During the Web era (1990s), the user interface and graphics were rendered by the Web browser, e.g., Netscape Navigator or Microsoft Internet Explorer. Programmers were able to deliver a complete system to end-users after writing only the application logic and some simple HTML specifying the user interface behavior. Result: a revolution in innovation, with most Web applications written in a few months by a handful of people.
Suppose that you'd observed that telephones are much more common and portable than personal computers and Web browsers. Furthermore, you'd noticed that telephones are able to be used by almost everyone, whereas many consumers have little patience for the complexities of the PC. Thus, you'd want to make your information system accessible to a user with only a telephone. How would you have done it? In the 1980s, you'd rent a telephone line, buy a big specialized box to recognize utterances, buy another specialized box to talk to the user, and park those boxes right next to the main server for your application. In the 1990s, you'd have had to rent a telephone line, buy specialized software, and park a standard computer running that software next to the server running your application. Result in both decades: very little innovation, with only the largest organizations offering voice/telephone interfaces to their information systems.
With the advent of today's voice browsers, the coming years promise to be a period of tremendous innovation in the development of telephone-accessible Internet applications. With a Web application, you operate the HTTP server and run the application code; someone else runs the browser. The idea of the voice browser is the same. You operate a server and the application. Someone else, perhaps the phone company, runs the telephone lines and voice browser.
Bottom line: voice browsers allow you to build telephone voice applications with nothing more than an HTTP server. From this, great innovation shall spring.
Suppose Tracy, a vice president at a Boston-based firm, has just flown into Los Angeles. She wants to know the telephone number and address of her company's Los Angeles office, as well as the direct number for one of the employees. Since her company intranet is not telephone-accessible, she has to call up her assistant and ask him to open up a Web browser to look up the information in the intranet.
With VoiceXML, it can take as little as a few hours for a developer to take virtually any information available on the Web and make it available by telephone — not just to callers with high-tech cellphones, but to anyone with any kind of telephone. Tracy would be able to dial a number and say which office or employee she is looking for. After searching through some of the intranet's database tables, the VoiceXML application can read aloud the phone numbers and addresses she wants. And next time Tracy arrives confused in a foreign city, she won't have to rely on her assistant being at his desk.
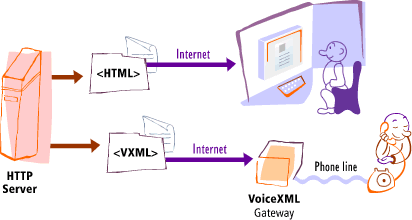
Figure 10.1: HTML: Publisher owns the HTTP server, which uses HTML to specify a user experience that is rendered on the reader's desktop computer. VoiceXML: Publishers owns the HTTP server, which uses VoiceXML to specify a user experience that is rendered on a 3rd-party gateway system and delivered as audio to the user's telephone.
You use a Web form to configure the gateway with the URL of your application, and it will associate a telephone number with it. In the case of Tellme, your users call 1-800-555-TELL, dial your 5-digit extension, and now they're talking to your application.
| A positive development in this area is that a number of voice gateways (e.g., VoiceGenie, www.voicegenie.com) are now partnering with providers of biometric voice authentication software such as VoiceTrust (www.voice-trust.com/) and Vocent (www.vocent.com). |
<?xml version="1.0"?>
<vxml version="2.0">
<form>
<block>
<audio>Hello, World</audio>
</block>
</form>
</vxml>
The first tag, <?xml version="1.0"?>
As in any XML document, every opening tag (e.g., <vxml></vxml>,/<else/>version="2.0"
The <vxml version="2.0"><form>,<block><audio><goto><audio>text</audio><audio src="wav_file_URL"/>
The gateway will assign you a telephone number or extension that you can point to your Web server. Point it to a file called hello-world.vxml that contains the VoiceXML example above. This example should work with most gateways, but each gateway employs slightly different VoiceXML syntax, so glance over the online documentation provided for the gateway you choose.
<?xml version="1.0"?>
<vxml version="2.0">
<form id="animal_questionnaire">
<field name="favorite_animal">
<prompt>
<audio>Which do you like better, dogs or cats?</audio>
</prompt>
<grammar>
<![CDATA[
[
[dog dogs] {<option "dogs">}
[cat cats] {<option "cats">}
]
]]>
</grammar>
<!-- if the user gave a valid response, the filled block
is executed. -->
<filled>
<if cond="favorite_animal == 'dogs'">
<!-- this would take the user to a form called
popular_dog_facts within the same VoiceXML
document -->
<goto next="#popular_dog_facts"/>
<else/>
<!-- this expression is an EMCAScript (JavaScript)
expression, composed of a concatenated string
and variable; this will take the user to the
URI psychological_evaluation.cgi?affliction=cats
-->
<goto expr="'psychological_evaluation.cgi?affliction='
+ favorite_animal"/>
</if>
</filled>
<!-- if the user responded but it didn't match the
grammar, the nomatch block is executed -->
<nomatch>
I'm sorry, I didn't understand what you said.
