PVM (Parallel Virtual Machine) is a byproduct of an ongoing heterogeneous network computing research project involving the authors and their institutions. The general goals of this project are to investigate issues in, and develop solutions for, heterogeneous concurrent computing. PVM is an integrated set of software tools and libraries that emulates a general-purpose, flexible, heterogeneous concurrent computing framework on interconnected computers of varied architecture. The overall objective of the PVM system is to to enable such a collection of computers to be used cooperatively for concurrent or parallel computation. Detailed descriptions and discussions of the concepts, logistics, and methodologies involved in this network-based computing process are contained in the remainder of the book. Briefly, the principles upon which PVM is based include the following:
The PVM system is composed of two parts. The first part is a daemon , called pvmd3 and sometimes abbreviated pvmd , that resides on all the computers making up the virtual machine. (An example of a daemon program is the mail program that runs in the background and handles all the incoming and outgoing electronic mail on a computer.) Pvmd3 is designed so any user with a valid login can install this daemon on a machine. When a user wishes to run a PVM application, he first creates a virtual machine by starting up PVM. (Chapter 3 details how this is done.) The PVM application can then be started from a Unix prompt on any of the hosts. Multiple users can configure overlapping virtual machines, and each user can execute several PVM applications simultaneously.
The second part of the system is a library of PVM interface routines. It contains a functionally complete repertoire of primitives that are needed for cooperation between tasks of an application. This library contains user-callable routines for message passing, spawning processes, coordinating tasks, and modifying the virtual machine.
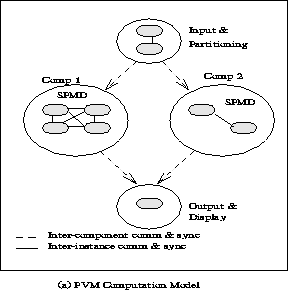
The PVM computing model
is based on the notion that an application
consists of several tasks.
Each task is responsible for a part of the application's computational workload.
Sometimes an application is parallelized along its functions;
that is, each task performs a different function, for example,
input, problem setup, solution, output, and display.
This process is often called functional parallelism .
A more common method of parallelizing an application is called
data parallelism .
In this method all the tasks are the same,
but each one only knows and solves a small part of the data.
This is also referred to as the SPMD (single-program multiple-data)
model of computing. PVM supports either or a mixture of these methods.
Depending on their functions, tasks may execute in parallel and may
need to synchronize or exchange data, although this is not always the case.
An exemplary diagram of the PVM computing model is shown in
Figure ![]() .
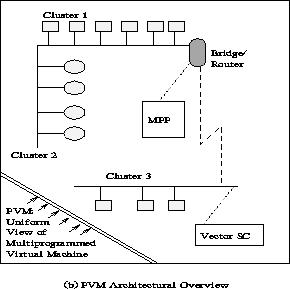
and an architectural view of the PVM system, highlighting the
heterogeneity of the computing platforms supported by PVM, is
shown in Figure
.
and an architectural view of the PVM system, highlighting the
heterogeneity of the computing platforms supported by PVM, is
shown in Figure ![]() .
.
The PVM system currently supports C, C++, and Fortran languages. This set of language interfaces have been included based on the observation that the predominant majority of target applications are written in C and Fortran, with an emerging trend in experimenting with object-based languages and methodologies.
The C and C++ language bindings for the PVM user interface library are implemented as functions, following the general conventions used by most C systems, including Unix-like operating systems. To elaborate, function arguments are a combination of value parameters and pointers as appropriate, and function result values indicate the outcome of the call. In addition, macro definitions are used for system constants, and global variables such as errno and pvm_errno are the mechanism for discriminating between multiple possible outcomes. Application programs written in C and C++ access PVM library functions by linking against an archival library (libpvm3.a) that is part of the standard distribution.
Fortran language bindings are implemented as subroutines rather than as functions. This approach was taken because some compilers on the supported architectures would not reliably interface Fortran functions with C functions. One immediate implication of this is that an additional argument is introduced into each PVM library call for status results to be returned to the invoking program. Also, library routines for the placement and retrieval of typed data in message buffers are unified, with an additional parameter indicating the datatype. Apart from these differences (and the standard naming prefixes - pvm_ for C, and pvmf for Fortran), a one-to-one correspondence exists between the two language bindings. Fortran interfaces to PVM are implemented as library stubs that in turn invoke the corresponding C routines, after casting and/or dereferencing arguments as appropriate. Thus, Fortran applications are required to link against the stubs library (libfpvm3.a) as well as the C library.
