


김동욱: <dwkim@ricl.konkuk.ac.kr>
조병익: <dolcho@stss.co.kr>
이형주: <kerdosa@hotmail>
김동욱: <dwkim@ricl.konkuk.ac.kr>
김동규
정재용
이 문서의 변환상태는 양호하지만, 이미지 처리상에 약간의 문제가 있습니다. 따라서, MS 워드 포맷의 원본 파일을 다운받아서 사용할 것을 권해드립니다. 시중에서 판매되고 있는 세미나 교재와 동일한 품질을 출력하고자 할 경우에는 pdf 이미지 파일을 다운받으시기 바랍니다.
원본 파일 다운로드:
차례
1. 리눅스 커널 개요
1. 서 론
최근 몇 년 동안 리눅스는 연구용이나 엔지니어 운영체제에서 기업과 사용자들에게 빠르게 다가서고 있다. 그러한 성장의 이면에는 인터넷이라는 거대한 네트워크를 통한 전세계 프로그래머들의 노력과 누구나 자유롭게 접근할 수 있도록 커널 소스가 개방되어 있다는 점이 무엇보다 큰 원인으로 작용하고 있다. 이러한 현상속에서 리눅스는 최근에는 그 영역을 빠른 속도로 넓혀가고 있으며 다양한 형태로 변형을 시키는 연구가 진행중이다. 그중에서 리눅스를 이용하여 Embedded system과 RTOS 개발은 리눅스의 커널소스의 수정을 필수적으로 수반하게 된다. 그러나 리눅스 커널은 Monolithic한 구조를 갖는 Unix 계열의 운영체제이기 때문에 각각의 독립적인 기능을 수행하는 블럭으로 분리시키거나, 각 블럭 내부의 기능을 수정하는 것은 매우 어려운 일이다. 즉 커널의 일부분의 변경은 커널의 전체의 변경으로 이어지는 것을 의미하는 것이다.
우선 커널 변경작업을 수행하기 위해서는 전체를 파악해야만 하지만, 현실적으로 한 개인이나 소수의 단체가 전체를 분석하기는 불가능하다. 따라서 이 복잡한 구조를 단순화시켜 커널을 이해하는 것은 더 나아가 진행되어질 리눅스 소스분석, 커널 수정, 또는 어플리케이션 개발에 커다란 도움을 줄것이다. 따라서 이 장의 목적을 리눅스 커널내의 프로세스, 메모리관리, 가상파일시스템, 그리고 네크웍 서비스들의 관계성에 대하여 촛점을 맞추도록 한다.
2. 리눅스 커널 개념적 구조 및 관계성
다른 운영체제와 마찬가지로 리눅스 커널은 부팅시에 하드웨어 초기화하고 메모리상에 자기 자신을 구축하여, 디스크상에 존재하는 파일들과 응용 프로그램들이 커널에서 동작할 수 있도록 한다. 이때 작업을 수행하기 위하여 시스템의 다양한 리소스들을(메모리, Cpu, 디스크, ..) 프로세스들에 분배 및 회수인 관리작업을 수행하게 되며, 수행중인 시스템 안정성도 커널이 책임을 지게 된다. 이와 같은 작업을 위하여 커널은 시스템의 하드웨어와 직접적으로 상호작용을 하게된다.
이러한 작업을 수행하는 커널이 하드웨어 리소스와 상당히 밀접한 관계를 갖고 설계되어져 있음을 인식할 수 있을 것이다. 실제 커널은 매우 복잡한 형태로 이루어져 있는데, 다시 시스템 리소스 관점에서 살펴보면 매우 단순화 되어진다.
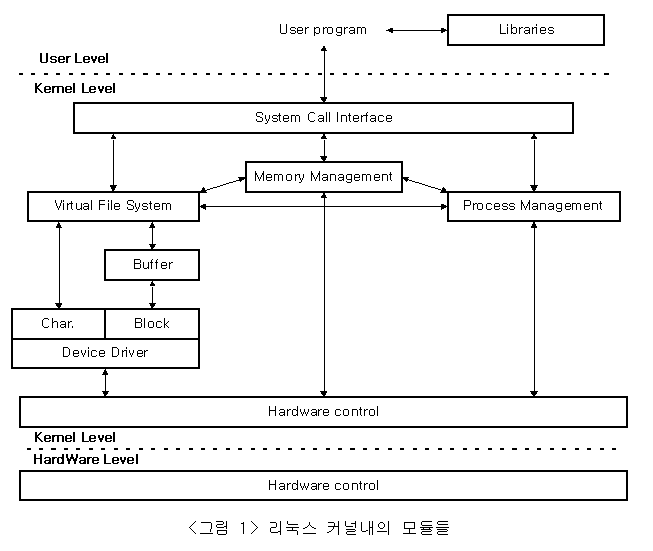
시스템의 리소스들을 CPU, Memory, 그리고 다른 여러 디바이스들로 분리시킨 관점에서 보면, CPU 관리는 프로세스 매니져, 메모리 관리는 메모리 매니져, 마지막으로 여러 디바이스들을 관리는 가상 파일시스템으로 분리 되어있다. 그리고 여기에 덧붙여서 시스템에 구축된 커널이 네트웍상의 서버 작업을 수행하는 네트웍 서비스 모듈이 추가되어질 수 있다. 다음 그림은 커널내에서 리소스 관리별로 분류된 모듈의 구조와 관계를 나타낸다.
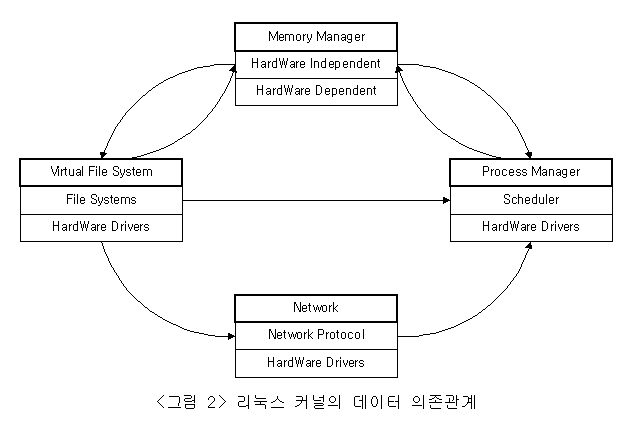
리눅스 커널은 물리적 메모리에 현 시스템의 상태에 대한 정보를 유지하게한다. 그러한 이유로 커널 내부는 여러 종류, 즉 시스템내의 리소스의 상태를 나타내는 데이터 구조체가 존재하며, 리눅스 커널내의 모듈들에 의하여 이용되어진다. 또한 이 구조체들은 모듈들 사이에서 데이터 공유를 위하여 사용되어진다. 이것은 리눅스 커널이 단일체(monolithic) 구조체임을 증명하고 있는 것이다. 따라서 하나의 데이터 구조체내의 값이 수정되어지면, 그에 관련되어져 있는 모듈들은 자동적으로 업데이트가 이루어진다. <그림 2>는 리눅스 커널의 중요한 몇개의 모듈들간의 데이터 의존 관계성을 나타내고 있다.
3. 커널의 내부 모듈
3.1 프로세스 관리(Process Management)
3.1.1 프로세스
시스템내의 사용 가능한 리소스들을 할당받아 사용자의 작업을 수행하는 프로세스는 구조체 task_struct로 표현되어진다. 이 구조체에는 현 프로세스에 할당된 리소스들을 나타내는 필드와 프로세스에 관련된 정보를 나타내는 여러 종류의 필드들로 구성되어져 있다.
필드중에는 프로세스의 현 상태를 나타내는 필드가 존재하는데, 프로세스의 상태는 TASK_RUNNING, TASK_INTERRUPTIBLE, TASK_UNINTERRUPTIBLE, TASK_STOPPED, TASK_ZOMBIE, TASK_SWAPPING로 표시될 수 있으며, 이 상태 값들은 프로세스의 상태에 따라 필드에 저장되어진다. 예를 들어, TASK_RUNNING이란 상태는 프로세스가 Run queue에서 대기상태에 있거나 현재 CPU를 점유하고 실행되고 있는 상태임을 나타낸다. 그리고, TASK_INTERRUPTIBLE이란 프로세스가 특정 사건이 발생하기를 기다리고 있는 중이며 도중에 시그널에 의해 다시 활성화될 수 있는 상태임을 나타낸다. 결국 프로세스의 상태가 바뀔 때마다 그 상태정보를 이 필드에 저장해준다.
또한 프로세스의 우선순위를 나타내는 필드와 프로세스가 강제 리스케쥴링 없이도 실행을 계속 진행시킬 수 있는 clock tick의 값을 유지하는 필드가 존재하며, 마지막 시스템 호출의 faulting의 에러 번호를 유지하는 필드도 있다.
실행중인 모든 프로세스들은 다른 프로세들과 관련이 되어져 있기 때문에 이 관계성을 유지하기 위하여 연결 리스트를 표현하는 필드들이 존재한다. 즉 예를 들어, 한 프로세스의 부모 프로세스, 형제 프로세스, 그리고 자식 프로세스를 표현하는데 사용되어진다.
마지막으로 프로세스의 ID 정보는 프로세스 ID와 그룹 ID로 표현되어지고 있으며, 프로세스가 사용자 모드에서 소비한 타이밍에 관한 정보를 나타내는 필드가 존재한다.
모든 실행 프로세스들은 프로세스 테이블내에 하나의 entry를 차지하고 있다. 그 프로세스 테이블은 구조체 task_struct의 배열로써 구현되어져 있다. 그 프로세스 테이블의 첫번째 entry는 모든 프로세스의 조상 프로세스이며 가장 먼저 리눅스에서 실행되어지는 프로세스 init가 되어진다.
3.1.2 스케줄러
리눅스의 프로세스 동작 및 생성에 대한 관리는 전적으로 스케줄러에 의해서 이루지고 있다고 해도 과언은 아니다. 따라서 이 스케줄러의 성능은 사용자의 작업을 수행하는 프로세스들에 영향을 미치어 전체 리눅스 시스템의 성능과 밀접한 관계를 가지고 있다. 다음은 리눅스 스케줄러의 역활들을 나열하고 있다.
1. 하나의 프로세스의 자식 프로세스 생성을 허용한다.
2. 여러 프로세스중 CPU에 접근하는 프로세스를 결정한다.
3. 인터럽트를 접수하고 이를 적당한 커널내의 모듈들에 전달한다.
4. 사용자 프로세스에 시그널을 보낸다.
5. 시스템의 타이머를 제어한다.
6. 프로세스 종료시 그 프로세스에 할당되어졌던 리소스들을 해제하는 역활을 수행한다.
3.2 메모리 관리(Memory Management)
리눅스는 가상 메모리를 지원하기 때문에, 물리적 메모리에 대한 리눅스 커널의 모든 접근은 이 메모리 매니져를 통하여 이루어진다. 물리적 메모리에 대한 모든 접근을 제어하고 있는 메모리 매니져는 다음과 같은 역활을 수행한다.
o 커다란 메모리 공간 제공
o 보호(protection)
o 메모리 매핑
o 물리적 메모리에 대한 공정한 할당
o 메모리 공유
메모리 매니져는 가상 메모리 어드레스를 물리적 메모리로 매핑하기 위하여 하드웨어 메모리 매니져를 사용한다. 사용자 프로세스가 메모리 공간을 접근할때, 하드웨어 메모리 매니져는 이 가상 어드레스를 실제 물리적 어드레스로 변환시켜서, 실제 물리적 메모리에 접근을 실행한다. 이러한 매핑 작업이 존재하기 때문에, 사용자 프로세스는 가상메모리가 실제 물리적 메모리 어느곳을 가르키는지 알 필요가 없는 것이다. 이것은 메모리 매니저가 사용자의 메모리를 물리적 메모리내에서 이동하는 것을 허용하게 되므로, 메모리 매니저는 두개의 사용자 프로세스가 물리적 메모리를 공유하도록 처리할 수 있다.
또한 메모리 매니져는 현재 사용하지 않는 메모리내의 사용자 프로세스의 page를 스왑할 수 있다. 이것이 시스템내에서 사용 가능한 물리적 메모리보다 더 큰 영역을 사용자 프로세스가 사용할 수 있도록 한다. 이 작업은 커널의 데몬(kswapd)이 수행한다. 데몬 kswapd은 주기적으로 최근에 사용되어지지 않은 paging을 검사하게 된다. 이 page들이 물리적 메모리로부터 퇴거되어진다. 그리고 다시 접근이 필요한 경우를 위하여 디스크에 저장되어진다.
