 | CGI Programming with Perl |  |

Now that we have a clearer understanding of URLs, let's return to the main focus of this chapter: HTTP, the protocol that clients and servers use to communicate on the Web.
The Secure Sockets Layer
HTTP is not a secure protocol, and many networking protocols (like ethernet) allow the conversation between two computers to be overheard by other computers on the same area of the network. The result is that it is very possible for a third party to eavesdrop on HTTP transactions and record authentication information, credit card numbers, and other important data.
Thus, Netscape developed the SSL (Secure Sockets Layer) protocol, which provides a secure communications channel that HTTP can operate across, while also providing security against eavesdropping and other privacy attacks. SSL has developed into an IETF standard and is now formally referred to as the TLS (Transport Layer Security) protocol (TLS 1.0 is essentially SSL 3.1). Not all browsers support TLS yet.
When your browser requests a URL that begins with https, it creates an SSL/TLS connection to the remote server and performs its HTTP transaction across this secure connection. Fortunately, you don't need to understand the details of how this works to write scripts, because the web server transparently manages it for you. Standard CGI scripts will work the same in a secure environment as in a standard one. When your CGI script receives a secure SSL/TLS connection, however, you are given additional information about the client and the connection, as we will see in the next chapter.
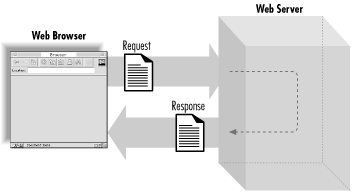
When a web browser requests a web page, it sends a request message to a web server. The message always includes a header, and sometimes it also includes a body. The web server in turn replies with a reply message. This message also always includes a header and it usually contains a body.
There are two features that are important in understanding HTTP:
It is a request/response protocol: each response is preceded by a request.
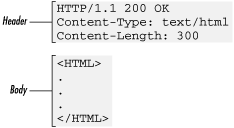
Although requests and responses each contain different information, the header/body structure is the same for both messages. The header contains meta-information -- information about the message -- and the body contains the content of the message.
Figure 2-2 shows an example of an HTTP transaction. Say you told your browser you wanted a document at http://localhost/index.html. The browser would connect to the machine at localhost on port 80 and send it the following message:
GET /index.html HTTP/1.1 Host: localhost Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/xbm, */* Accept-Language: en Connection: Keep-Alive User-Agent: Mozilla/4.0 (compatible; MSIE 4.5; Mac_PowerPC)
Assuming that a web server is running and the path maps to a valid document, the server would reply with the following message:
HTTP/1.1 200 OK Date: Sat, 18 Mar 2000 20:35:35 GMT Server: Apache/1.3.9 (Unix) Last-Modified: Wed, 20 May 1998 14:59:42 GMT ETag: "74916-656-3562efde" Content-Length: 141 Content-Type: text/html <HTML> <HEAD><TITLE>Sample Document</TITLE></HEAD> <BODY> <H1>Sample Document</H1> <P>This is a sample HTML document!</P> </BODY> </HTML>
In this example, the request includes a header but no content. The response includes both a header and HTML content, separated by a blank line (see Figure 2-3).
If you are familiar with the format of Internet email, this header and body syntax may look familiar to you. Historically, the format of HTTP messages is based upon many of the conventions used by Internet email, as established by MIME (Multipurpose Internet Mail Extensions). Do not be tricked into thinking that HTTP and MIME headers are the same, however. The similarity extends only to certain fields, and many early similarities have changed in later versions of HTTP.
Here are the important things to know about header syntax:
The first line of the header has a unique format and special meaning. It is called a request line in requests and a status line in replies.
The remainder of the header lines contain name-value pairs. The name and value are separated by a colon and any combination of spaces and/or tabs. These lines are called header fields .
Some header fields may have multiple values. This can be represented by having multiple header fields contain the same field name and different values or by including all the values in the header field separated by a comma.
Field names are not case-sensitive; e.g., Content-Type is the same as Content-type.
Header fields don't have to appear in any special order.
Every line in the header must be terminated by a carriage return and line feed sequence, which is often abbreviated as CRLF and represented as \015\012 in Perl on ASCII systems.
The header must be separated from the content by a blank line. In other words, the last header line must end with two CRLFs.
This chapter discusses HTTP 1.1, which includes several improvements to previous versions of HTTP. Although HTTP 1.1 is backward-compatible, there are many new features in HTTP 1.1 not recognized by HTTP 1.0 applications. There are even a few instances where the new protocol can cause problematic behavior with older applications, especially with caching. Most major web servers and browsers are now HTTP 1.1-compliant as this book is being written. There will continue to be HTTP 1.0 applications on the Web for some time, however. Features discussed in this chapter that differ between HTTP 1.1 and HTTP 1.0 will be noted.
|  | |
| 2. The Hypertext Transport Protocol |  | 2.3. Browser Requests |

Copyright © 2001 O'Reilly & Associates. All rights reserved.