 | Programming the Perl DBI |  |

Atomic and batch fetching are two slightly more interesting ways of getting data out of your database. The two procedures are somewhat related to each other, in that they potentially make life a lot easier for you, but they do it in radically different ways.
When you want to fetch only one row, atomic fetching allows you to compress the four-stage data fetching cycle (as described earlier) into a single method. The two methods you can use for atomic fetching are selectrow_array( ) and selectrow_arrayref( ) . They behave in a similar fashion to their row-oriented cousins, fetchrow_array( ) and fetchrow_arrayref( ), the major differences being that the two atomic methods do not require a prepared and executed statement handle to work, and, more importantly, that they will return only one row of data.
Because neither method requires a statement handle to be used, they are actually invoked via a database handle. For example, to select the name and type fields from any arbitrary row in our megaliths database, we can write the following code:
### Assuming a valid $dbh exists...
( $name, $mapref ) =
$dbh->selectrow_array( "SELECT name, mapref
FROM megaliths" );
print "Megalith $name is located at $mapref\n";This is far more convenient than using the prepare() and execute() then the fetchrow_array( ) or fetchrow_arrayref( ) methods for single rows.
Finally, bind values can be supplied, which again helps with the reuse of database resources.
Batch fetching is the ability to fetch the entire result set from an SQL query in one call, as opposed to iterating through the result set using row-oriented methods such as fetchrow_array( ), etc.
The DBI defines several methods for this purpose, including fetchall_arrayref( ) and selectall_arrayref( ) , which basically retrieve the entire result set into a Perl data structure for you to manipulate. They are invoked against a prepared and executed statement handle.
fetchall_arrayref( ) operates in three different modes depending on what arguments have been passed to it. It can be called with no arguments, with a reference to an array slice as an argument, and with a reference to a hash slice as an argument. We'll discuss these modes in the following sections.
When fetchall_arrayref( ) is invoked with no arguments, it returns a reference to an array containing references to each row in the result set. Each of those references refers to an array containing the field values for that row. Figure 5-1 illustrates the data structure returned.
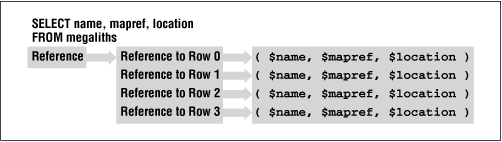
This looks pretty convoluted, but it is, in fact, extremely simple to access the data stored within the data structure. For example, the following code shows how to dereference the data structure returned by fetchall_arrayref( ) when run with no arguments:
#!/usr/bin/perl -w
#
# ch05/fetchall_arrayref/ex1: Complete example that connects to a database,
# executes a SQL statement, then fetches all the
# data rows out into a data structure. This
# structure is then traversed and printed.
use DBI;
### The database handle
my $dbh = DBI->connect( "dbi:Oracle:archaeo", "username", "password" , {
RaiseError => 1
});
### The statement handle
my $sth = $dbh->prepare( " SELECT name, location, mapref FROM megaliths " );
### Execute the statement
$sth->execute( );
### Fetch all the data into a Perl data structure
my $array_ref = $sth->fetchall_arrayref( );
### Traverse the data structure and dump each piece of data out
###
### For each row in the returned array reference ...
foreach my $row (@$array_ref) {
### Split the row up and print each field ...
my ( $name, $type, $location ) = @$row;
print "\tMegalithic site $name, found in $location, is a $type\n";
}
exit;Therefore, if you want to fetch all of the result set from your database, fetchall_arrayref( ) is an efficient and easy way of doing it. This is doubly true if you were planning on building an in-memory data structure containing the returned rows for post-processing. Instead of doing it yourself, you can simply use what fetchall_arrayref( ) returned instead.
It is also possible to use fetchall_arrayref( ) to return a data structure containing only certain columns from each row returned in the result set. For example, we might issue an SQL statement selecting the name, site_type, location, and mapref fields, but only wish to build an in-memory data structure for the rows name and location.