3.3 가상 파일시스템(Virtual File System)
리눅스는 여러 종류의 파일시스템과 하드웨어 디바이스들을 지원한다. 서로 다른 접근 방법을 가진 파일시스템과 하나의 특정 장비의 경우 제조 회사에 따라서 여러 종류의 운용방법이 존재하기 때문에 리눅스는 쉽게 확장되어질 수 있는 가상 파일시스템을 유지함으로써 이 문제를 해결한다. 이 가상 파일시스템은 다음과 같은 다양한 역활을 수행할 수 있다.
o 다양한 하드웨어 디바이스 지원
o 다양한 논리적 파일시스템 지원
o 다양한 실행 포맷 지원
o 파일시스템들과 하드웨어 장비들에 대한 공통의 인터페이스 지원
o 파일들에 대한 향상된 접근
o 파일들에 대한 보안
3.3.1 파일시스템
디바이스 특정 파일을 통하여 물리적 디바이스들을 접근하는 것은 가능하나, 이보다는 파일시스템을 통하여 디바이스들을 접근하는 것이 일반적인 방법이다. 이 파일시스템의 역활은 가상 파일시스템의 마운트 포인트에 마운트되어, 연결된 디바이스내에 구축된 파일과 디렉토리 구조에 대한 정보를 커널이 접근할 수 있도록 한다. 일반적으로 운영체제들은 오직 하나의 파일시스템만을 지원하나, 현재 리눅스에서는 쓰기 작업까지 고려하였을때, 지원 가능한 파일시스템은 약 15가지 정도 되어진다.
리눅스는 일반 Unix 계열의 운영체제들처럼 inode 개념을 사용하여 다양한 객체들의 지원으로 발생하는 상호 이질적인 형태들의 문제를 해결한다. 즉 리눅스에서는 inode를 블럭 디바이스상에 존재하는 다양한 형태의 객체들을 동일한 형태로 표현하는데 이용하고 있다. inode의 역활은 리눅스 커널 내부에서 모든 파일들을 접근하고 할때 동일한 형태로 인식할 수 있도록 하고, 디스크상에 존재하는 파일의 모든 정보들을 접근할 수 있는 디스크상 위치 정보를 나타내기도 한다. 또한 이 inode들은 할당된 buffer, 파일의 크기, 그리고 디바이스 블럭과 offset들을 포함한다.
3.3.2 디바이스 드라이버
디바이스 드라이버층은 모든 물리적 디바이스들에 대한 공통의 인터페이스를 제공하는 역활을 한다. 리눅스 커널은 문자, 블럭, 그리고 네트웍으로 이루어진 세가지 형태의 디바이스 드라이버들을 가지고 있다. 테입 드라이버와 모뎀같은 문자 디바이스는 항상 순차적으로 처리되어지고, 블럭 디바이스는 블럭 크기의 배수로써 램덤하게 접근되어지는 차이점을 갖고 있다.
리눅스에서는 모든 디바이스 드라이버들을 파일 오퍼레이션 인터페이스를 통해 지원한다. 따라서 각 디바이스는 파일 시스템의 파일로써 인식되어지고 접근되어지는 것이다. 이 파일 인터페이스를 통하여 모든 디바이스들을 리눅스 커널에서 처리하기 때문에, 이것은 새로운 디바이스를 추가하는 작업이 쉽게 이루어질 수 있는 것이다.
3.4 네트웍 서비스(Network sevice)
리눅스의 네트웍 서비스 모듈은 머신들간 또는 소켓 통신 모델들간에 네트웍 연결을 제공하기 위하여 BSD 소켓과 TCP/IP 네트워킹 전체를 지원한다. BSD 소켓은 INET 소켓의 상위에 존재하는 계층으로써 VFS와 유사한 역활을 수행하며, 소켓 연결에 대한 일반적인 데이터 구조체를 관리한다. BSD의 목적은 공통의 인터페이스에 추상화되어진 통신처리를 통하여 좀 더 유연한 호환성을 제공하자는 것이다. 그 이유로 BSD 인터페이스는 근래의 Windows와 Unix와 같은 운영체제들에 광범위하게 사용되어지고 있다. 그리고 INET 소켓은 IP 기반의 프로토콜인 TCP와 UDP의 통신 종점을 관리한다.
UDP는 connectionless, unreliable data transmission 서비스를 제공하고, 이것은 IP층으로 부터 패킷 수신과 패킷이 전송되어질 목적지를 찾는 역활을 수행한다. 만일 목적지가 발견되지 않으면, 에러 처리하고 그렇지않은 경우 충분한 buffer가 존재한다면, 패킷 데이터들을 소켓으로 부터 수신한 패킷 리스트로 삽입한다.
TCP 프로토콜은 매우 복잡한 구조를 갖고 있다. 전송과 수신사이에 데이터 전송을 조정할뿐만 아니라, 복잡한 connection 관리를 수행한다. TCP는 데이터를 상위층에 하나의 stream으로 올려주는 역활도 수행한다. 그리고 IP 프로토콜은 패킷 전송 서비스를 수행한다. 패킷과 패킷의 목적지가 주어진 경우, 올바른 호스트에 패킷을 라우팅하는 역활을 수행한다.
네트웍 I/O의 시작은 한 소켓에 대해 읽기와 쓰기작업의 발생으로 부터 생성되어진다. 이것은 VFS에 의해서 관리되어지는 시스템 호출 read와 wirte를 발생시키게 되고, 이 시스템 호출로부터 실제 BSD 소켓의 함수 sock_write()의 실제 작업이 이루어지게 된다. 그리고 컨트롤 흐름은 함수 inet_write()로 이동되어진다. 이 함수의 호출은 transport층의 write 함수를 호출하게 된다.
transport층 write 루틴은 전송하고자 하는 데이타를 패킷 단위로 쪼개는 역활을 수행하게된다. 그리고 컨트롤은 전송되어질 패킷에 IP 프로토콜 헤더를 만드는 함수 ip_build_header()로 전달되어지고, TCP 프로토콜 헤더를 생성하는 함수 tcp_build_header()이 호출되어진다.
이 작업이 한번 수행되어지고 나면, 하위층에 존재하는 디바이스 드라이버들이 실제로 데이터 전송 및 수신을 수행하게 된다.
2부 프로세스 관리
이 장에서는 리눅스 커널 버전 2.2.13를 대상으로 분석하였음을 미리 밝히는 바이다. SMP (Symmetric Multi Processing)를 제외하고 설명되어진다. 또한 i386를 대상으로 한다.
프로세스란 실행중인 프로그램이다. 프로그램 그 자체만으로는 프로세스라고 하지 않는다. 프로그램은 단순히 컴파일 되어 디스크에 저장되어 실행 할 수 있는 명령어 코드와 데이터를 가진 수동적인 존재이다.
이에 반해 프로세스는 프로그램에 더하여 그 이상의 의미를 갖는다. 프로세스는 프로그램 카운트와 CPU 레지스터 값들, 복귀 주소, 그리고 임시변수와 일시적인 데이터를 저장하는 스택 등도 포함하는 개체이다. 즉 프로세스는 CPU에서 실행 되는데 필요한 모든 자료들을 가지고 있어야 하는 능동적인 실체이다.
리눅스에서는 많은 프로세스들이 있을 수 있다. 그래서 리눅스 커널은 모든 프로세스에게 공정하고 효율적으로 CPU를 차지할 기회를 주어야 한다. 그렇지 못하면 multiprocessing의 의미는 희석될 것이다. Multiprocessing을 간단히 말하면 실행중인 프로세스는 시스템 자원(disk access 등의 종류)을 기다리거나, 자신의 timeslice를 다 소모했거나, 인터럽트등으로 인해 선점(preemption)되기 전까지 계속 실행되며, 중단 시에는 시스템 자원(CPU)를 반환하고 자신에게 다시 CPU가 할당되기까지 기다려야 한다. 그사이에 다른 프로세스가 리눅스로부터 자원을 할당 받아 실행하게 된다.
2.1.프로세스 상테
리눅스에서 하나 이상의 CPU를 가진 시스템일지라도 모든 프로세스가 동시에 CPU를 차지하고 실행될 수는 없을 것이다. 실행 중이던 프로세스가 어떠한 이유로든지 CPU를 다른 프로세스에게 양보한다. 그리고 자신은 아래 그림의 한가지 상태로 가게 될 것이다.
-실행 준비 상태 : scheduler에 의해 CPU을 할당 받을 때까지 run queue에 대기 한다
< 그림 2-1 >프로세스 상태도
-실행 중 : 스케줄러에 의해 CPU를 할당 받고 실행중인 상태
* 위 두가지 상태는 리눅스 소스에는 TASK_RUNNING으로 정의 된다
-중단 중 : 수면 상태이다. 리눅스 소스의 TASK_INTERRUPTIBLE과 TASK_STOP에 해당한다. TASK_INTERRUPTIBLE은 인터럽트 singnal를 받았을 때, TASK_STOP은 사용자의 ctrl-Z 나 SIGSTOP signal를 받았을 때 프로세스는 중단된다. 다시 signal를 받으면 프로세스는 실행준비 상태가 된다.
-대기 중 : 수면 상태이다. 프로세스가 이벤트나 자원이 할당되기를 기다리는 상태이다.
인터럽트가 금지된 상태로서 프로세스는 하드웨어를 직접 기다리면서 어떤환경하에서도 인터럽트 되지 않는다.1 리눅스 소스파일의 TASK_UNINTERRUPTIBLE에 해당한다.
-Zombie : 종료된 프로세스로서 task_struct 자료구조가 아직도 메모리에서 해제되지 못하고 task 벡터 테이블에 링크 되어있는 상태이다. 부모 프로세스는 자식 프로세스가 종료되기를 기다리고 있다가 자식 프로세스가 종료하면 메모리에서 해제하고 task 벡터 테이블에서 제거해야 한다. 그러나 그렇지 않은 경우 자식 프로세스는 Zombie 상태가 된다.2
-기타 : TASK_SWAPPING 상태는 메모리 부족으로 인해 프로세스가 swap out 된 상태이다.
2.2 task struct
앞에 서론에서도 설명했듯이 프로세스는 CPU에서 실행되어지는데 필요한 정보를 보관
할 자료구조를 가지고 있다. 그 자료구조가 바로 <include/linux/sched.h>에 정의된
task_struct이다. 이 자료구조는 많은 엔트리를 가지고 있다. 이것들은 프로세스를 관리하는
데 필요한 정보들이다. 그 중 스케줄링과 관계되어진 몇가지 엔트리를 간단히 설명한다.
-has_cpu : SMP 인 경우에 동시에 여러 개의 프로세스가 서로 다른 CPU를 차지하고 실행중일 경우가 있다. 그런 경우 사용 된다.
시간을 측정하는 방법과 시스템의 시간을 유지하는 방법으로 리눅스는 10ms(=1/100초)마다 발생하게 한 타이머 인터럽트를 이용한다.
3.1 시스템 타이머 초기화
시스템 타이머 칩은 일정 주기로 clock이 발생한다. 리눅스는 이것을 이용하여 시스템 프
로그래머가 10ms(=100HZ)마다 타이머 인터럽트가 일어나도록 프로그램 할 수 있다. 시스
템 타이머칩이 1.1932MHZ주기로 clock이 발생하면 11932개의 clock이 발생할 때마다
pulse가 일어나도록 하는 것이다. Pulse가 일어 날 때마다 타이머 인터럽트 핸들러가 수행
되도록 한다.
3.2 시간과 관련된 구조체들
<include/linux/time.h> <include/kernel/sched.h>
위의 구조체는 1970년 1월 1일 0시 0분 0초을 기준으로 지금까지 흐른 시간을 갖는다. 처음 리눅스가 부팅하는 과정에서 start_kernel() <main.c> 루틴에서 time_init()이 호출된다. time_init()은 CMOS RAM으로부터 현재 시각을 가져와 xtime에 저장한다.
이후에는 bottom half에서 timer_bh 루틴 안에 있는 update_times()에 의해 변화되어진다.
프로세스의 task_struct 구조체에는 tms구조체인 times 엔트리가 있다. 이것 역시 bottom half의 timer_bh 루틴 안에 있는 update_times()를 통해 변화된다5.
