
![]()
![]()
![]()
11.7. Case study: ATM transmission of multiplexed-MPEG streams. Introduction
Available ATM network throughputs, in the order of Gb/s, allow broadband applications to interconnect using ATM infrastructures. We will consider, as a case study to give some intuition about the main elements that will be found in a telecommunication system-on-a-chip, the architectural design of an ATM ASIC. The architecture is conceived to give service to applications in which we will need to multiplex and transport multimedia information to an end-node through an ATM network. Interactive multimedia and mobile multimedia are examples of applications that will use such a system.
Interactive multimedia (INM) relates to the network delivery of rich digital content, including audio and video, to client devices (e.g. desktop computer, TV and set-top box), typically as part of an application having user-controlled interactions. It includes interactive movies, where viewers can explore different subplots, interactive games, where players take different paths based on previous event outcomes, training-on-demand, in which training content tunes to each student existing knowledge, experience, and rate of information absorption, interactive marketing and shopping, digital libraries, video-on-demand and so on.
Mobile multimedia applies in general to every scenario in which a remote delivery of expertise to mobile agents will be needed. It includes applications in computer supported cooperative work (CSCW) where mobile workers with difficult problems receive advice to enhance the efficiency and quality of their tasks or emergency-response applications (ambulance services, police, fire brigades).
A system offering this service of multiplexing and transport through ATM networks should meet the following requirements if it wants to cover applications as explained above:
11.7.1. A system view
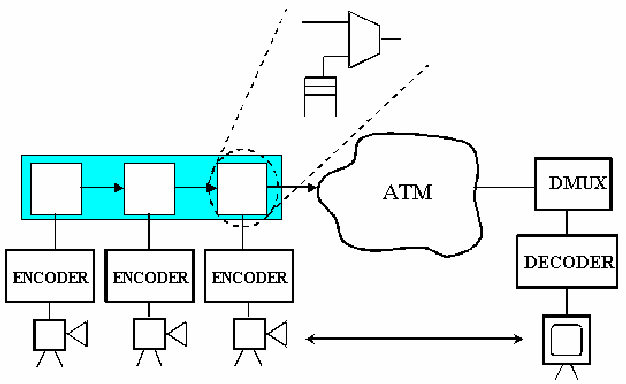
Distributing the multiplexing function between the different sources allows meeting efficiently the requirements of mobility/portability and streaming scalability.
|
|
![]()
Figure-11.28:
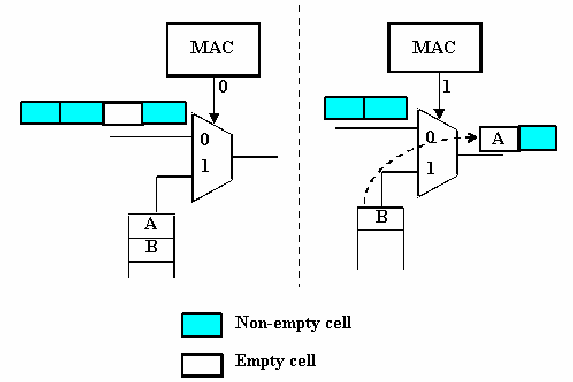
This distribution can be achieved with a basic unit that applies locally the multiplexing function to each source, as can be seen in figure 11.28. This basic unit is repeated for each stream that we want to multiplex. Figure 11.29 shows how the basic unit works: there is a queue, where cells carrying information from the source wait until the MAC (Medium Access Control) unit gives permission to the cells to be inserted. When an empty cell is found and the MAC unit allows insertion, this empty cell disappears from the flow and a new cell is inserted.
