 | Programming the Perl DBI |  |

The DBI is a database access module for the Perl programming language. It defines a set of methods, variables, and conventions that provide a consistent database interface, independent of the actual database being used.
It is important to remember that the DBI is just an interface. The DBI is a layer of "glue" between an application and one or more database driver modules. It is the driver modules that do most of the real work. The DBI provides a standard interface and framework for the drivers to operate within.
The API, or Application Programming Interface, defines the call interface and variables to Perl scripts to use. The API is implemented by the Perl DBI extension (see Figure A-1).
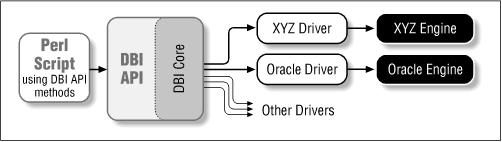
The DBI "dispatches" the method calls to the appropriate driver for actual execution. The DBI is also responsible for the dynamic loading of drivers, error checking and handling, providing default implementations for methods, and many other non-database-specific duties.
Each driver contains implementations of the DBI methods using the private interface functions of the corresponding database engine. Only authors of sophisticated/multi-database applications or generic library functions need to be concerned with drivers.
The following conventions are used in this document:
Database handle object
Statement handle object
Driver handle object (rarely seen or used in applications)
Any of the handle types above ($dbh, $sth, or $drh)
General return code (boolean: true=ok, false=error)
General Return Value (typically an integer)
List of values returned from the database, typically a row of data
Number of rows processed (if available, else -1)
A filehandle
NULL values are represented by undefined values in Perl
Reference to a hash of attribute values passed to methods
Note that Perl will automatically destroy database and statement handle objects if all references to them are deleted.
To use DBI, first you need to load the DBI module:
use DBI; use strict;
(The use strict; isn't required but is strongly recommended.)
Then you need to connect to your data source and get a handle for the connection:
$dbh = DBI->connect($dsn, $user, $password,
{ RaiseError => 1, AutoCommit => 0 });Since connecting can be expensive, you generally just connect at the start of your program and disconnect at the end.
Explicitly defining the required AutoCommit behavior is strongly recommended and may become mandatory in a later version. This determines if changes are automatically committed to the database when executed, or if they need to be explicitly committed later.
The DBI allows an application to "prepare" statements for later execution. A prepared statement is identified by a statement handle held in a Perl variable. We'll call the Perl variable $sth in our examples.
The typical method call sequence for a SELECT statement is:
prepare, execute, fetch, fetch, ... execute, fetch, fetch, ... execute, fetch, fetch, ...
For example:
$sth = $dbh->prepare("SELECT foo, bar FROM table WHERE baz=?");
$sth->execute( $baz );
while ( @row = $sth->fetchrow_array ) {
print "@row\n";
}The typical method call sequence for a non-SELECT statement is:
prepare, execute, execute, execute.
For example:
$sth = $dbh->prepare("INSERT INTO table(foo,bar,baz) VALUES (?,?,?)");
while(<CSV>) {
chop;
my ($foo,$bar,$baz) = split /,/;
$sth->execute( $foo, $bar, $baz );
}The do() method can be used for non-repeated, non-SELECT statements (or with drivers that don't support placeholders):
$rows_affected = $dbh->do("UPDATE your_table SET foo = foo + 1");To commit your changes to the database (when AutoCommit is off ):
$dbh->commit; # or call $dbh->rollback; to undo changes
Finally, when you have finished working with the data source, you should disconnect from it:
$dbh->disconnect;
The DBI does not have a concept of a "current session." Every session has a handle object (i.e., a $dbh) returned from the connect method. That handle object is used to invoke database-related methods.
Most data is returned to the Perl script as strings. (Null values are returned as undef.) This allows arbitrary precision numeric data to be handled without loss of accuracy. Beware that Perl may not preserve the same accuracy when the string is used as a number.
Dates and times are returned as character strings in the native format of the corresponding database engine. Time zone effects are database/driver-dependent.
Perl supports binary data in Perl strings, and the DBI will pass binary data to and from the driver without change. It is up to the driver implementors to decide how they wish to handle such binary data.
Most databases that understand multiple character sets have a default global charset. Text stored in the database is, or should be, stored in that charset; if not, then that's the fault of either the database or the application that inserted the data. When text is fetched, it should be automatically converted to the charset of the client, presumably based on the locale. If a driver needs to set a flag to get that behavior, then it should do so; it should not require the application to do that.
Multiple SQL statements may not be combined in a single statement handle ($sth), although some databases and drivers do support this feature (notably Sybase and SQL Server).
Non-sequential record reads are not supported in this version of the DBI. In other words, records can be fetched only in the order that the database returned them, and once fetched they are forgotten.
Positioned updates and deletes are not directly supported by the DBI. See the description of the CursorName attribute for an alternative.
Individual driver implementors are free to provide any private functions and/or handle attributes that they feel are useful. Private driver functions can be invoked using the DBI func() method. Private driver attributes are accessed just like standard attributes.