3.2 타이머 인터럽트 핸들러
타이머 인터럽트는 10ms(1/100초) 마다 발생한다고 했다. 이것은 다음과 같은 핸들러를 가지고 있다. 타이머 인터럽트가 발생하면 위의 그림과 같이 수행된다. 리눅스 부팅때 CMOS RAM에서 시간을 읽어와 xtime에 저장한다고 했다. 그후 xtime은 11분 마다 CMOS 시각과 동기화가 이루어 진다. 이 동기화가 do_timer_interrupt()
함수에서 이루어진다. do_timer() 함수에서는 mark_bh() 함수를 통해 timer bottom half와 tqueue bottom half를 기회가 있을 때 실행되도록 bh_active의 해당 비트를 1 로 set한다.6 그럼으로써 schedule() 함수에서 실행 될수 있는 기회가 생긴다7.
스케줄링
4.1 스케줄링 초기화
리눅스 시스템의 부팅시에 start_kernel <main.c> 루틴에서 sched_init() <sched.c> 을 호출한다. 여기서 스케줄링의 초기화가 일어난다.
task table의 각 slot은 하나의 프로세스를 포인터한다. 이 task 테이블의 크기는 NR_TASKS 값에 의해 결정된다. 여기서 NR_TASK 는 동시에 최대로 가질 수 있는 프로세스 수가 된다. 이 값은 필요에 따라 바꾸어 주어도 된다. init_task는 INIT_TASK9로 초기화 된다. init_task는 system에서 수행중인 프로세스가 없을 때 수행된다. 이때 수행되는 것이 idle task 이다 .
task[0]를 제외한 모든 slot를 그림 4-1과 같이 초기화 한다. tarray_freelist는 이 리스트의 header가 된다. 프로세스 해쉬테이블을 아래와 같이 초기화 한다.
위와 같이 해쉬테이블은 NR_TASKS 값을 4로 나눈 것 만큼의 크기를 갖으므로 모든 slot이 NULL로 초기화 된다. 참고로 프로세스 식별자는 최대값을 0x8000까지 갖을 수있다.
인터럽트가 발생한 직후에 모든 함수가 즉시 실행되어야 하는 것은 아니다. 중요한 행동은 즉시 행해져야 하지만 그렇지 않은 경우에는 나중에 실행 될 수도 있다. 이것이 bottom half 이다.
bottom half는 32개로 예약되어 있다.10
bh_base10-1는 함수 포인터 벡터이다. bh_mark는 4byte long 타입으로 해당비트를 mask 하게 되어 있다. bh_active도 4byte long 타입으로 모든 비트는 0으로 초기화 되며, 이것은 인터럽트가 일어났을 때 mark_bh 함수에 의해 해당 비트가 1로 set 되어 진다. 그럼으로써 schedule()함수에서 check되어 해당 bottom half가 실행될 수 있다.
4.2 스케줄 정책
스케줄러는 CPU를 할당 받아 실행될 프로세스를 결정하는 kernel의 함수이다. 이 함수가 schedule()함수이다. 리눅스 스케줄링 정책은 3 가지가 있다. 일반 프로세스를 위한 것 한가지와 실시간 프로세스를 위한 두가지가 있다. 정책은 TASK_RUNNING 상태에 있는 프로세스의 타입에 따라 변한다.
SCHED_FIFO : 이 type은 프로세스가 실행준비상태에 있다면 이 프로세스는 스케줄러로부터 가장 높은 우선순위를 받고 즉시 실행된다.
SCHED_RR : SCHED_FIFO와 같이 즉시 실행될 수 있으며 차이점은 time slice를 가지고 있다는 것이다. 그래서 time slice를 다 쓰고 난 후에는 run queue의 맨뒤로 링크되어진다. 그러므로 run queue에 실시간 프로세스가 있고 그 프로세스와 우선 순위가 같더라도 선점(preemption)될 수 있다.
SCHED_OTHER : 일반 프로세스이다. 실행준비 중인 프로세스 중 실시간 프로세스가 없을 때만이 실행 될 수 있다.
4.3 스케줄러 함수
스케줄링을 담당하는 schedule() 함수는 대표적으로 다음의 경우에 호출되어진다. 첫째는 현재 프로세스의 상태가 TASK_UNINTERRUPTIBLE11 되어지고 wait 큐에 등록되어질 때 sleep_on()함수가 호출된다. 이 sleep_on() 함수에서 schedule() 함수가 호출된다. 둘째는 타이머 인터럽트 핸들러와 같은 종류의 인터럽트나 모든 system call 후에는 ret_from_sys_call 루틴이 실행된다.여기서 need_resched12 flag를 검사하여 1 값을 가지고 있다면 schedule() 함수를 호출한다.
그러므로 타이머 인터럽트 핸들러가 10ms마다 행해지고 현재 프로세스가 자신의 time slice를 다 소모했을 경우 need_resched가 1로 set 되어진다13. 따라서 schedule() 함수는 정기적으로 호출될 수 있다.
Schedule()함수는 크게 3부분으로 나눌 수 있다. 첫 부분은 스케줄링을 위한 예비작업 부분이다. 두번째는 가장 높은 우선 순위를 갖는 프로세스를 찾아내는 부분이다. 셋재는 필요하다면 context_switch가 일어나는 부분이다.
task 큐에 실행될 routine 이 있는지 확인하고, 만일 있다면 처리한다. 4.1절에서 보았듯이 bottom half의 직접적인 사용은 제한되어 있고 이미 다수가 고정 할당되어 있다. 그래서 최근 리눅스에서는 bottom half의 개념을 링크 리스트로 확장하게 되었다. 이것이 바로 task queue 이다.
아래 그림에서 run_task_queue()함수bottom half handler 라고 할 수 있다. 이 함수는 리스트의 헤더를 null 로 만들고 큐에 링크된 routine 들을 처리한다.
next |
sync |
|
*data |
Next |
Sync |
|
*data |
(2) bottom half 실행
bh_mark와 bh_active를 스켄하여 active한 bottom
half가 있으면 do_bottom_half()함수가 호출된다.
do_bottom_half()에서는 active한 bottom half를 처리
하고 bh_active의 모든 비트를 0으로 clear 한다.
(3) SCHED_RR 정책
현재 프로세스가 SCHED_RR 클래스에 속할때의 알고리즘이다. 만약 time slicer를 다 소모했을 경우 다시 time slice를 부여 받고 run queue의 맨 마지막에 링크 시킨다. init task가 run queue의 첫번째가 된다. 하지만 time slice가 남아 있다면 run queue의 위치 이동은 없다.
현재 프로세스가 인터럽트 되었다가 signal를 받았을 경우14, 프로세스 상태는 TASK_RUNNING 상태로 만들고 run queue에는 변화는 없다. 그렇지 않은 경우, run queue에서 현재 프로세스를 제거한다.
다음으로 need_resched 값을 0 으로 off 시킨다.
4.3.2 최고 우선 순위 프로세스 결정
있는 프로세스후보들은 run queue에 있는
프로세스들이다.
그러나 init_task 는 run queue에
첫번째 위치에 있더라도 여기서는 후보가
될 수 없다. 변수 c 값은 후보 프로세스
들의 우선 순위 값을 계산하는 과정에서
가장 높은 값이 저장되는 임시 변수이다.
next는 c 값의 우선 순위를 갖는 프로세
스의 task_struct를 포인트 한다.
다음으로 현재 프로세스의 상태가
TASK_RUNNING 상태이면 현재 프로세
스의 우선 순위 값을 계산하여 변수 c 에 저장 한다. 포인터 next는 현재 프로세스의 task_struct를 포인터한다.
높은 프로세스를 찾는 작업을 한다. SMP 인 경우
run queue에 있는 프로세스들 중에는 다른 CPU에
서 실행 중인 것이 있을 수 있다. 이런 프로세스는
후보의 자격이 없으므로 제외한다.15
후보 프로세스의 우선 순위를 계산하는 함수는
goodness()이다. 이 함수는 후보 프로세스의 policy
와 counter (time slice)를 고려하며 우선 순위 값을
결정하여 준다.16
goodness()에서 리턴되어 온 값이 변수 c 값 보다
크다면 변수 c 값을 update하고 next는 해당 프로세
스를 포인트 한다.
Loop를 돌면서 run queue 에 있는 모든 프로세
스를 검색하게 되면 c 값과 next는 가장 높은 우선
순위 값과 해당 프로세스를 포인트 할 수 있다
여기서 최종적으로 저장된 c 값은 크게 네가지
경우의 값들이 될 수 있다.
이것은 run queue에 실시간 프로세스도 없고 time slice가 남은 프로세스도 없다는 것을
의미한다. 이런 경우 스케줄러는 run queue에 있는 프로세스들을 각자의 priority 값으로
counter 값을 초기화한다. 그리고 나서 다시 한번 4.3.2절의 앞 부분부터 수행한다.
두번째, 저장된 c 값이 –1000 인 경우가 있다.
이것은 run queue에 init_task를 제외하고 어떤
프로세스도 없다는 것을 의미한다. 이런 경우는
스케줄러로부터 CPU를 할당 받아 실행하게 된다.
그러나 init_task는 need_resched를 1 로 set하고
다음 인터럽트 핸들러에 의해 schedule() 함수가
호출 되기를 기다린다. 이런식으로 init_task는 run
queue에 새로운 프로세스가 생길 때까지 시스템
운휴 시간을 사용하게 된다.
세번째. 저장된 C 값이 0보다 크고 1000보다
작은 경우이다. 이것은 run queue에는 실시간
프로세스는 없고 일반 프로세스만 있다는 것을
의미한다. 이런 경우 스케줄러는 next가 포인트하는
프로세스와 현재 프로세스가 같은 프로세스인지
확인한다. 같은 프로세스이면 context_switch
없이 스케줄링을 끝낸다. 같은 프로세스가 아니면
context_switch를 해주고 끝낸다.
네번째, 저장된 c 값이 1000 보다 크다 큰 경우이다.
이것은 next가 포인트하는 프로세스가 실시간 프로세스라는
것을 의미한다. 이후 과정은 세번째 경우와 같다.
이상으로 스케줄링의 설명을 마친다. fork system call
에 대한 설명은 여기서 빠져있다. 이것은 기회가
있을 때 설명 될 것이다. Fork system call 에서는
새로운 프로세스(자식프로세스)의 생성를 보여준다.
이것은 쓰레드 개념과 clone 개념 등을 공부
하는데 도움이 되리라 생각된다. 또한 프로세스 관리
에 중요한 부분들을 많이 포함하고 있다.
Source 함수는 다음과 같다. sys_fork<arch/i386/
kernel/process.c> -à do_fork<kernel/fork.c>이다.
3부 Linux Memory Management
1. Protected mode와 segmentation
Protected mode란 Linux같은 multi-tasking system에서 한 task(or process)의
memory가 다른 task의 접근으로부터 보호되는 모드를 말하고 i386 CPU는 이런 보호모드을 지원하기 위해 segmentation hardware와 paging unit을 제공한다.
1-1. Segmentation
Operation system은 memory segment의 특성을 기술하는 segment descriptor table(GDT,LDT,IDT)을 memory에 유지하는데 각각의 process는 segment register(selector)을 통해서 GDT(or LDT)에 있는 segment descriptor을 참조하고 이 정보을 이용해서 memory segment에 접근한다.(그림1) Segment register CS, DS, ES, SS, FS, GS가 있고 selector의 format는 그림 2와 같다.
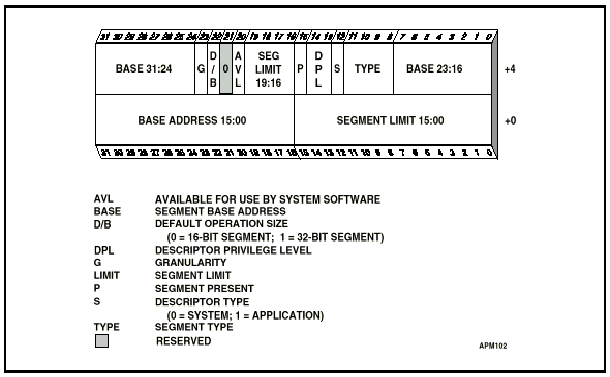
<그림 1. segment descriptor>
 <그림 2. segment register(selecor)>
<그림 2. segment register(selecor)>
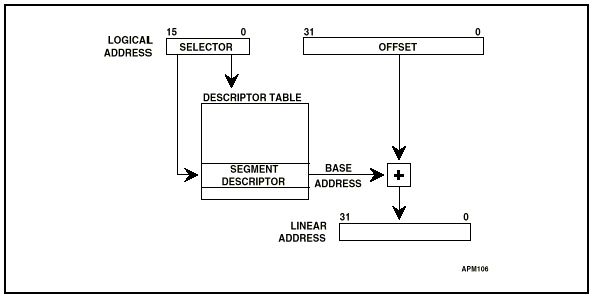
<그림 3. Segmentation에 의한 address 변환>
Segment란 'memory 한 조각'이란 의미로 process가 실행되기 위해서는 code, data, heap, stack segment가 필요하다. code segment에서 instructions을 read하고, data segment에 변수값을 read/write하며, stack는 임시변수와 function call시 return address을 저장하는데 사용된다. Segmentation 기능을 이용해서 하나의 process내에서 code, data, stack segment을 독립적으로 지정 가능하고 또한 task 마다 각각 다른 memory segment을 가지도록 기술하여 각각의 segment을 보호 할 수 있다.(그림 3 참조)
1-2 kernel space와 user space
i386 CPU에는 ring 0,1,2,3라는 4가지 특권 레벨(privilege level)이 있다.