<reprompt/>
</nomatch>
<!-- if there is no response for a few seconds, the
noinput block is executed -->
<noinput>
I'm sorry, I didn't hear you.
<reprompt/>
</noinput>
</field>
</form>
<!-- additional forms can go here -->
</vxml>
In this example, we:
The structure of the VoiceXML code in this example is basically identical to that of the "Hello, World" example, with a few additional elements. The top two lines are present in every VoiceXML 2.0 document. Next, we have a form; this time the form is named, as we must do if we are to have more than one form in a document.
|
Note on grammars
In VoiceXML 1.0, the W3C did not specify the grammar format, allowing each VoiceXML platform to implement grammars as they chose. In VoiceXML 2.0, each platform is required to implement the XML format of the W3C's Speech Recognition Grammar Format (SRGF), the latest draft of which is available from http://www.w3.org/TR/grammar-spec/. In one vendor's implementation, the following SRGF grammar can be used in place of the grammar in the example:
<grammar xml:lang="en-US"
type="application/srgs+xml" version="1.0">
<rule id="animal" scope="public">
<one-of>
<item>
<one-of tag="dogs">
<item>dog</item>
<item>dogs</item>
</one-of>
</item>
<item>
<one-of tag="cats">
<item>cat</item>
<item>cats</item>
</one-of>
</item>
</one-of>
</rule>
</grammar>
However, other vendors have implemented the SRGF slightly differently.
As the SRGF specification graduates from a "candidate recommendation",
vendors' implementations of SRGF should converge.
|
favorite_animal<field>favorite_animalfavorite_animal
That's all there is to getting user input. Now we can use the value of their response in our
program. In this example, if their answer is "dogs", they will be sent to a form named
"popular_dog_facts" within the same VoiceXML document. If they answer "cats",
they will be sent to a different URL, psychological_evaluation.cgi?affliction=cats.gotofavorite_animal
Those two examples are enough to give you the gist of VoiceXML and hopefully an appreciation for the simplicity of voice application development using VoiceXML.
Excellent tutorial and reference material can be found on the developer sites at Tellme (http://studio.tellme.com/) and BeVocal (http://cafe.bevocal.com/).
[vancouver toronto halifax] {<option "valid_city">}
Your application should respond to the user with something like
"Yes, that is a Canadian city" or "I've never heard of that city."
Try out your application. Name some cities that are not on your list and see if it mistakenly thinks they are valid cities. Now add some more cities to your list (e.g., Calgary, Winnipeg, Victoria, Saskatoon). As you make your list longer and longer, you'll tend to start getting a few false positives.
Decide on a rule of thumb for how many elements it's reasonable to have in one grammar.
There are applications that have thousands of elements in a grammar. However, they've typically gone through a process of grammar tuning using representative probabilities for grammar matches. For this exercise, just extend the standard grammar above.
Consider that if you're authenticating users over the phone the contributions that might be most interesting are any new responses to questions asked by that user.
Typically you'd open your Web browser, log in, and go to an admin page from which you can approve, reject, or edit submissions.
But it sure would be nice to approve and reject submissions with your cellphone when you're out walking the dog. (Editing is harder to do by phone, but it's less common anyway, so it can wait until you're back at your desk.)
Create some simple voice-accessible admin pages. Since the typical username/password authentication is so tedious, you might want to make them accessible with just a numeric pin. Note that it isn't ideal in general to protect a set of pages with just one pin because that makes it harder to delegate/revoke admin privileges later, but it will do for this exercise.
Write down the client's answers to the following questions:
| Mobile Browser | VoiceXML |
|---|---|
| requires browser-enhanced telephones | can be used with any phone |
| user-input with uncomfortable keypads | speech or keypad input |
| works well in noisy environments | hard to use in noisy environments |
| you need to develop versions of your software for a variety of mobile gateways | you only need to develop one version of your software |
| works well for displaying long lists of information | works poorly for giving the user long lists of information |
| user can enter arbitrary information | user can only say predefined phrases |
Figure 10.2:
One way to take advantage of the best of mobile and voice interfaces will be to develop multi-modal applications like the GPRS airline reservation system in the last chapter. A number of groups are actively developing specifications for multi-modal applications, including the Speech Application Language Tags (SALT) Forum (http://www.saltforum.org/).
Will all voice applications be VoiceXML applications? The current syntax of VoiceXML is geared at producing a user experience of navigating through hierarchical menus. State-of-the-art research is moving beyond this towards conversational systems in which any utterance makes sense at any time and where context is carried from exchange to exchange. For example, you can call the MIT Laboratory for Computer Science's server at 1-888-573-8255:
...
In the long run, as these more natural conversational technologies are perfected, the syntax of VoiceXML will have to grow to accommodate the full power of speech interpreters or be eclipsed by another standard.
The team should plan to spend one to two hours together designing the voice interface, but may divide the work of prototyping and refining the voice interface plus Exercises 5 and 6. A reasonable scope is eight to twelve programmer-hours.
The time required for client signoff will vary depending on the client's level of interest. Plan to spend at least thirty minutes on the signoff.