 | CGI Programming with Perl |  |

Now that we have explored HTTP in general, we can return to our discussion of CGI and see how our scripts interact with HTTP servers to produce dynamic content. After you have read this chapter, you'll understand how to write basic CGI scripts and fully understand all of our previous examples. Let's get started by looking at a script now.
This script displays some basic information, including CGI and HTTP revisions used for this transaction and the name of the server software:
#!/usr/bin/perl -wT
print <<END_OF_HTML;
Content-type: text/html
<HTML>
<HEAD>
<TITLE>About this Server</TITLE>
</HEAD>
<BODY>
<H1>About this Server</H1>
<HR>
<PRE>
Server Name: $ENV{SERVER_NAME}
Listening on Port: $ENV{SERVER_PORT}
Server Software: $ENV{SERVER_SOFTWARE}
Server Protocol: $ENV{SERVER_PROTOCOL}
CGI Version: $ENV{GATEWAY_INTERFACE}
</PRE>
<HR>
</BODY>
</HTML>
END_OF_HTMLWhen you request the URL for this CGI script, it produces the output shown in Figure 3-1.
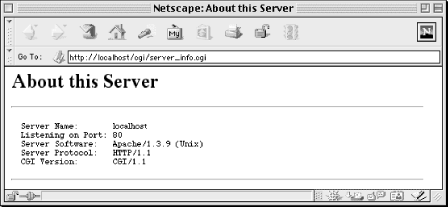
This simple example demonstrates the basics about how scripts work with CGI:
The web server passes information to CGI scripts via environment variables, which the script accesses via the %ENV hash.
CGI scripts produce output by printing an HTTP message on STDOUT.
CGI scripts do not need to output full HTTP headers. This script outputs only one HTTP header, Content-type.
These details define what we will call the CGI environment . Let's explore this environment in more detail.
CGI establishes a particular environment in which CGI scripts operate. This environment includes such things as what current working directory the script starts in, what variables are preset for it, where the standard file handles are directed, and so on. In return, CGI requires that scripts be responsible for defining the content of the HTTP response and at least a minimal set of HTTP headers.
When CGI scripts are executed, their current working directory is typically the directory in which they reside on the web server; at least this is the recommended behavior according to the CGI standard, though it is not supported by all web servers (e.g., Microsoft's IIS). CGI scripts are generally executed with limited permissions. On Unix systems, CGI scripts execute with the same permission as the web server which is generally a special user such as nobody, web, or www. On other operating systems, the web server itself may need to be configured to set the permissions that CGI scripts have. In any event, CGI scripts should not be able to read and write to all areas of the file system. You may think this is a problem, but it is actually a good thing as you will learn in our security discussion in Chapter 8, "Security".
Perl scripts generally start with three standard file handles predefined: STDIN, STDOUT, and STDERR. CGI Perl scripts are no different. These file handles have particular meaning within a CGI script, however.
When a web server receives an HTTP request directed to a CGI script, it reads the HTTP headers and passes the content body of the message to the CGI script on STDIN. Because the headers have already been removed, STDIN will be empty for GET requests that have no body and contain the encoded form data for POST requests. Note that there is no end-of-file marker, so if you try to read more data than is available, your CGI script will hang, waiting for more data on STDIN that will never come (eventually, the web server or browser should time out and kill this CGI script but this wastes system resources). Thus, you should never try to read from STDIN for GET requests. For POST requests, you should always refer to the value of the Content-Length header and read only that many bytes. We'll see how to read this information in Chapter 4, "Forms and CGI" in Chapter 4, "Forms and CGI".
Perl CGI scripts return their output to the web server by printing to STDOUT. This may include some HTTP headers as well as the content of the response, if present. Perl generally buffers output on STDOUT and sends it to the web server in chunks. The web server itself may wait until the entire output of the script has finished before sending it onto the client. For example, the iPlanet (formerly Netscape) Enterprise Server buffers output, while Apache (1.3 and higher) does not.
CGI does not designate how web servers should handle output to STDERR, and servers implement this in different ways, but they almost always produces a 500 Internal Server Error reply. Some web servers, like Apache, append STDERR output to the web server's error log, which includes other errors such as authorization failures and requests for documents not on the server. This is very helpful for debugging errors in CGI scripts.
Other servers, such as those by iPlanet, do not distinguish between STDOUT and STDERR; they capture both as output from the script and return them to the client. Nevertheless, outputting data to STDERR will typically produce a server error because Perl does not buffer STDERR, so data printed to STDERR often arrives at the web server before data printed to STDOUT. The web server will then report an error because it expects the output to start with a valid header, not the error message. On iPlanet, only the server's error message, and not the complete contents of STDERR, is then logged.
We'll discuss strategies for handling STDERR output in our discussion of CGI script debugging in Chapter 15, "Debugging CGI Applications".
|  | |
| 2.7. Summary |  | 3.2. Environment Variables |

Copyright © 2001 O'Reilly & Associates. All rights reserved.