CPU는 한 순간에 4개 level중 어느 한 level에서 실행하게 되는데 실제로
Linux(Windows도 동일)는 ring 0와 ring 3만 사용한다.
CPU가 ring 0에서 실행될 때 'kernel mode에 있다' 혹은 'kernel space에서 실행되고 있다'라고 하고 ring 3에서 실행될 때 'user mode에 있다' 혹은 'user space에서 실행되고 있다' 라고 말한다.
<그림 4. segment descriptor of GDT in Linux>
i386 CPU는 32bit addressing을 하므로 0 - 4GB의 address space을 가진다.
Linux의 경우 user space로 0 - 3GB(0xC0000000)을 사용하고 kernel space로
3GB(0xC0000000) - 4GB(0xFFFFFFFF)을 사용한다. kernel 2.1.8부터는 kernel mode에서 user space을 access하는 timing을 줄이기 위해 user, kernel space 모두 0 - 4GB을 사용하고 있다. 여기서는 2.1.8 이전을 기준으로 설명한다.
1-3 Linux에서 segmentation 구현 : Flat memory model
Linux는 segmentation보다는 paging에 기초한 가상 memory 관리을 한다. Linux의 경우 segment base을 0로 segment limit을 0xC0000000로 설정하여
32bit offset만으로 memory에 접근하는 flat memory model을 사용한다.
이런 flat memory model에서는 virtual address와 linear address가 같아서
마치 segmentation 자체가 없는 것처럼 느껴진다.
<list 1. arch/i386/kernel/head.S>
movl $0x101000,%eax
movl %eax,%cr3/* set the page directory to swapper_pg_dir */
movl %cr0,%eax
orl $0x80000000,%eax
movl %eax,%cr0/* ..and set paging (PG) bit */
lgdt gdt_descr/* load gdtr register */
lidt idt_descr/* load ldtr */
ljmp $(__KERNEL_CS),$1f
1:movl $(__KERNEL_DS),%eax# reload all the segment registers
movl %ax,%ds# after changing gdt.
movl %ax,%es
movl %ax,%fs
movl %ax,%gs
lss stack_start,%esp# load processor stack
call SYMBOL_NAME(start_kernel)
.word 0
gdt_descr:
.word (8+2*NR_TASKS)*8-1
SYMBOL_NAME(gdt):
.long SYMBOL_NAME(gdt_table)
.org 0x1000
ENTRY(swapper_pg_dir)
.long 0x00102007
.fill __USER_PGD_PTRS-1,4,0/* default: 767 entries */
.long 0x00102007
.fill __KERNEL_PGD_PTRS-1,4,0/* default: 255 entries */
.org 0x2000
ENTRY(pg0)
.long 0x000007,0x001007,0x002007,0x003007,0x004007,0x005007…..
……….
ENTRY(gdt_table)
.quad 0x0000000000000000/* NULL descriptor */
.quad 0x0000000000000000/* not used */
.quad 0xc0c39a000000ffff/* 0x10 kernel 1GB code at 0xC0000000 */
.quad 0xc0c392000000ffff/* 0x18 kernel 1GB data at 0xC0000000 */
.quad 0x00cbfa000000ffff/* 0x23 user 3GB code at 0x00000000 */
.quad 0x00cbf2000000ffff/* 0x2b user 3GB data at 0x00000000 */
.quad 0x0000000000000000/* not used */
.quad 0x0000000000000000/* not used */
.fill 2*NR_TASKS,8,0/* space for LDT's and TSS's etc */
위의 code는 head.S에 있는 것으로 기본적인 segmentation과 paging을 설정하는 부분이다. Page directory table인 swapper_pg_dir의 address을 conrrol register CR3에 설정하고 CR0의 PG bit을 set하여 paging을 enable한다.
Lgdt gdt_desc명령에 의해 GDTR register에는 gdt table의 "size(GDT_ENTRY)+base address(gdt_table)"가 들어가므로 GDTR는 gdt_table을 가리키게 된다. GDTR을 초기화하여 segmentation이 가능하게 되고 swapper_pg_dir과 pg0을 초기화하여 paging이 가능하게 된다.
여기서 중요한 것은 swapper_pg_dir의 2개 entry만(entry 0와 entry 768) 0x00102007로 설정하고 나머지는 모두 zero이다. 0x00102007을 해석해 보면 base address 0x00102000에 있는 pg0 page table의 있다는 의미이고 그 속성은 page size는 4KB단위, user page, R/W가능, present page등 이다.(그림. 7 참조)
즉 head.S에서는 초기 4M physical memory에 대한 page directory 및 page table을 설정하고 그 결과는 그림 5과 같다.
<그림 5. paging_init()에 의한 linear-physical address mapping>
2. Paging
Linux는 paging에 기초한 virtual memory을 제공한다. Virtual address을 사용함으로써 process는 실제 physical memory보다 더 많은 memory가 있는 것처럼 생각하고 실행 할 수 있다. CPU내부에서 사용하는 하나의 logical address가 physical memory을 access하기 위해서는 그림 6과 같이 3단계의 address 변환이 일어난다.
Logical address가 segmentation에 의해 32 bit linear address변환되고, 이 linear address는 paging unit에 의해 physical address로 변환되어 CPU의
address pin으로 나오게 된다.
<그림 6. logical, linear, physical address 변환>
paging이 동작되기 위해서는 page directory table과 page table을 구성해 주어야 한다. Linear address의 상위 10bit는 page directory을 찾는데 사용되고, 그 다음 10bit는 page table entry을 찾아가고 page table에서 구한 physical page base address에 나머지 12bit offset을 더하여 phsical address을 계산한다.(그림7 참조)
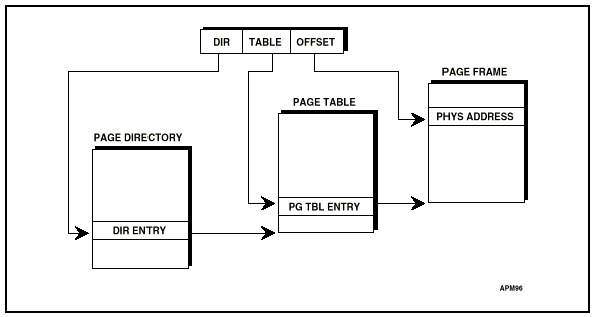
<그림 7. paging에 의한 linear address 변환>
i386 Linux의 memory management는 copy-on-write와 demand paging을 사용한다. Demand paging이란 처음부터(fork, exec할 때) physical memory을 할당하는 것이 아니라 실제로 그 page을 access할 때 physical memory을 할당하는 것을 말한다.
fork()할 때 parent와 child process는 code, data, stack등 모든 virtual address공간을 공유한다. 이후 어느 한 process가 write을 할 때 physical memory을 할당하고 copy한다.(copy-on-write).
모든 process는 fork()할 때 parent로 부터 page directory와 page table을 상속 받고, 각각의 process는 자신만의 page directory을 가지고 4G의 linear space에서 실행된다. 하나의 page directory(4KB size)는 1024개의 page table을 가지고 하나의 page table(4KB size)는 1024개의 physical page을 가질 수 있다. 그래서 하나의 page directory에 의해 접근 할 수 있는 최대 linear address는
1024/page-directory*1024/page-table*4KB page = 4GB가 된다.
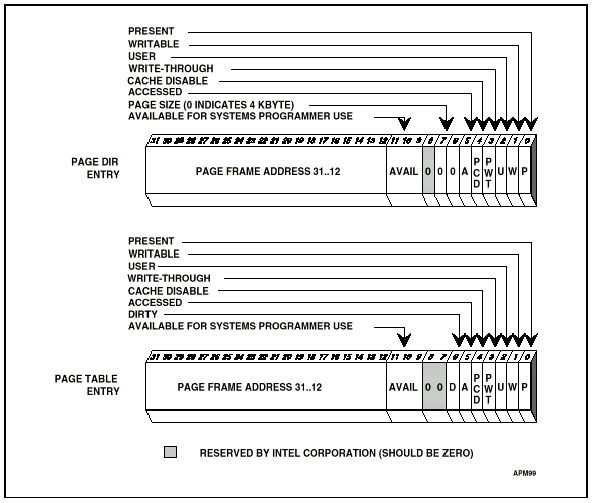
<그림 8. Page directory, page table entry format>
<list 2. paging_init()>
start_mem = PAGE_ALIGN(start_mem);
address = PAGE_OFFSET;/* 0xC0000000 */
pg_dir = swapper_pg_dir;
pgd_val(pg_dir[0]) = 0;/* unmap the original low memory mappings */
pg_dir += USER_PGD_PTRS;/* 768 entry부터 mapping한다 */
while (address < end_mem) {/* Map whole memory from PAGE_OFFSET */
/* pg_table is physical at this point */
pg_table = (pte_t *) (PAGE_MASK & pgd_val(*pg_dir));
if (!pg_table) {
pg_table = (pte_t *) __pa(start_mem);
start_mem += PAGE_SIZE;
}
pgd_val(*pg_dir) = _PAGE_TABLE | (unsigned long) pg_table;
pg_dir++;
pg_table = (pte_t *) __va(pg_table); /* change pg_table to kernel virtual addresse*/
for (tmp = 0 ; tmp < PTRS_PER_PTE ; tmp++,pg_table++) {
pte_t pte = mk_pte(address, PAGE_KERNEL);
if (address >= end_mem)
pte_val(pte) = 0;
set_pte(pg_table, pte);
address += PAGE_SIZE;
}
}
paging_init()는 모든 memory에 대한 page directory와 page table을 초기화 하는 함수이다. Kerenl 영역 0xC0000000에 대해서만 설정한다.
head.S에서 low 4M에 mapping한 pg_dir[0]을 zero로 reset하여 kernel mode에서는 0xC0000000 위쪽 영역을 통해서만 접근하게 한다.
pg_dir entry가 null인 경우 start_mem에서 1개 page table을 할당한 다음 page directory에 설정하고 page table의 모든 entry에(1024개) address을 PAGE_OFFSET(4KB) 만큼 증가 시키면서 초기화한다.
4. Memory 초기화와 free memory 관리
4-1 memory_start, memory_end 초기화
__initfunc(void setup_arch(char **cmdline_p,
{unsigned long * memory_start_p, unsigned long * memory_end_p))
memory_end = (1<<20) + (EXT_MEM_K<<10);
memory_end &= PAGE_MASK;
memory_start = (unsigned long) &_end;
memory_end += PAGE_OFFSET;
*memory_start_p = memory_start;
*memory_end_p = memory_end;
}
EXT_MEM_K는 empty_zero_page[2]을 pointing하고 있고, 여기에는 boot/setup.S에서 check한 high memory크기가 들어있는데 이 값에 page align한 다음, 0xC0000000을 더한 값이 memory_end가 된다. (head.S에서 boot parameter와 command line option을 empty_zero_page에 copy해 둔다)
Memory_start는 kernel image의 bss의 끝인 _end값으로 초기화 되는 것을 알수 있다.