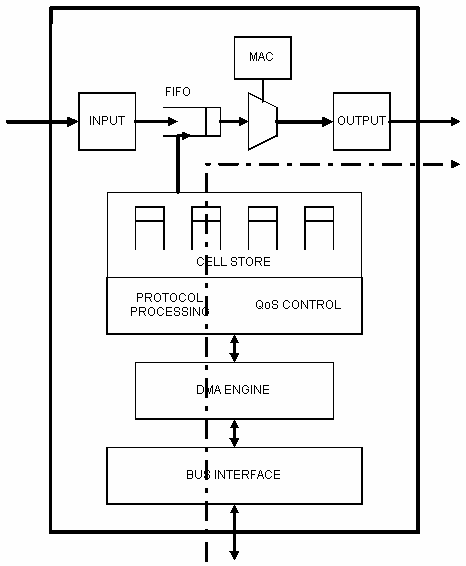
Figure 11.30 shows the details of this basic unit. There are four main blocks:
|
|
![]()
Figure-11.29:
The path followed by a cell from the source to the output module when is multiplexed is also shown in figure 11.30.
|
|
![]()
Figure-11.30:
In what follows, we will get into the details of the QoS block, MAC block and protocol processing and DMA block, leaving up to the end the cell multiplexing unit block to explain the main design features of telecommunication ASICs.
11.7.2. Quality of Service (QoS) control (Prioritization)
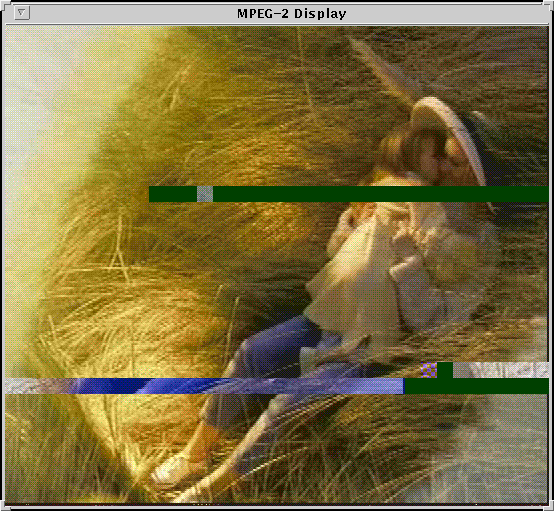
One potential problem in ATM networks, caused by the bursty nature of traffic is cell loss. When several sources transmit at their peak rates simultaneously, the buffers available at some switches may cause overflow. The subsequent drops of cells lead to severe degradation in service quality (multiplicative effect) due to the loss of synchronization at the decoder. In figure 11.31, The effect in the quality of the image received due to cell drops is shown. The decoded picture has been transmitted through an ATM network with congestion problems.
Rather than randomly dropping cells during network congestion, we might specify to the ATM network the relative importance of different cells (prioritization) so that only less important ones are dropped. This is possible in ATM networks thanks to the CLP (cell loss priority) cell header bit. Thus, if we do so, when the network enters a period of congestion, cells are dropped in an intelligent fashion (non-priority cells first) so that the end-user only perceives a small degradation in the service's QoS.
|
|
![]()
Figure-11.31:
However, when the network is operating under normal conditions, both high priority and low priority data are successfully transmitted and a high quality service is available to the end user. In the worst-case scenario, the end user is guaranteed a predetermined minimum QoS dictated by the high priority packets.

|
|
![]()
Figure-11.32:

|
|
![]()
Figure-11.33:
In figures 11.32, 11.33, the effect in the quality of the image received due to cell drops is shown. However, as the priority mechanism is applied (low frequency image information as high priority data and high frequency image information as low priority data) an improvement in the quality of the decoded image is observed.
Figure 11.34 shows the effect of non-priority cell drops in the high frequency portion of the decoded image information.