All PVM tasks are identified by an integer task identifier (TID) . Messages are sent to and received from tids. Since tids must be unique across the entire virtual machine, they are supplied by the local pvmd and are not user chosen. Although PVM encodes information into each TID (see Chapter 7 for details) the user is expected to treat the tids as opaque integer identifiers. PVM contains several routines that return TID values so that the user application can identify other tasks in the system.
There are applications where it is natural to think of a group of tasks . And there are cases where a user would like to identify his tasks by the numbers 0 - (p - 1), where p is the number of tasks. PVM includes the concept of user named groups. When a task joins a group, it is assigned a unique ``instance'' number in that group. Instance numbers start at 0 and count up. In keeping with the PVM philosophy, the group functions are designed to be very general and transparent to the user. For example, any PVM task can join or leave any group at any time without having to inform any other task in the affected groups. Also, groups can overlap, and tasks can broadcast messages to groups of which they are not a member. Details of the available group functions are given in Chapter 5. To use any of the group functions, a program must be linked with libgpvm3.a .
The general paradigm for application programming with PVM is as follows. A user writes one or more sequential programs in C, C++, or Fortran 77 that contain embedded calls to the PVM library. Each program corresponds to a task making up the application. These programs are compiled for each architecture in the host pool, and the resulting object files are placed at a location accessible from machines in the host pool. To execute an application, a user typically starts one copy of one task (usually the ``master'' or ``initiating'' task) by hand from a machine within the host pool. This process subsequently starts other PVM tasks, eventually resulting in a collection of active tasks that then compute locally and exchange messages with each other to solve the problem. Note that while the above is a typical scenario, as many tasks as appropriate may be started manually. As mentioned earlier, tasks interact through explicit message passing, identifying each other with a system-assigned, opaque TID.
main()
{
int cc, tid, msgtag;
char buf[100];
printf("i'm t%x\n", pvm_mytid());
cc = pvm_spawn("hello_other", (char**)0, 0, "", 1, &tid);
if (cc == 1) {
msgtag = 1;
pvm_recv(tid, msgtag);
pvm_upkstr(buf);
printf("from t%x: %s\n", tid, buf);
} else
printf("can't start hello_other\n");
pvm_exit();
}
Shown in Figure ![]() is the body of the PVM program hello,
a simple example that illustrates the basic concepts of PVM programming.
This program is intended to be invoked manually; after printing its
task id (obtained with pvm_mytid()), it initiates a copy of
another program called hello_other using the pvm_spawn()
function. A successful spawn causes the program to execute
a blocking receive using pvm_recv.
After receiving the message, the program prints the message sent by
its counterpart, as well its task id; the buffer is extracted
from the message using pvm_upkstr.
The final pvm_exit call dissociates the program from the PVM system.
is the body of the PVM program hello,
a simple example that illustrates the basic concepts of PVM programming.
This program is intended to be invoked manually; after printing its
task id (obtained with pvm_mytid()), it initiates a copy of
another program called hello_other using the pvm_spawn()
function. A successful spawn causes the program to execute
a blocking receive using pvm_recv.
After receiving the message, the program prints the message sent by
its counterpart, as well its task id; the buffer is extracted
from the message using pvm_upkstr.
The final pvm_exit call dissociates the program from the PVM system.
Figure: PVM program hello_other.c
#include "pvm3.h"
main()
{
int ptid, msgtag;
char buf[100];
ptid = pvm_parent();
strcpy(buf, "hello, world from ");
gethostname(buf + strlen(buf), 64);
msgtag = 1;
pvm_initsend(PvmDataDefault);
pvm_pkstr(buf);
pvm_send(ptid, msgtag);
pvm_exit();
}
Figure ![]() is a listing of the ``slave'' or spawned program; its
first PVM action is to obtain the task id of the ``master'' using
the pvm_parent call. This program then obtains its hostname
and transmits it to the master using the three-call sequence -
pvm_initsend to initialize the send buffer;
pvm_pkstr to place a string, in a strongly typed and
architecture-independent manner, into the send buffer; and pvm_send
to transmit it to the destination process specified by ptid,
``tagging'' the message with the number 1.
is a listing of the ``slave'' or spawned program; its
first PVM action is to obtain the task id of the ``master'' using
the pvm_parent call. This program then obtains its hostname
and transmits it to the master using the three-call sequence -
pvm_initsend to initialize the send buffer;
pvm_pkstr to place a string, in a strongly typed and
architecture-independent manner, into the send buffer; and pvm_send
to transmit it to the destination process specified by ptid,
``tagging'' the message with the number 1.