4-2 free_area 초기화
unsigned long __init free_area_init(unsigned long start_mem, unsigned long end_mem)
{
mem_map = (mem_map_t *) LONG_ALIGN(start_mem);
p = mem_map + MAP_NR(end_mem);
start_mem = LONG_ALIGN((unsigned long) p);
memset(mem_map, 0, start_mem - (unsigned long) mem_map);
do {
--p;
atomic_set(&p->count, 0);
p->flags = (1 << PG_DMA) | (1 << PG_reserved);
} while (p > mem_map);
for (i = 0 ; i < NR_MEM_LISTS ; i++) {
unsigned long bitmap_size;
init_mem_queue(free_area+i);
/* 중략 */
bitmap_size = LONG_ALIGN(bitmap_size);
free_area[i].map = (unsigned int *) start_mem;
start_mem += bitmap_size;
}
return start_mem;
}
먼저 start_mem위치에 mem_map_t 구조체을 MAP_NR(end_mem) 수 만큼 만들고 end_mem부터 전체 memory에 대해 각각의 physical page에 해당하는 mem_map_t 구조체을 초기화한다.(do while loop)
여기에서 mem_map_t 구조체는 각 physical page에 대한 정보을 가지고 있는 구조체이고, MAP_NR는 physical memory의 page수을 구하는 macro이다.
일단은 모든 memory에 대해 count=zero, PG_reserved로 초기화한다.
아래부분은 free page을 관리하는 free_area[10] 배열과 memory bitmap을 초기화한다.
4-3 mem_init()
__initfunc(void mem_init(unsigned long start_mem, unsigned long end_mem))
{
while (start_mem < end_mem) {
clear_bit(PG_reserved, &mem_map[MAP_NR(start_mem)].flags);
start_mem += PAGE_SIZE;
}
for (tmp = PAGE_OFFSET ; tmp < end_mem ; tmp += PAGE_SIZE) {
if (PageReserved(mem_map+MAP_NR(tmp))) {
if (tmp >= (unsigned long) &_text && tmp < (unsigned long) &_edata) {
if (tmp < (unsigned long) &_etext)
codepages++;
else
datapages++;
} else if (tmp >= (unsigned long) &__init_begin
&& tmp < (unsigned long) &__init_end)
initpages++;
else if (tmp >= (unsigned long) &__bss_start
&& tmp < (unsigned long) start_mem)
datapages++;
else
reservedpages++;
continue;
}
atomic_set(&mem_map[MAP_NR(tmp)].count, 1);
free_page(tmp);
}
먼저 현재의 start_mem에서 end_mem까지 모든 page에 대해 PG_reserevd을 clear한다. 그 다음 모든 physical memory에(PAGE_OFFSET - end_mem까지) 대해서 PG_reserved인 경우 code page, init page, data page, reserved page중 하나를 count하고, 그 결과는 booting message로 출력된다. Reserved page는 kernel에 속한 memory로 free되지도 않고, swap되지도 않는다.
free인 경우는 count을 1로 set하고 free_page()함수을 call한다. free_page()함수는 free page을 free_area[] 배열에 추가하고 size별로 list를 만든다.
후에 kmallloc()등으로 memory할당을 요구하는 경우에 여기서 초기화한 free_area[] 배열에서 할당하고, kfree() 함수로 free하는 경우 다시 free_area[] 배열에 반납하는 방식으로 free memory를 관리한다. (kerenl 2.1.38이후는 slab allocator을 사용한다)
<그림 9. kernel 직후 memory map>
5. User process의 virtual address space
User process는 fork()시 자기만의 page directory을 가지고 4G virtual address공간에서 실행된다고 앞에서 언급했다.
또 exec()에 의해 user process의 virtual address공간에 executable binary file을 do_mmap()함수에 의해 mapping한다. 그림 10는 ELF object인 경우이다.
User process의 linear memory는 vm_area_struct라는 구조체에 의해 관리된다.
모든 user process는 exec()할때 binary file의 header에 있는 정보를 읽어서 binary file이 실행하는데 필요한 가상memory을 binary file에 단지 mapping한다. 이때 physical memory를 할당하지는 않는다.
Binary header에 있는 하나의 area에(code, data..) 대해 한 개의 vm_area_struct가 할당되고, 같은 process에 속한 모든 vm_area_struct는 list로 연결된다.
struct vm_area_struct {
unsigned long vm_start;
unsigned long vm_end;
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot;
unsigned short vm_flags;
struct vm_operations_struct * vm_ops;
unsigned long vm_offset;
struct file * vm_file;
};
User process의 vm_area list는 /proc/pid/maps에서 볼수 있고 cat명령으로 init process를 출력 해보면 아래와 같은 결과를 얻는다.
$cat /proc/1/maps
08048000-0804e000 r-xp 00000000 03:02 6224 # /sbin/init -- code
0804e000-0804f000 rw-p 00005000 03:02 6224 # /sbin/init -- data
0804f000-08053000 rwxp 00000000 00:00 0# ananoymous mapped bss
40000000-40012000 r-xp 00000000 03:02 4058 # /lib/ld-2.1.1.so -- code
40012000-40013000 rw-p 00011000 03:02 4058# /lib/ld-2.1.1.so -- data
40013000-40014000 rwxp 00000000 00:00 0#
bfffe000-c0000000 rwxp fffff000 00:00 0# anonymous mapped stack
각 fields의 의미는 start-end permission offset major:minor inode이다.
위의 결과에서 init process가 실행될때 code, data, bss, stack, shared library의 area가 mapping되는 linear address공간을 알수 있다. inode가 NULL인 상태로 mapping하는 것을 anonymous mapping이라 하고 이 경우에는 vm_ops, vm_offset, vm_file이 NULL로 설정된다.
위 출력의 한 개 line(area)는 한 개의 vm_area_struct로 mapping되는데 그 것을 그림으로 표현한 것이 그림10이다
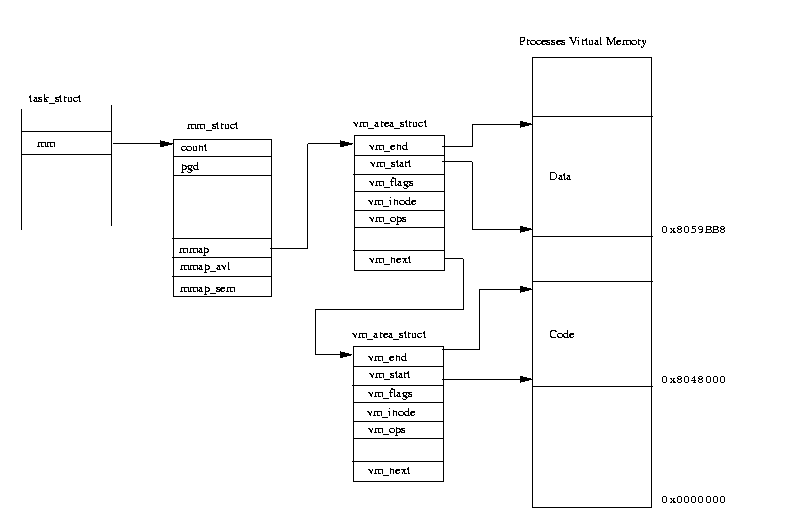
<그림 10. User process linear address mapping>
7. Page fault
Program실행 중 program의 정상적인 실행 경로을 벗어나는 것을 exception이라 하고 다음과 같은 종류가 있다.
Exception 종류 :
1. System call: programmer
2. Interrupt: external I/O device
3. Fault(trap): CPU 자신
Process가 access하려는 linear address에 physical page가 할당되어 있지 않거나 access할려는 process의 privilege level이 낮아서 access할 수 없는 경우에 exception 14인 page fault가 발생한다.
 <그림 11. Page fault 발생시 error
code>
<그림 11. Page fault 발생시 error
code>
Page fault을 처리하는 일반적인 순서는 다음과 같다.
page directory entry가 있는지 없는지 조사하고, 없으면 새로운 page table을 할당한 다음 page directory entry에 설정하고 handle_pte_fault()를 호출한다.
falut가 일어난 그 원인이
if (!pte_present(entry)) {
if (pte_none(entry))
return do_no_page(tsk, vma, address, write_access, pte);
return do_swap_page(tsk, vma, address, pte, entry, write_access);
}
if (write_access) {
if (!pte_write(entry))
return do_wp_page(tsk, vma, address, pte);
}
새로운 page을 하나 할당하고 page table entry를 update한다.
copy-on-write에 의해 falut가 일어난 경우로 새로운 page(new_page)를 할당하고 원래의 page(old_page)을 복사한 다음 old_page의 map count을 1 감소시킨다. 만약 map count가 1이면 copy하지 않고 쓰기 가능하게 고친 다음 return한다.
swap area에서 memory로 해당 page을 load한다.
8. Kernel mode에서 user space access
Linux는 오랫동안 kernel mode에서 user space을 access하기 위해서 fs register을 사용해 왔으나 2.1.8에서 관련 code가 대폭 변경되었다. 여기서는 2.1.8 이전의 경우에 대해서 설명한다.
Interrupt나 system call등에 의해 user mode에서 kernel mode로 진입하면 현재 user process의 context을 save하기 위해 arch/i386/kernel/entry.S에 있는 SAVE_ALL macro을 실행하고, 반대로 user mode로 복귀할때 RESTORE_ALL macro를 실행한다.
SAVE_ALL code을 보면 ds, es는 KERNEL_DS(0x18)로 설정하지만 fs register는 USER_DS(0x2B)로 설정하는 것을 볼수 있다. 즉 kernel mode에서도 fs register는 user space을 기리키게 된다.
User space를 access하는 함수로는 get_user(), put_user(), memcpy_tofs(), memcpy_fromfs()등이 있는데, 여기의 memcpy_to/from에 fs가 붙은 그 유래가 fs register을 사용하기 때문이다.
include/asm/segment.h에 define되어 있는 get_user_long()함수을 보면 fs segment에서 offset addr에 있는 long value을 읽어온다.
즉 kernel segment가 아니라 user space에 있는 addr에 읽어온다.
static inline unsigned long get_user_long(const int *addr)
{unsigned long _v;
__asm__ ("movl %%fs:%1,%0"
:"=r" (_v)
:"m" (*addr)); \
return _v;
}
4부 리눅스 파일시스템(VFS)
1. 서론
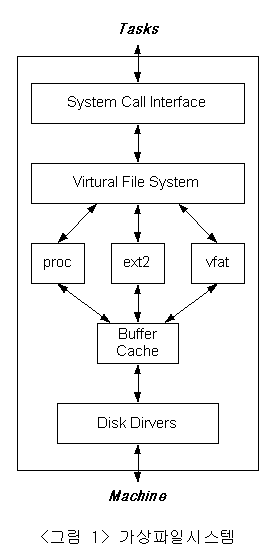
리눅스의 파일시스템은 특정 회사에 귀속되지 않고, 불특정 다수에 의해서 개발되어지고 있기 때문에 이질적인 요소들을 포용할 수 있는 개방성을 갖고 있다. 즉 다른 운영체제들의 파일시스템을 포함한 여러 파일시스템을 운용할 수 있도록 가상파일시스템(Virtual File System)으로 설계되어져 있다. 또한 이 개방성은 시스템내에 존재하는 대부분의 디바이스들을 포용할 수 있다. 이 VFS의 역할은 리눅스의 파일에 대한 시스템 호출이 이질적인 파일시스템들의 물리적 포맷에 구애받지 않도록 공통의 인터페이스를 제공하고, 이를 통한 파일처리에 최상의 성능을 발휘할 수 있도록 하는데 있다. <그림 1>은 VFS와 파일시스템간의 관계성을 표현하고 있다.
2. 전체 구성도
가상파일시스템의 역할은 지원되어지는 파일시스템들을 커널에 마운트하여 프로세스들이 각 파일시스템에 존재하는 파일에 대해 공통적인 접근을 가능하게 하는 것이다. 이를 위하여 가상파일시스템은 파일시스템을 마운트하여 관리하는 마운팅 부분, 디바이스상의 파일을 메모리상으로 로드하는 버퍼 부분, 메모리상에 존재하는 객체에 빠른 접근을 위한 캐쉬 부분, 그리고 프로세스로부터 메모리상의 파일에 대한 작업을 입력받는 시스템 호출 부분으로 구성되어져 있다.
이 구분은 파일에 효과적인 접근을 실현하기 위하여 여러 가지의 운용기법들이 적용되어져, 그 역할에 따라 크게 7개의 부분으로 세분화 되어진다.
· 파일시스템들의 mounting 지원과 관리
· 파일시스템의 superblock 관리
· 파일시스템의 계층적 디렉토리 관리
· 객체 표현을 위한 inode 관리
· 오픈 파일관리
· 지정된 디스크 드라이버와 파일을 입출력하기 위한 buffer 관리
· 시스템 호출
다음 그림은 세분화된 VFS 내부의 구성 모듈들을 표현하고 있다.
