 |  |

| |
In Chapter 2, "Introducing SAX2", Section 2.2.3, "XMLWriter: an Event Consumer" briefly discussed the concept of an XML pipeline. In that simple case, it involved reading, transforming, and then writing XML text. This concept is a powerful model for working with SAX; it is the natural framework for developing SAX components. These components won't usually be JavaBeans-style components, intended for use with graphical code builder tools, but they will still be specialized and easily reusable.
Exactly what is a SAX event pipeline? It's a series of components, each a pipeline stage connected so consumers act as producers for the next stage, as shown in Figure 4-1. The components pass events through, perhaps changing them on the fly to filter, reorganize, augment, or otherwise transform the data as it streams through. (The term filter is sometimes used to mean the same thing as a stage, though it's only one type of role for a stage.) The first producer could be a parser, or some other program component. The last consumer will probably have some defined output, such as XML text (XMLWriter), a DOM document (using the classes shown earlier), or an application-specific data structure. Intermediate stages in the pipeline have at least one pipeline stage as output, and they might produce other outputs such as data structures. Or they might only be used to analyze or condition the inputs to later stages.
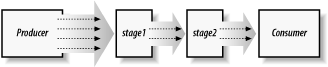
Pipeline stages can be used to create functional layers, or they can simply be used to define clean module boundaries. Some stages may work well with fragments of XML, while others may expect to process entire documents. The order in which processing tasks occur could be critically important or largely incidental. Stages can be application specific or general purpose. In addition to reading and writing XML, examples of such general-purpose stages include:
Cleaning up namespace information to re-create prefix declarations and references, replace old URIs with current ones, or give unqualified names a namespace.
Performing XSLT transformations.
Validating against an appropriate DTD or schema.
Transforming input text to eliminate problematic character representations. (Several recent W3C specifications require using Unicode Normalization Format C.)
Supporting the xml:base model for determining base URIs.
Passing data through pipeline stages on remote servers.
Implementing XInclude or similar replacements for DTD-based external entity processing.
Performing well-formedness tests to guard against sloppy producers (parsers won't need this).
More application-specific pipeline stages might include:
Performing validation using procedural logic with access to system state.
Collecting links, to support tasks such as verifying they all work.
Unmarshaling application-specific data structures.
Stripping out data that later processing must never see. For example, SOAP 1.1 messages must never include processing instructions or DTDs, and some kinds of XHTML rendering engines must not see <font> tweaks.
This process is different from how a work flow is managed in a data structure API such as DOM. In both cases you can assemble work-flow components, with intermediate work products represented as data structures. With SAX, those work-flow components would be pipelines; pipeline stages wouldn't necessarily correspond to individual work-flow components, although they might. With a data structure API, the intermediate work products must always use that API; with SAX they can use whatever representation is convenient, including XML text or a specialized application data structure.
Beyond defining the event consumer interfaces and how to hook them up to XML parsers, SAX includes only limited support for pipelines. That is primarily through the XMLFilterImpl class. The support is limited in part because XMLFilterImpl doesn't provide full support for the two extension handlers so that by default it won't pass enough of the XML Infoset to support some interesting tasks (including several in the previous lists).
In the rest of this section we talk about that class, XSLT and the javax.xml.transform package, and about a more complete framework (the gnu.xml.pipeline package), to illustrate one alternative approach.
You might also be interested in the pipeline framework used in the Apache Cocoon v2 project. Cocoon is designed for managing large web sites based on XML. One difference between the current Cocoon pipeline framework and the GNU pipeline framework is that Cocoon excludes the two SAX DTD-handling interfaces, making Cocoon pipelines unsuitable for tasks that need such DTD information. (Examples include DTD-based validation and parts of the XML Base URI specification that require detection of external entity boundaries.) At this writing, Cocoon 2.0 has just shipped its first stable release, ending its beta cycle.
The XMLFilterImpl class is new in SAX2, though a similar layer was in use on top of SAX1 parsers. Think of this class as a hybrid between an event consumer and an event producer, which can be used in either mode:
In its event consumer role, it's a base class that forwards events to another consumer. Callers push events through the filter, which postprocesses them. Subclasses would normally override methods for those events and invoke the superclass methods when they choose to pass them on (after postprocessing the data to be reported).
In its event producer role, it's a specialized XMLReader that registers itself as the consumer for a parent reader and delegates parsing to that parent. Callers pull data through the filter by calling parse(); it looks like a SAX parser that preprocesses Infoset data before reporting it.