Many methods have an optional \%attr parameter which can be used to pass information to the driver implementing the method. Except where specifically documented, the \%attr parameter can be used only to pass driver-specific hints. In general, you can ignore \%attr parameters or pass it as undef.
The DBI package and all packages below it (DBI::*) are reserved for use by the DBI. Extensions and related modules use the DBIx:: namespace (see http://www.perl.com/CPAN/modules/by-module/DBIx/). Package names beginning with DBD:: are reserved for use by DBI database drivers. All environment variables used by the DBI or by individual DBDs begin with DBI_ or DBD_.
The letter case used for attribute names is significant and plays an important part in the portability of DBI scripts. The case of the attribute name is used to signify who defined the meaning of that name and its values, as the following table shows.
|
Case of Name |
Has a Meaning Defined By |
|---|---|
|
UPPER_CASE |
Standards, e.g., X/Open, ISO SQL92, etc. (portable) |
|
MixedCase |
DBI API (portable), underscores are not used |
|
lower_case |
Driver or database engine specific (non-portable) |
It is of the utmost importance that driver developers use only lowercase attribute names when defining private attributes. Private attribute names must be prefixed with the driver name or suitable abbreviation (e.g., ora_ for Oracle, ing_ for Ingres, etc.).
Here's a sample of the Driver Specific Prefix Registry:
ado_ DBD::ADO best_ DBD::BestWins csv_ DBD::CSV db2_ DBD::DB2 f_ DBD::File file_ DBD::TextFile ib_ DBD::InterBase ing_ DBD::Ingres ix_ DBD::Informix msql_ DBD::mSQL mysql_ DBD::mysql odbc_ DBD::ODBC ora_ DBD::Oracle proxy_ DBD::Proxy solid_ DBD::Solid syb_ DBD::Sybase tuber_ DBD::Tuber xbase_ DBD::XBase
Most DBI drivers require applications to use a dialect of SQL (Structured Query Language) to interact with the database engine. The following URLs provide useful information and further links about SQL:
http://www.altavista.com/query?q=sql+tutorial
The DBI itself does not mandate or require any particular language to be used; it is language-independent. In ODBC terms, the DBI is in "pass-thru" mode, although individual drivers might not be. The only requirement is that queries and other statements must be expressed as a single string of characters passed as the first argument to the prepare or do methods.
For an interesting diversion on the real history of RDBMS and SQL, from the people who made it happen, see:
http://ftp.digital.com/pub/DEC/SRC/technical-notes/SRC-1997-018-html/sqlr95.html
Follow the "And the rest" and "Intergalactic dataspeak" links for the SQL history.
Some drivers support placeholders and bind values. Placeholders, also called parameter markers, are used to indicate values in a database statement that will be supplied later, before the prepared statement is executed. For example, an application might use the following to insert a row of data into the sales table:
INSERT INTO sales (product_code, qty, price) VALUES (?, ?, ?)
or the following, to select the description for a product:
SELECT description FROM products WHERE product_code = ?
The ? characters are the placeholders. The association of actual values with placeholders is known as binding, and the values are referred to as bind values.
When using placeholders with the SQL LIKE qualifier, you must remember that the placeholder substitutes for the whole string. So you should use "... LIKE ? ..." and include any wildcard characters in the value that you bind to the placeholder.
Undefined values, or undef, can be used to indicate null values. However, care must be taken in the particular case of trying to use null values to qualify a SELECT statement.
For example:
SELECT description FROM products WHERE product_code = ?
Binding an undef (NULL) to the placeholder will not select rows that have a NULL product_code. (Refer to the SQL manual for your database engine or any SQL book for the reasons for this.) To explicitly select NULLs, you have to say "WHERE product_code IS NULL" and to make that general, you have to say:
... WHERE (product_code = ? OR (? IS NULL AND product_code IS NULL))
and bind the same value to both placeholders.
Without using placeholders, the insert statement shown previously would have to contain the literal values to be inserted and would have to be re-prepared and re-executed for each row. With placeholders, the insert statement needs to be prepared only once. The bind values for each row can be given to the execute method each time it's called. By avoiding the need to re-prepare the statement for each row, the application typically runs many times faster.
Here's an example:
my $sth = $dbh->prepare(q{
INSERT INTO sales (product_code, qty, price) VALUES (?, ?, ?)
}) || die $dbh->errstr;
while (<>) {
chop;
my ($product_code, $qty, $price) = split /,/;
$sth->execute($product_code, $qty, $price) || die $dbh->errstr;
}
$dbh->commit || die $dbh->errstr;See execute and bind_ param for more details.
The q{...} style quoting used in this example avoids clashing with quotes that may be used in the SQL statement. Use the double-quote like the qq{...} operator if you want to interpolate variables into the string. See the section on "Quote and Quote-Like Operators" in the perlop manpage for more details.
See also the bind_column method, which is used to associate Perl variables with the output columns of a SELECT statement.
|  | |
| A. DBI Specification |  | A.3. The DBI Class |

Copyright © 2001 O'Reilly & Associates. All rights reserved.