This cannot be done by the standard no-argument version of fetchall_arrayref( ), but is easily achieved by specifying an array slice as an argument to fetchall_arrayref( ).
Therefore, if our original SQL statement was:
SELECT meg.name, st.site_type, meg.location, meg.mapref FROM megaliths meg, site_types st WHERE meg.site_type_id = st.id
then the array indices for each returned row would map as follows:
name -> 0 site_type -> 1 location -> 2 mapref -> 3
By knowing these array indices for the columns, we can simply write:
### Retrieve the name and location fields... $array_ref = $sth->fetchall_arrayref( [ 0, 2 ] );
The array indices are specified in the form standard to Perl itself, so you can quite easily use ranges and negative indices for special cases. For example:
### Retrieve the second last and last columns $array_ref = $sth->fetchall_arrayref( [ -2, -1 ] ); ### Fetch the first to third columns $array_ref = $sth->fetchall_arrayref( [ 0 .. 2 ] );
The actual data structure created when fetchall_arrayref( ) is used like this is identical in form to the structure created by fetchall_arrayref( ) when invoked with no arguments.
The final way that fetchall_arrayref( ) can be used is to selectively store columns into an array reference by passing a hash reference argument containing the columns to store. This is similar to the fetchrow_hashref( ) method but returns a reference to an array containing hash references for all rows in the result set.
If we wished to selectively store the name and location columns from an SQL statement declared as:
SELECT name, location, mapref FROM megaliths
we can instruct fetchall_arrayref( ) to store the appropriate fields by passing an anonymous hash as an argument. This hash should be initialized to contain the names of the columns to store.
For example, storing the name and location columns can be written easily as:
### Store the name and location columns
$array_ref = $sth->fetchall_arrayref( { name => 1, location => 1 } );The data structure created by fetchall_arrayref( ) running in this mode is a reference to an array of hash references, with each hash reference keyed by the column names and populated with the column values for the row in question. Traversing this data structure is quite straightforward. The following code illustrates a technique to do it:
#!/usr/bin/perl -w
#
# ch05/fetchall_arrayref/ex3: Complete example that connects to a database,
# executes a SQL statement, then fetches all the
# data rows out into a data structure. This
# structure is then traversed and printed.
use DBI;
### The database handle
my $dbh = DBI->connect( "dbi:Oracle:archaeo", "username", "password" , {
RaiseError => 1,
} );
### The statement handle
my $sth = $dbh->prepare( " SELECT name, location, mapref FROM megaliths " );
### Execute the statement
$sth->execute( );
### Fetch all the data into an array reference of hash references!
my $array_ref = $sth->fetchall_arrayref( { name => 1, location => 1 } );
### Traverse the data structure and dump each piece of data out
###
### For each row in the returned array reference.....
foreach my $row (@$array_ref) {
### Get the appropriate fields out the hashref and print...
print "\tMegalithic site $row->{name}, found in $row->{location}\n";
}
exit;There are a couple of important points to be noted with this form of result set fetching:
If you have issued a SQL statement with multiple columns with the same name, the returned hash references will have only a single entry for all the columns. That is, earlier entries will be overwritten and lost. The same condition applies to fetchrow_hashref( ), since this method is what fetchall_arrayref( ) calls internally when given a hash slice.
An example piece of SQL that would cause problems is:
SELECT m.name, c.name FROM megaliths m, countries c WHERE m.country_id = c.id
In this case, the returned hash reference for the rows would contain either the country column values, or the megalith column values, but not both.
The second point regarding this use of fetchall_arrayref( ) is that the column names stored in the returned hash are always lowercase. The case that the database uses and the case used in the parameter to fetchall_arrayref( ) are ignored.
To sum up, batch value fetching is a convenient way to retrieve all the data in the result set into Perl data structures for future processing. Do keep in mind, though, that large results sets will eat large amounts of memory. If you try to fetch too large a data set, you will run out of memory before the method returns to you. Your system administrator may not be amused.
|  | |
| 5.5. do( ) Versus prepare( ) |  | 6. Advanced DBI |

Copyright © 2001 O'Reilly & Associates. All rights reserved.