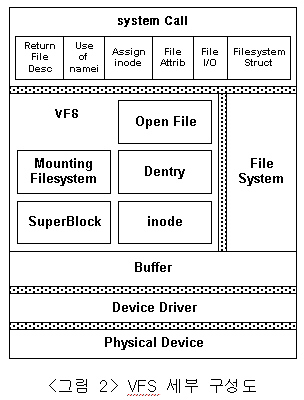
3. 모듈의 역할 및 관리
3.1 마운트
3.1.1 registering
하나의 파일시스템을 마운팅 하고자 할 때, 리눅스는 마운트 하고자 하는 파일시스템에 대한 정보를 요구하게 된다. 이를 위하여 파일시스템 등록작업이 마운팅에 앞서 선행되어진다. 이 등록작업은 각각의 파일시스템에 대한 개략적인 정보와 그 파일시스템의 superblock을 메모리로 로드하기 위한 메쏘드를 구조체 file_system_type에 정의하는 작업이다. 등록된 파일시스템의 정보들은 선형 리스트로 가상파일시스템에 의해서 관리되어지고, 포인터변수 file_systems가 이 리스트의 head를 나타내게 된다. <그림 3>은 가상파일시스템에 의해서 관리되어지는 등록정보들을 나타내고 있다. 단순히 next 필드를 사용하여 선형 리스트를 구성하고 있음을 볼 수 있다.
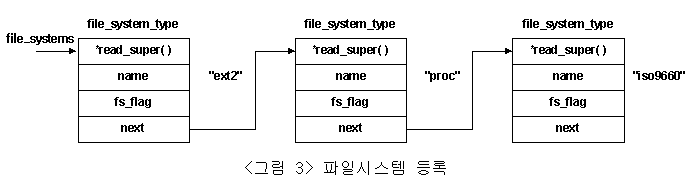
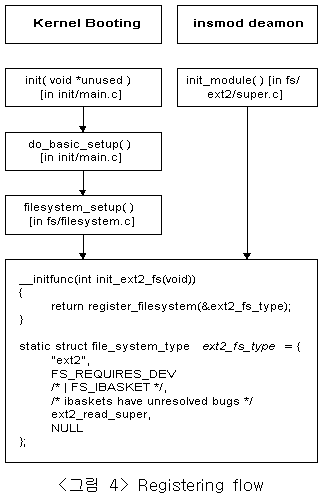
파일시스템의 등록작업은 두 가지의 실행 경로를 갖고 있는데, 그중 하나가 커널이 부팅시 파일시스템을 등록하는 방법이고, 나머지가 데몬(insmod)에 의해서 등록되는 방식이다. 첫 번째 방법은 커널의 초기화 작업시에 미리 정의된 파일시스템을 등록하는 것이고, 두 번째 방법은 특정 파일시스템 마운트시에 그것에 관련된 등록정보가 가상파일시스템내에 없는 경우 실행되어지는 방법이다. 다음 그림은 ext2 파일시스템의 등록정보를 등록하는 과정을 나타내고 있다. 왼쪽의 flow는 kernel booting시 오른쪽 flow는 insmod 데몬에 의해서 호출되어지는 함수를 나타내고 있다. 등록을 위해 실행되어지는 함수 init_ext2_fs()는 가상파일시스템내에 정의되어진 함수 register_filesystem()를 호출하여 등록작업을 수행하게된다. 이 작업에서 ext2 파일시스템내에 미리 정의되어져 있는 등록정보 ext2_fs_type 구조체 변수를 호출 인자로 사용함을 볼수 있다.
3.1.2 mounting
리눅스에서는 여러종류의 파일시스템을 사용할 수 있다. 사용하고자 하는 파일시스템이 다른 OS의 파일시스템일지라도 그것을 할 수 있는 것이다. 대략적으로 읽고 쓰기 작업까지 지원 가능한 파일시스템의 종류는 약 15가지 정도이다. 이 파일시스템을 사용하기 위하여 리눅스에 연결하는 작업을 마운팅 이라고 할 수 있다. 마운트 되어진 파일시스템들은 구조체 변수 vfsmount에 의해서 그 파일시스템의 포괄적인 정보들이 표현되어진다. 즉 파일시스템을 대표할 수 있는 정보들이 포함되어지고, 이들은 다시 세부적인 사항으로 표현되어질 수 있다. 마운트되어진 파일시스템들은 <그림 5>에 표현되어진 것처럼 선형 리스트로 관리되어지고, 포인터 변수 vfsmntlist가 이 선형 리스트의 head를 나타내게 된다. 이 리스트를 통하여 리눅스는 마운트 되어진 파일시스템의 superblock과 device에 대한 정보를 얻을 수 있을 것이다.
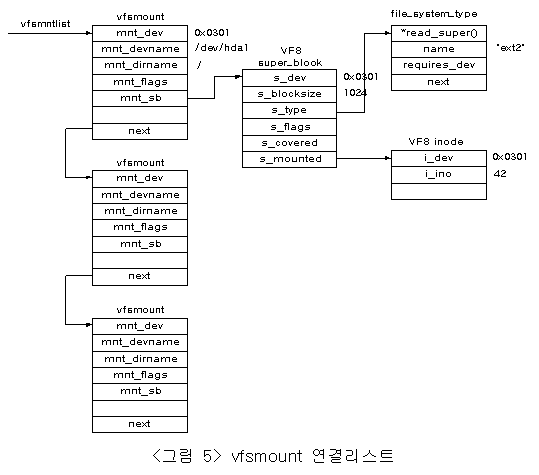
다음 그림은 가상파일시스템에 마운트 되어진 파일시스템을 나타내고 있다. 접점으로 연결된 마운트되어진 파일시스템은 실제적으로 두 개의 디렉토리로 구성되어지지만, 우리는 이것을 하나의 디렉토리로 인식하게된다.
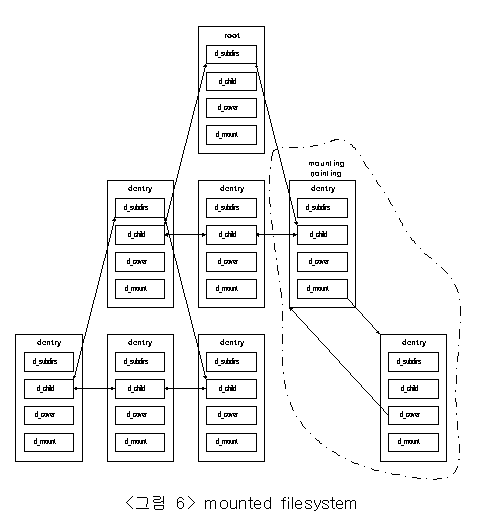
3.2 디렉토리 캐쉬
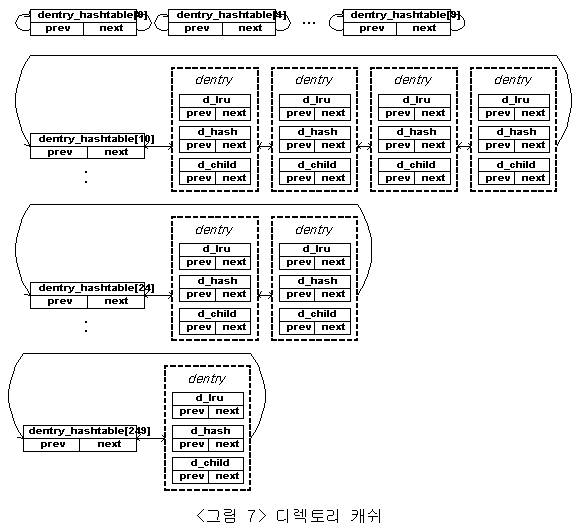
우리가 파일시스템내의 객체를 접근하고자 할 경우 가장 먼저 그 객체의 dentry를 구하여 객체의 위치정보를 얻게 되고, 그 dentry를 통하여 객체의 inode를 얻게된다. 이러한 접근에 대한 속도를 향상시키기 위하여 리눅스에는 dentry cache를 운용하고 있다. 캐쉬는 hash table로써 구현 되어져 있으며, 변수 dentry_hashtable로 나타내어진다. <그림 7>에 표현되어지는 dentry_hashtable의 요소들은 동일한 해쉬값을 가지는 dentry의 선형 리스트의 포인터를 갖게된다.
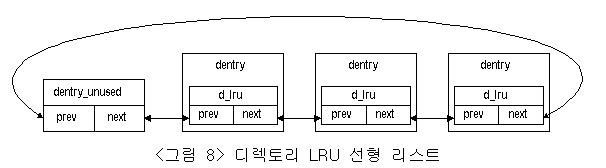
메모리 크기의 한계성으로 인하여, 메모리상으로 무한정 새로운 dentry를 로드할 수는 없다. 따라서 새로운 객체를 메모리로 로드할때는 지금 당장 사용하지 않는 dentry를 해제하고, 그곳에 새로운 dentry를 로드할 수 있어야 한다. 이를 위하여, LRU 알고리듬을 캐쉬와 동시에 운용하고 있다. 해당 dentry에 레퍼런스 횟수가 0인 경우에 구조체 변수 dentry_unused가 head를 가리키는 LRU 선형 리스트로 삽입하여 관리한다. <그림 8>은 dentry_unused에 의해서 연결된 dentry 객체들을 표현하고 있다. 여기에 구성된 객체들은 다른 dentry의 메모리 로드시 기존 설정이 해제되어지고, 새로운 dentry의 설정으로 구성되어진다.
3.3 inode 캐쉬
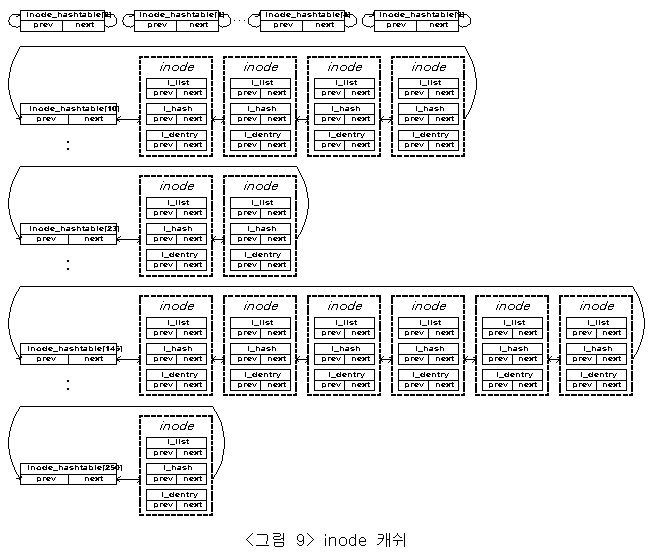
파일시스템내에 존재하는 파일과 디렉토리와 같은 객체들은 가상파일시스템내에서 inode로서 표현되어진다. 각각의 inode는 서로 다른 데이터를 표현하고 있기 때문에 시스템 운용시 상당히 많은 inode들이 메모리상에 존재하게 된다. 가상파일시스템에서는 이 inode들에 효과적으로 접근하기 위하여 디렉토리 캐쉬와 마찬가지로 inode 캐쉬를 사용한다. 이 캐쉬 또한 hash table로 구현되어져 있고, 구조체 변수 inode_hashtable로써 동일한 hash 값을 갖는 inode들의 선형 리스트들을 유지한다. <그림 9>에서 표현되어지고 있는 것 처럼 inode 캐쉬는 디렉토리 캐쉬와 유사한 형태를 갖고 구현되어져 있음을 볼 수 있다.
4.4 buffer 캐쉬
메모리와 디바이스의 처리 속도차이는 크기 때문에 메모리와 디바이스사이의 데이터 이동 속도는 접근속도가 느린 디바이스에 의해서 결정된다. 따라서 두 매체사이의 데이터 이동속도를 향상시키기 위하여 리눅스의 가상파일시스템에서는 완충 역할을 수행하는 buffer를 채용하고 있다. 이러한 목적으로 사용되어지는 buffer는 항상 메모리로부터 일정 영역을 할당받아 디바이스내의 데이터 보관 및 디바이스에 데이터를 저장하는 역할을 수행한다. <그림 10>은 메모리상에 page를 할당받아 이를 크기별로 분활하여 각각을 buffer_head로 관리하는 가상파일시스템의 buffer를 나타내고 있다.