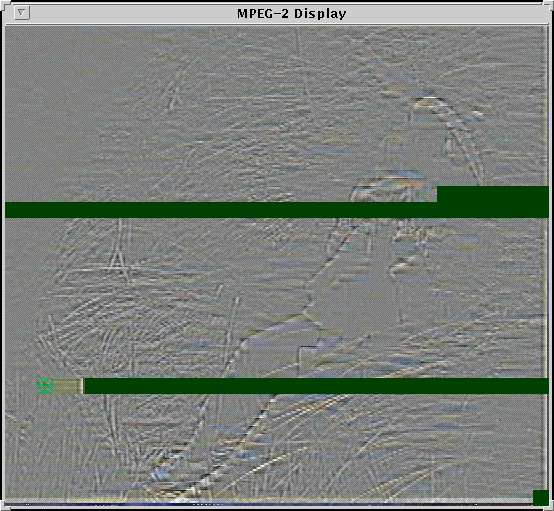
|
|
![]()
Figure-11.34:
11.7.3. Medium access control (MAC)
The basic functionality of the distributed multiplexing algorithm is to incorporate low speed ATM sources into a single ATM flow. When two or more sources try to access to the common resource a conflict can occur.
The medium access control (MAC) algorithm should solve the conflicts between two or more sources simultaneously accessing to the high-speed bus. Each MAC block controls the behavior of a basic unit. It can be considered as an state machine which acts depending on the basic unit inputs: empty cell from the high-speed bus, cell from the MPEG source connected to it and access request from another basic units.
The MAC algorithm can adopt the DQDB (Distributed Queue Dual Bus) philosophy, taking into account that there is just one information flow (downstream). A dedicated channel is responsible for sending requests upstream.
The main objective of the DQDB protocol is to create and maintain a global queue of access requests to the shared bus. That queue is distributed among all connected basic units. If a basic unit wants to send an ATM cell, a request to all its predecessors is sent. Therefore, each basic unit receives, from the neighbor on the right, access requests coming from every basic unit on the right. These requests and the requests of the current basic unit are sent to the neighbor on the left. For each request, an empty cell passes through a basic unit without being assigned.
When QoS control is applied, these algorithms should be modified to allow all HP cells to be sent before any LP cell queued at any basic unit. This mechanism achieves critical information to be sent first when congestion appears.
11.7.4. Communication with the host processor: protocol processing & DMA.
Another important point to face is the information exchange between the software running on the host processor and the basic unit. The main mechanism used for these transactions is DMA (Direct Memory Access). In this technique all communications passes through special shared data structures - they can be read from or written to by both the processor and the basic unit - that are allocated in the system's main memory.
Any time any data is read from or written to main memory is consider to be "touched". A design should try to minimize data touches because of the large negative impact they can have on performance.
Let us imagine we are running, on a typical monolithic Unix Kernel machine, an INM application over an implementation of the AAL/ATM protocol. Figure 11.35 shows all data touch operations involved in transmitting a cell from host main memory to the basic unit. The sequence of events is as follows:
To copy data from the user buffer into a set of kernel buffers, both of them located in main memory, steps 2 and 3 are needed:
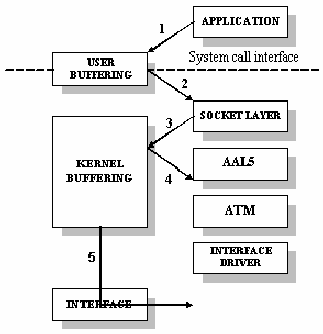
|
![]()
Figure-11.35:
To adapt this data to ATM transmission step 4 is needed.
Figure 11.36 shows what happens in hardware for the events explained above. Some of
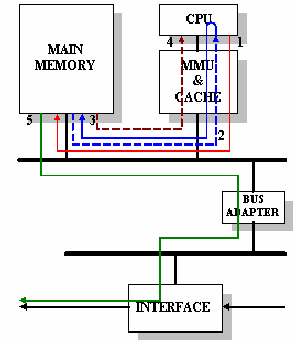
|
|
![]()
Figure-11.36:
the lines are dashed to indicate that the corresponding read operation might be satisfied from the cache memory rather than from the main memory. In the best case, there are three data touches for any given piece of data and in the worst case, there are five data touches.
