref. Come abbiamo visto nell'analisi effettuata nella sezione Analizzare XML, ogni elemento, ogni nodo, ogni commento, ogni pezzo di testo in un documento XML analizzato è un oggetto. |
Una volta che abbiamo costruito questa cache, ogni volta che passiamo su un xref e cerchiamo di trovare l'elemento ref con lo stesso attributo id, possiamo semplicemente leggerlo in self.refs.
Esempio 6.38. Usare gli elementi ref in memoria
def do_xref(self, node):
id = node.attributes["id"].value
self.parse(self.randomChildElement(self.refs[id]))Esploreremo la funzione randomChildElement nella prossima sezione.