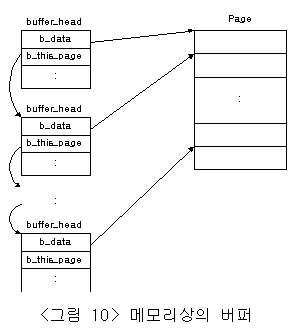
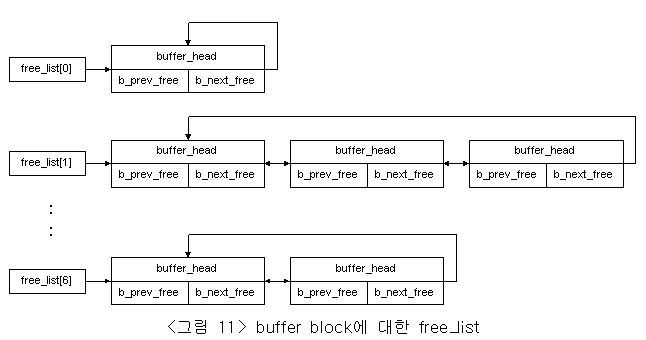
물리적 블록 디바이스에 접근 속도를 향상시키기 위하여, 리눅스에서는 buffer cache를 사용한다. buffer cache는 크게 세 개의 기능적 부분으로 나뉘어진다. 첫 번째 부분은 free block buffer들의 리스트이다. 이것은 <그림 11>에 표현처럼 변수 free_list에 의해서 buffer의 크기별로 구분되어 하나의 Link List로 존재한다. 이 시스템의 free block buffer들은 처음 생성되어질때와 buffer의 사용이 끝났을때, 각각의 크기별로 구분되어 free_list로 입력되어 관리되어진다.
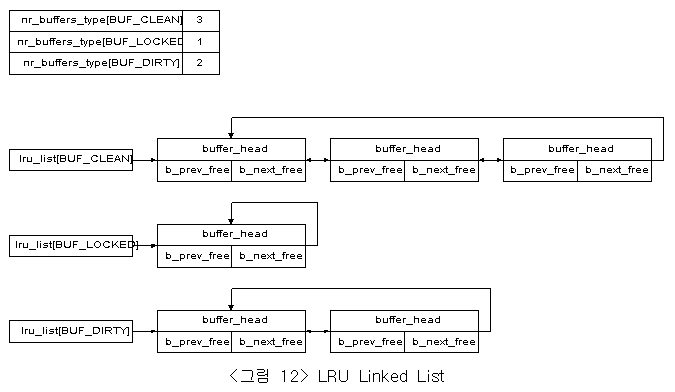
두 번째 기능적 부분은 LRU 선형 리스트 부분이다. 이것은 해당 메모리에서 해제 가능한 buffer block을 선정할 때 사용되어진다. LRU 선형 리스트는 buffer에 존재하는 데이터의 상태에 따라 clean, lock, dirty 3개의 리스트로 나뉘어진다. 이 구분은 구조체 buffer_head의 필드 b_list의 값을 사용하여 이루어 진다. 그리고 3개의 선형 리스트 각각에 연결된 buffer들의 개수는 변수 nr_buffer_type에 의하여 표현되어진다. <그림 12>은 LRU Linked List를 표현하고 있다.
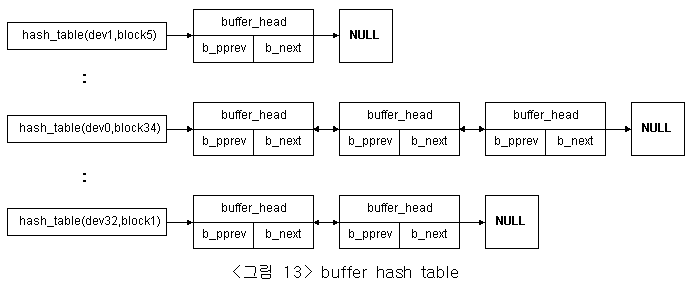
세 번째 기능적 부분은 buffer에 대한 접근 속도를 향상시키기 위한 캐쉬이다. 이것은 동일한 hash값을 갖는 buffer들의 리스트에 대한 포인터를 갖고 있는 hash로 구성되어져 있고 이것은 변수 hash_table에 의해서 유지 되어진다. hash_table의 인덱스로 사용되어지는 hash값은 디바이스 식별자와 블록 번호로 생성되어진다. 이 부분은 디렉토리 캐쉬와 inode 캐쉬와 거의 동일한 형태를 갖고 있다. 단지 이 buffer 캐쉬는 다른 캐쉬와 달리 환형 리스트가 아닌 선형 리스트로 이루어 진다.
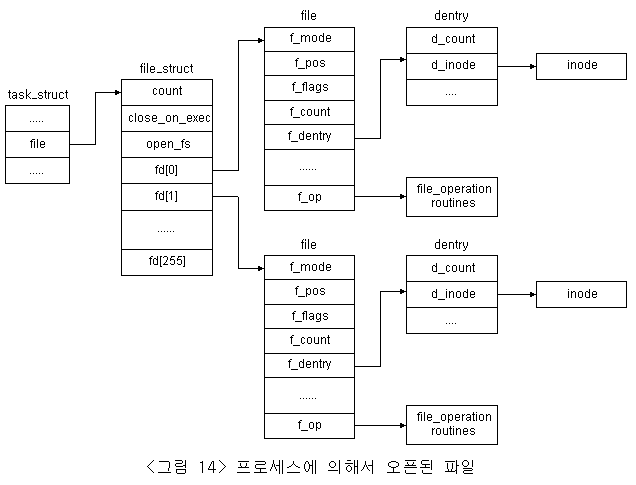
3.5 Open file
현재 작업중인 프로세스에 의해서 파일을 오픈하고자 할 때, 프로세스는 VFS에 시스템 호출을 발생시켜서 파일을 오픈하게 된다. 이 오픈작업을 호출한 프로세스로 그 파일의 descriptor가 반환되어지고, 각각의 프로세스는 자신이 오픈한 파일 descriptor들을 관리하는 테이블에서 이 descriptor들을 관리하게 되며, 이것은 구조체 file_struct로 표현되어진다. <그림 14>는 두 개의 파일을 오픈한 프로세스의 상태를 나타내고 있다.
3.6 system call
파일시스템에 대한 시스템 호출은 <표 1>에 나타난 것처럼 다음과 같은 시스템 호출의 작업의 종류별로 구분 분리되어 커널 소스 파일에 구현되어져 있다. 일반적으로 리눅스 커널 소스에서 존재하는 함수중 함수명이 sys_...로 시작되어지는 함수들이 시스템 호출을 구현한다.
소스 파일 |
시 스 템 호 출 |
buffer.c dquot.c exec.c fcntl.c ioctl.c locks.c namei.c noquot.c open.c read_write.c readdir.c select.c stat.c super.c |
sync, fsync, fdatasync, bdflush quotactl exit, brk, uselib dup2, dup, fcntl ioctl flock mknod, mkdir, rmdir, unlink, symlink, rename quotactl statfs, fstats, truncate, ftruncate, utime, utimes, acces, chdir, fchdir, chroot, fchmod, fchown, open, creat, close, vhangup lseek, llseek, read, write, readv, writev getdents select stat, newstat, lstat, newlstat, fstat, newfstat, readlink sysfs, ustat, umount, mount |
5부 네트워크
우선 main.c에서 kernel_thread(init, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGHAND)를 부르면서 새로운 thread를 create하면서 init()이 불리우게 된다. 이 함수 안의 do_basic_setup()은 sock_init() 을 부르는데 이것이 네트워크 초기화 루틴이다.
이것은 다시 sk_init()과 proto_init()을 부른다. sk_init()은 “sock”이라는 이름으로 sock구조체를 할당 받는것이고 proto_init()은 다시 struct net_proto protocols[]벡터에 저장되어 있는 프로토콜 패밀리 initialization함수들을 루프를 돌며 콜을 해준다. 이때 PF_INET 인덱스에 있는 inet_proto_init()을 호출하게된다.
inet_proto_init()은 sock_register(&inet_family_ops)에서 inet_family_ops의 family인자로 인덱스되는 struct net_proto_family net_familes[] 에 inet_family_ops를 연결시킨다.
그리고 inet_add_protocol()을이용하여 루프를 돌며struct inet_protocol inet_protocol_base부터 ㄴstruct inet_protocol* inet_protos[] 해시테이블에 icmp, udp, tcp, igmp를 위해 static하게 존재하는 아이템들을 포인터로 링크 시킨다.
그 다음 arp_init()을 호출한다. 이 함수는 neigh_table_init(&arp_tbl)을 호출하여 arp_table의 각 아이템을 초기화한다. 주로 타이밍에 관련한 것들이 대부분이다. 그리고나서 dev_add_packet(&arp_packet_type)을 콜하는데 이것은 struct packet_type* ptype_base[]해시테이블에 static하게 정의된 arp_packet_type의 포인터를 ETH_P_ARP인덱스에 링크시키는 것이다.
그 다음 ip_init()을 수행하는데 이것은 첫째로dev_add_packet(&ip_pack_proto)를 불러 역시 ptype_base[]해시 테이블에 포인터를 링크시키고 ip_rt_init()을 콜한다.이것은 내부적으로 devinet_init()을 콜하여서 struct gifconf_funct* gifconf_list에 PF_INET인텍스에 Inet_gifconf()함수를 링크시킨다. 그리고 ip_netdev_notifier를 struct notifier_block * netdev_chain에 링크시킨다. 둘째로
ip_fib_init()을 불러 netdev_chain에 fib_euls_notifier를 ip_netdev_notifier앞에 추가한다. 그리고 나서 또다른 struct neotifier_block* inetaddr_chain에 fib_inetaddr_notifier를 추가한다.
그 다음 tcp_v4_init(&inet_family_ops)를 불러서 tcp_inode에 모드 지정이나 (S_IFSOCK) tck_socket->inode에 tcp_inode를 매핑시키고 SS_UNCONNECTED로 스테이트를 넣고 타입을 SOCK_LOW로 지정하고 이 tcp_socket으로 inet_create()를 호출한다. 여기서 struct sock를 만들어 여기의 socket포인터에 tcp_socket을 매핑하고 sock 구조체의 receive_queue, write_queue, backlog_queue, error_queue를 링크하는일과 (sock_init_data(sock, sk)) 타입에 따라서 sock_ops에 inet_stream_ops나 inet_dgram_ops를 매핑한다.
그 다음 tcp_init()을 수행하여 “tcp_open_request”, “tcp_bind_bucket”,”tcp_tw_bucket”등을 위한 cache데이터를 만들어놓는다. 그리고 physical page 개수로 적절한 tcp hash table 을 만든다. 그리고 bind hash도 만들어놓는다.
그 다음 icmp_init(&inet_family_ops)을 부르는데 이것은 icmp->inode와 icmp->socket을 만든다.
이것으로 기본적인 initialize는 끝났다고 볼수 있다.
유저코드에서 socket()을 콜하면 sys_socket()을 콜하게되고 이것은 sock_create()를 부른다 이것은 struct socket 를 alloc하고 이 socket 아이템에 type을 카피하고 net_familes[]->create()를 부른다. 이것은 family가 AF_INET(==PF_INET)일경우에는 inet_create()를 콜한다.이것은 내부적으로 struct sock를 만드는 일을 한다.
그 다음 get_fd(sock_inode)를 콜하는데 이것은 빈 file structure를 얻고 그 file->f_dentry에inode를 alloc한다 그리고 file->op에 socket_file_ops를 링크시킨다. 이것은 추후에
106 static struct file_operations socket_file_ops = {
107 sock_lseek,
110 NULL, /* readdir */
111 sock_poll,
114 sock_no_open, /* special open code to disallow open via /proc */
115 NULL, /* flush */
116 sock_close,
117 NULL, /* no fsync */
118 sock_fasync119 };
를 통하여 read() 나 write()시에 sock_read 나 sock_write를 불리우게 한다.
3. receive 부분
Linux driver 초기화에서 main.c의 do_basic_setup()을 수행시키고 이것은 다시 device_setup()을 콜하고 이것은 다시 net_dev_init()을 콜한다. 이함수는 dev_base리스트(헤더는 loopBack device)에 configuration에서 설정된 device아이템들을 연결시킨다. 이것의 결과는 dev_base 리스트에서 서로 연결되어 있는 일련의 device 자료구조이다.