11.7.4.1. A quantitative approach to data touches
Why is so important the number of data touches? Let us consider a main memory bandwidth of about 1.5 GB/s for sequential writes and 0.7 GB/s for sequential reads. If we assume that on the average there are three reads for every two writes (see figure 11.36), the resulting average memory bandwidth is ~ 1.0 GB/s . If our basic unit requires five data touch operations for every word in every cell, then the average throughput we can expect will be only a fifth of the average memory bandwidth, e.g. 0.2 GB/s . Clearly, every data touch that we can save will provide for significant improvements in throughput.
11.7.4.2. Reducing the number of data touches
The number of data touches can be reduced if either kernel buffers or user and kernel buffers are allocated from extra on-chip memory added to the basic unit.
In figure 11.37, kernel buffers are allocated from memory on the basic unit to reduce data touches form 5 to 2. Programmed I/O is the technique used to move data from the user buffer to these on-chip kernel buffers (data is touched by the processor before is transfer to the basic unit).
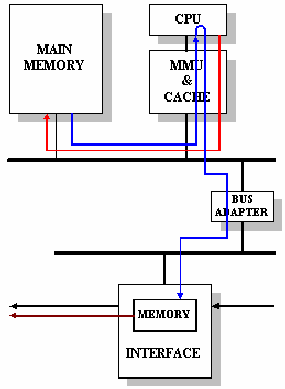
|
|
![]()
Figure-11.37:
Figure 11.38 shows the same data touch reduction but with DMA being used instead of programmed I/O . In this case, as data arriving from main memory to the basic unit is not touched by the processor, it cannot compute the checksum needed in the AAL layer; therefore, this computation will have to be implemented in hardware in the basic unit.
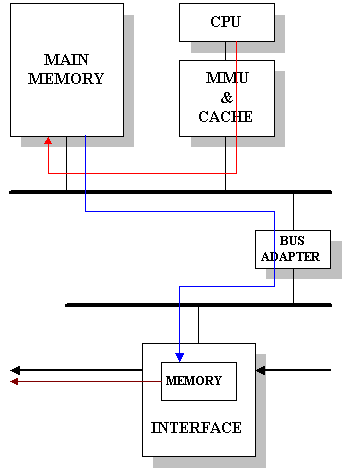
|
|
![]()
Figure-11.38:
Figure 11.39 shows an alternative that involves no main memory accesses at all (zero data touches). Both, user and kernel buffers are allocated from on-chip memory. Although this approach reduces drastically the number of data touches, it has two disadvantages:
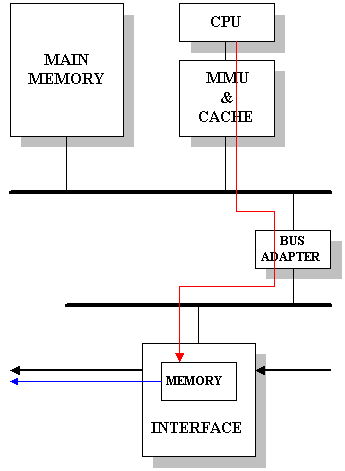
|
|
![]()
Figure-11.39:
