 | Programming the Perl DBI |  |

DBI Architecture
Handles
Data Source Names
Connection and Disconnection
Error Handling
Utility Methods and Functions
In this chapter, we'll discuss in detail the actual programming interface defined by the DBI module. We'll start with the very architecture of DBI, continue with explaining how to use the handles that DBI provides to interact with databases, then cover simple tasks such as connecting and disconnecting from databases. Finally, we'll discuss the important topic of error handling and describe some of the DBI's utility methods and functions. Future chapters will discuss how to manipulate data within your databases, as well as other advanced functionality.
The DBI architecture is split into two main groups of software: the DBI itself, and the drivers. The DBI defines the actual DBI programming interface, routes method calls to the appropriate drivers, and provides various support services to them. Specific drivers are implemented for each different type of database and actually perform the operations on the databases. Figure 4-1 illustrates this architecture.
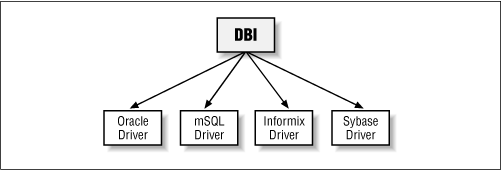
Therefore, if you are authoring software using the DBI programming interface, the method you use is defined within the DBI module. From there, the DBI module works out which driver should handle the execution of the method and passes the method to the appropriate driver for actual execution. This is more obvious when you recognize that the DBI module does not perform any database work itself, nor does it even know about any types of databases whatsoever. Figure 4-2 shows the flow of data from a Perl script through to the database.
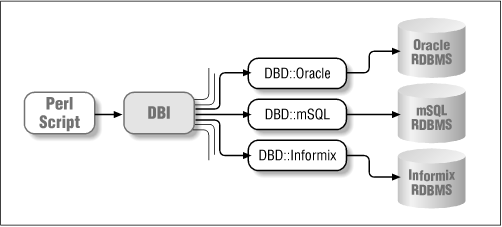
Under this architecture, it is relatively straightforward to implement a driver for any type of database. All that is required is to implement the methods defined in the DBI specification,[34] as supported by the DBI module, in a way that is meaningful for that database. The data returned from this module is passed back into the DBI module, and from there it is returned to the Perl program. All the information that passes between the DBI and its drivers is standard Perl datatypes, thereby preserving the isolation of the DBI module from any knowledge of databases.
[34]Few methods actually need to be implemented since the DBI provides suitable defaults for most of them. The DBI::DBD module contains documentation for any intrepid driver writers.
The separation of the drivers from the DBI itself makes the DBI a powerful programming interface that can be extended to support almost any database available today. Drivers currently exist for many popular databases including Oracle, Informix, mSQL, MySQL, Ingres, Sybase, DB2, Empress, SearchServer, and PostgreSQL. There are even drivers for XBase and CSV files.
These drivers can be used interchangeably with little modification to your programs. Couple this database-level portability with the portability of Perl scripts across multiple operating systems, and you truly have a rapid application development tool worthy of notice.
Drivers are also called database drivers, or DBDs, after the namespace in which they are declared. For example, Oracle uses DBD::Oracle, Informix uses DBD::Informix, and so on. A useful tip in remembering the DBI architecture is that DBI can stand for DataBase Independent and DBD can stand for DataBase Dependent.
Because DBI uses Perl's object-orientation features, it is extremely simple to initialize DBI for use within your programs. This can be achieved by adding the line:
use DBI;
to the top of your programs. This line locates and loads the core DBI module. Individual database driver modules are loaded as required, and should generally not be explicitly loaded.
|  | |
| 3.5. Creating and Destroying Tables |  | 4.2. Handles |

Copyright © 2001 O'Reilly & Associates. All rights reserved.