각 device 자료구조는 장치를 서술하고, 네트워크 프로토콜 계층에서 네트워크 드라이버가 어떤 일을 수행해야 할 때 부를 수 있는 콜백 루틴 세트를 제공한다. 이들 함수들은 대부분 데이터 전송과 네트워크 장치의 주소에 관련되어 있다. 네트워크 장치가 네트워크로부터 패킷을 수신하면 이 수신한 데이터를 sk_buff 자료구조로 바꾸어야 한다. 네트워크 드라이버는 이들을 수신할 때마다 backlog 큐에 수신한 sk_buff들을 추가한다. 만약 backlog 큐가 너무 커지면, 수신한 sk_buff 들은 무시된다. 이제 해야 할 일이 있으므로 실행할 준비가 되었다고 네트워크 하반부(bottom half)에 표시한다.
스케줄러가 네트워크 하반부 핸들러를 실행하면, 이는sk_buff의 backlog 큐를 처리하기 이전에 수신한 패킷을 어떤 프로토콜 계층으로 전달할지를 결정하며 전송되길 기다리고 있는 네트워크 패킷들을 처리한다. 리눅스 네트워킹 계층을 초기화할 때 각 프로토콜은 packet_type 자료구조를 ptype_all 리스트나 ptype_base 해시테이블에 추가함으로서 자신들을 등록했다. packet_type 자료구조는 프로토콜 타입과 네트워크 장치에 대한 포인터, 프로토콜의 수신 데이터 처리 루틴, 그리고 마지막으로 리스트나 해시 고리에 있는 다음 packet_type 자료구조에 대한 포인터를 가지고 있다. ptype_all 고리는 어떤 네트워크 장치이든지부터 수신되는 모든 패킷들을 엿보는데(snoop) 사용되지만 잘 사용되지 않는다. ptype_base 해시 테이블은 프로토콜 식별자로 해시되어 있으며, 들어오는 네트워크 패킷을 어떤 프로토콜이 받을 것인지 결정하는데 사용된다. 네트워크 하반부는 들어오는 sk_buff의 프로토콜 타입과 각 테이블에 있는 하나 이상의 packet_type 엔트리와 매치 시킨다. 프로토콜은 하나 이상의 엔트리와 매치될 수 있는데, 예를 들어 모든 네트워크 트래 픽을 엿볼 때 같은 경우이며, 이 경우 sk_buff는 복제가 된다. sk_buff는 매치되는 프로토콜 처리 루틴으로 전달된다.
IP 조각을 수신하는 것은 어려운데, 이는 IP 조각이 아무런 순서로나 도착할 수 있으므로 모두 수신받아야 재조립할 수 있기 때문이다. IP 패킷을 수신할 때마다 이것이 IP 조각인지 검사한다. 메시지 조각이 처음 도착하면, IP는 새 ipq 자료구조를 만들고, 이를 재조립을 기다리는 IP 조각의 리스트인 ipqueue에 연결한다. IP 조각이 계속 수신 되면 맞는 ipq 자료구조를 찾아 이 조각을 나타낼 ipfrag 자료구조를 새로 만든다. 각 ipq 자료구조는 조각난 IP 수신 프레임을 출발지와 도착지 IP 주소와 함께 유일하게 기술 하며, 위 계층 프로토콜 식별자와 이 IP 프레임의 식별자를 기술한다. 모든 조각이 도착하면, 이들은 하나의 sk_buff로 합쳐지고 처리할 다음 프로토콜 계층으로 전달된다. 각 ipq는 제대로 된 조각이 도착할 때마다 다시 시작되는 타이머를 가지고 있다. 만약 이 타이머가 만료되면, ipq 자료구조와 이것의 ipfrag들은 소멸되며, 메시지는 전송 중에 사라진 것으 로 간주된다. 이 메시지를 다시 전송하는 것은 더 윗 레벨의 프로토콜이 담당하는 문제이다.
위의 설명을 함수로 따라가보면 처음 인터럽트에의해 인터럽트 핸들러 isa ethernet link device driver handler 중에 el3_interrupt()가 불리우게 된다고 가정하자 . el3_interrupt()로 data recieve에의해 인터럽트 서비스루틴으로 들어오면 (ioaddr + EL3_STATUS)를 읽어들여서 error 여부등을 조사 하면서 RxComplete일 때 el3_rx()를 부른다. 에러가 없으면 dev_alloc_skb(pkt_len+5)를 불러 sk_buff를 생성한다. skb의 protocol과 dev를 setting하고 data를 skb로 카피한다. 그리고 mark_bh(NET_BH)를 마크함으로써 여유가 있을떄net_bh()에서 들어온 skb의 포인터를 얻은후 ptype_base[] hash table에서 들어온 skb protocol과 일치하는 table의 func(receive function)을 수행한다. 이미 등록이 되었던 ip_rcv()가 (ip protocol인 경우에) 불리어 지게 된다.
ip_rcv() 는 우선 들어온 skb packet type이 다른 호스트의 것이면 버린다.
그 이후에 ip header length가 올바른가 ip version4인가 등을 체크하고 multiple packet이면 ip_defrag()를 수행하여 가능한 packet들을 ipq에 리스트 업한다. pad가 있을가능성이 있으므로 pad를 trim한다. 그리고 ip_route_input()에서 iph와 dev정보등을 가지고 route table에서 skb_dst->… 의 정보를 세팅한다. 여기에선 ip_local_deliver()를 세팅시킨다.
그리고 마지막으로 ip_local_deliver()를 skb->dst->input()을 통해 콜한다.
ip_local_deliver()에서는 inet_protos[ ] 테이블을 검색하여 일치하는 프로토콜의 ipprot->handler()를 불러준다. inet_protos[ ] 테이블에는 igmp, udp, tcp, icmp등의 transport 계층의 프로토콜이 들어있고 리시브한 데이터가 tcp용이면 tcp_v4_rcv()가 콜된다.
tcp_v4_rcv()에선 우선 ip header를 벗기고 tcp_statistics.TcpInSegs++ 를 해준다.
그리고 나서 checksum을 계산하고 tcp_v4_lookup()을 이용하여 sock 스트럭쳐에 레퍼런스한다. 그다음에 tcp_rcv_state_process()를 수행하는데 이것은 sock 스트럭쳐를 가지고 sequence number를 check하고, reset bit를 check 하고 SYN을 check해서 우리가 처음 보낸 SYN과 같은지 확인한다. 그리고 ACK를 확인한다. 그뒤에 URG bit를 check하고 segment text를 처리한다. 이때 status가 TCP_ESTABLISHED이면 tcp_data()를 수행한다. 이 코드는 TCP handshake를 위해 존재하며 각각 스테이트에 따라 보내 주어야 하는 신호들에 대한 언급이다. 결국 TCP의 state 다이어그램을 구현한 코드이다. tcp_data()는 밑단에서 받은 데이터를 header와 tail을 떼고 tcp_data_queue()를 불러 유저에게 데이터를 전달하기위해 큐잉을 하고 순서화된 패킷은 receive queue에 넣고 순서화 안된 것은 out_of_order_queue에 넣는다. 데이터가 준비되었으면 유저에게 sk->data_ready로데이터가 있음을 알린다.
여기까지가 인터럽트에 의해 데이터가 준비되는 과정이고 사실은 이전에 데이터를 요청하고 잠들어있는 프로세스가 존재하는데 이것은 응용프로그램에서 socket에 read operation을 수행하면 sys_read()가 call되는데 이것은 fget()할때 리턴된 file structure에 연결된 read 함수 sock_read()를 부르고 inode를 이용해 socket 구조체를 얻고 이것을 인자로 sock_recvmsg()를 부른다. 이것은 다시 socket 구조체의 함수인 sock_ops_sendmsg()를 부른다. 이것은 inet_recvmsg()와 이전에 inet_stream_ops, inet_dgram_ops를 통해 연결이 되어 있고 여기서 바인드를 하고 다시 sk->prot->recvmsg()를 콜해서 add_wait_queue()로 sleep에 들어갔다가 위의 인터럽트에 의해 sock structure 데이터가 준비가 되면 user buffer에 복사한다. 그후엔 다시 위로위로 리턴된뒤 어플리케이션은 read()에서 읽은 데이터로 job을 수행하게 된다.
![]() 4. send 부분
4. send 부분
패킷은 응용프로그램이 데이터를 교환하거나, 네트워크 프로토콜이 이미 만들어진 연결이나 만들어지는 연결을 지원할 때 만들어져서 보내진다. 어떤 방법으로 데이터가 만들어졌던지 간에 데이터를 포함하고 있는 sk_buff가 만들어지고, 각 프로토콜 계층을 통과하면서 프로토콜 계층이 다양한 헤더를 붙인다.
sk_buff는 전송할 네트워크 장치로 전달되어야 한다. 먼저 IP 같은 프로토콜이라도 어떤 네트워크 장치를 사용할지를 결정해야 한다. 이는 패킷에 가장 맞는 루트에 따라 다르다. PPP 프로토콜같은 것을 통해 모뎀으로 하나의 네트워크에 연결된 컴퓨터에 있어서는 이 루트를 선택하는 것은 쉽다. 패킷은 루프백 장치를 통해 로컬호스트나, PPP 모뎀 연결의 끝에 있는 게이트웨이 둘 중 하나로 전송될 것이다. 이더넷으로 연결되어 있는 컴퓨터에 있어서는, 네트워크에 많은 컴퓨터가 연결되어 있으므로 이 선택은 더 어렵다.
IP 패킷을 전송할 때 항상 IP는 도달할 IP 주소로 가는 루트(route)를 해결하기 위해 라우팅 테이블(routing table)을 사용한다. 각 IP 목적지는 라우팅 테이블에서 성공적으로 찾게 되어, 사용할 루트를 기술하는 rtable 자료구조를 돌려준다. 이는 사용할 출발지 IP 주소와, 네트 워크 device 자료구조의 주소, 때때로 미리 만들어진 하드웨어 헤더를 포함한다. 이 하드 웨어 헤더는 네트워크 장치마다 다른 것으로서 출발지와 도착지의 하드웨어 주소와, 매개체 별로 다른 정보를 가지고 있다. 만약 네트워크 장치가 이더넷 장치이라면, 하드웨어 헤더는 그림 10.1에서 보는 바와 같을 것이며, 출발지와 도착지 주소는 물리적인 이더넷 주소일 것 이다. 하드웨어 헤더는 루트와 함께 캐시되는데, 이는 이 하드웨어 헤더가 이 루트를 통하여 전송하는 모든 IP 패킷에 추가되어야 하는데, 이를 다시 만드는 것은 시간이 걸리기 때문이다. 하드웨어 헤더는 ARP 프로토콜로 해결되어야 하는 물리적인 주소를 가질 수도 있다. 이 경우 밖으로 나가는 패킷은 주소가 해결될 때까지 꼼짝못하고 기다리고 있어야 한다. 한번 주소가 해결되고 나면, 하드웨어 헤더가 만들어지고, 이 인터페이스를 사용하는 IP 패킷이 다시 ARP를 할 필요가 없도록 이 하드웨어 헤더를 캐시한다.
모든 네트워크 장치는 최대 패킷 크기를 가지고 있으며, 이보다 큰 크기의 데이터를 보내거나 받을 수 없다. IP 프로토콜은 이런 경우를 허용하여 데이터를 네트워크 장치가 처리할 수 있는 패킷 크기로 데이터를 잘게 쪼갠다. IP 프로토콜 헤더는 플래그와 이 조각의 옵셋을 담 은 조각 항목을 가지고 있다.
IP 패킷이 전송할 준비가 되면, IP는 IP 패킷을 밖으로 보낼 네트워크 장치를 찾는다. 장치 는 IP 라우팅 테이블에서 찾게 된다. 각 device는 최대 전송 단위를 나타내는 항목으로 가지고 있는데 (바이트 단위), 이는 mtu 항목이다. 만약 장치의 mtu가 전송하려는 IP 패킷의 크기보다 작으면, IP 패킷은 좀 더 작은 크기(mtu 크기)의 조각으로 쪼개져야 한다. 각 조각 은 sk_buff로 표현된다. IP 헤더에는 이것이 조각이며, 이 패킷이 데이터의 어떤 옵셋부터 가지고 있는지 표시된다. 마지막 패킷은 마지막 IP 조각이라고 표시된다. 만약, 이 쪼개는 도중에 IP가 sk_buff를 할당받지 못한다면 전송을 실패하게 된다
참고자료 :
http://kernelkorea.org/의 the linux kernel 한글판.
http://lxr.linux.no/ 의 linux source browser