11.7.5. Cell multiplexing unit: explanation of main design features of Tcomm. ASICs.
There are four modules in the Cell Multiplexing Unit (figure 11.40):
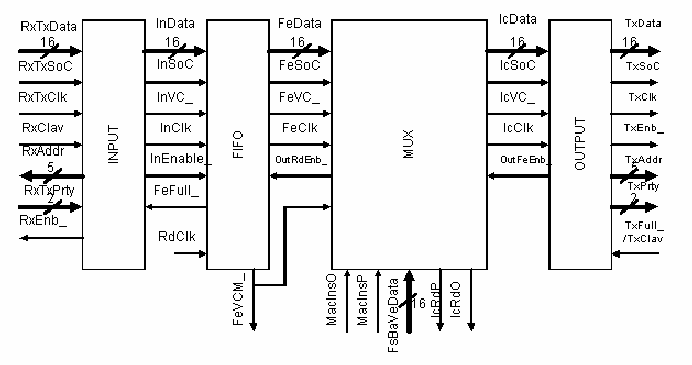
|
|
![]()
Figure-11.40:
Their functionalities and main design features are as follows:
Input and Output modules implement UTOPIA protocol (level one and two), the ATM-Forum standard communication protocol between an ATM layer and a Physical layer entity. Common design elements used in both modules are registers, finite-state machines, counters, and logic to compare register values, as shown in the following figures (figure 11.41 and figure 11.42).
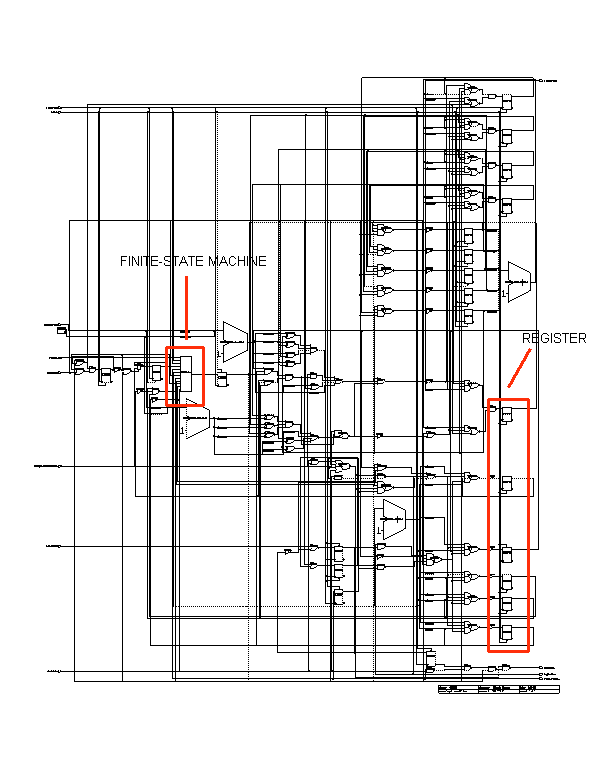
|
|
![]()
Figure-11.41:
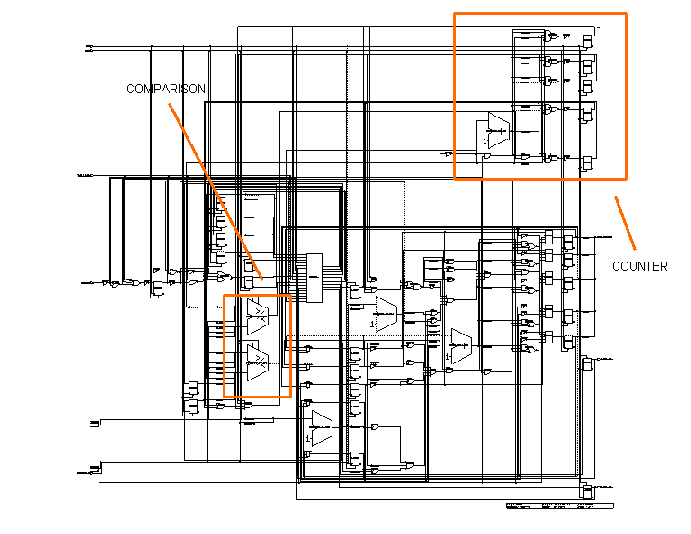
|
|
![]()
Figure-11.42:
FIFO module isolates two different clock domains: input cell clock domain from output cell clock domain. Besides, it allows cell storing (First Input, First Output) when UTOPIA protocol stops cell flow.
Having different clock domains is a characteristic feature of telecommunication systems-on-a-chip that adds a new dimension to the design complexity: unsynchronized clock domains generate in the flip-flops that interfaces both domains metastable behavior. If realible system function is desired, techniques to reduce the probability of having a metastable behavior in a flip-flop have to be implemented.
The FIFO queue is implemented with a dual-port RAM memory and two registers to store addresses: the write and read pointer. Part of this queue is shown in figure 11.43.
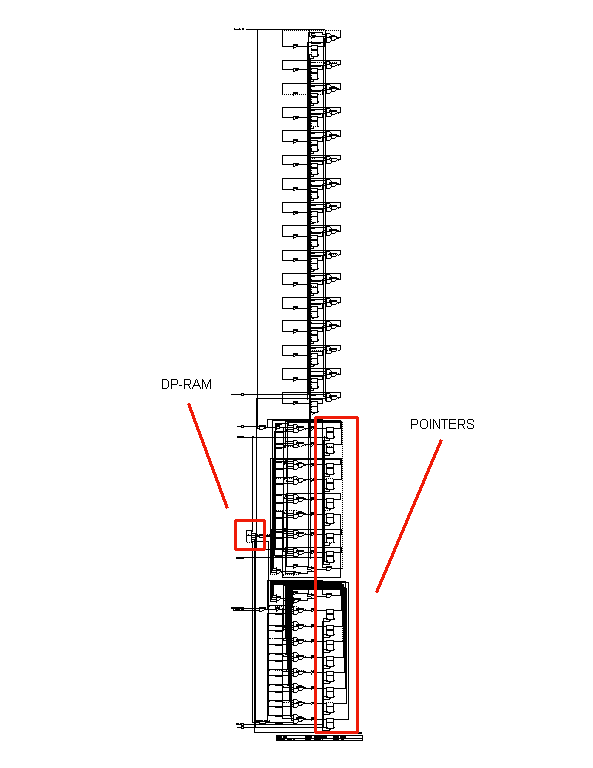
|
|
![]()
Figure-11.43:
Multiplexing module changes empty cells by assigned ones. The insertion module has two registers to avoid the lost of parts of a cell when the UTOPIA protocol stops, another two registers to delay the information coming from the network and one register for pipelining the module (figure 11.44)
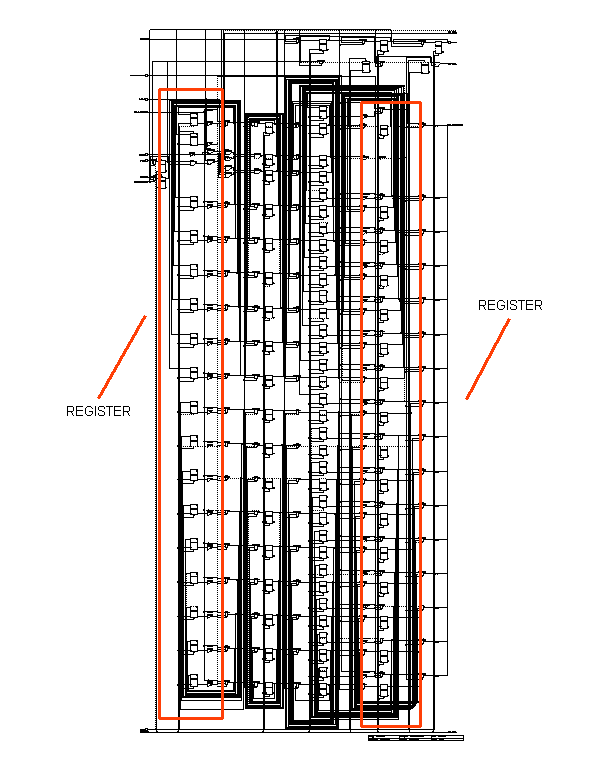
|
|
![]()
Figure-11.44:
![]()
![]()
![]()
![]()

![]()
EJM 17/2/1999