When you subclass XMLFilterImpl, you'll primarily be concerned with its role as an event consumer because you'll be writing event handler code. The bulk of the work in a filter is event handling. When you need to filter DeclHandler or LexicalHandler events, it won't know how to handle them. You'll have to add code to handle those events; get the code to that SAX class, and follow the model used for ContentHandler support. The following code snippet shows how this is set up. It supports the producer side (parsing a document and automatically filtering its events). It also shows the consumer-side infrastructure, meaning events are normally passed through untouched, but subclasses will override methods to intercept events and change how they get handled:
public class ExtendedFilter extends XMLFilterImpl
implements LexicalHandler, DeclHandler
{
DeclHandler declHandler;
LexicalHandler lexicalHandler;
private static String declID =
"http://xml.org/sax/properties/declaration-handler";
private static String lexicalID =
"http://xml.org/sax/properties/lexical-handler";
public void setProperty (String uri, Object handler)
throws SAXNotRecognizedException, SAXNotSupportedException
{
if (declID.equals (uri))
declHandler = (DeclHandler) handler;
else if (lexicalID.equals (uri))
lexicalHandler = (LexicalHandler) handler;
else
super.setProperty (uri, handler);
}
// support producer mode operations
public void parse (InputSource in)
throws SAXException, IOException
{
XMLReader parent = getParent ();
if (parent != null) {
parent.setProperty (declID, this);
parent.setProperty (lexicalID, this);
}
super.parse (in);
}
// support consumer mode operations
public void comment (char buf [], int offset, int length)
throws SAXException
{
if (lexicalHandler != null)
lexicalHandler.comment (buf, offset, length);
}
// ... likewise for other LexicalHandler and DeclHandler methods
}When you're using such a filter just as a consumer, you'll have to register it as a handler for the event classes you're interested in, using methods like setContentHandler() as you would for any other event consumer. In such a case there's never any confusion about which XMLReader to use to parse since any filter component is only postprocessing.
When you use an XMLFilterImpl to produce events, you need to provide a parent parser, probably by using XMLFilter.setParent(). When you invoke parse(), the filter sets itself up to proxy all of the SAX core event handler methods (as shown earlier for one of the extension methods) as well as EntityResolver and ErrorHandler. You'll need to pay particular attention that you invoke the filter, instead of that "real" parser. It's easy to run into bugs that way, particularly if you're chaining multiple filters together. Although every filter stage has a parse() method, you only want to invoke it on the last postprocessing stage. It's easy to get confused about that.
Some XMLFilter implementations only operate in producer mode. That is unfortunate since it means that they only accept input like a parser; they can't be used to postprocess SAX events.
This book includes some examples that use XMLFilterImpl as a base class, supporting both filter modes:
Example 6-3 shows a custom handler interface, delivering application-specific unmarshaled data. This interface can be used either to postprocess or to preprocess SAX events, without additional setup.
Example 6-9 replaces processing instructions with the content of an included document so that downstream stages won't know about the substitution. When used to postprocess events, the handler may need to be set up with appropriate EntityHandler and ErrorHandler objects.
Sun is developing a "Multi-Schema Validator" engine, which uses SAX filters to implement validators for schema systems including RELAX (also called ISO RELAX), TREX, RELAX-NG (combining the best of RELAX and TREX), and W3C XML schemas. This work ties in to the org.iso_relax.verifier framework for validator APIs (at http://iso-relax.sourceforge.net), which also supports using SAX objects (such as filters and content handlers) that validate schemas.
If you're using RDDL (http://www.rddl.org) as a convention for associating resources with XML namespaces, you may find the org.rddl.sax.RDDLFilter class to be useful. It parses RDDL documents and lets you determine the various resources associated with namespaces, such as a DTD, a preferred CSS or XSLT stylesheet, or the schema using any of several schema languages. This is another "producer-mode only" filter.
The javax.xml.transform APIs provide ways to apply XSLT transforms to XML data. The top level APIs work with the "pull" model, and map one XML representation into another one with a Transformer.transform(source,result) call. Those representations can include XML text, DOM trees, or some kinds of SAX event streams. Except for that SAX support, you can look at the package as supporting three-stage pipelines, with the middle stage always XSLT (or else a null transform). The javax.xml.transform.sax APIs let you integrate XSLT into longer SAX pipelines in several ways, including one flexible pure "push" mode.
The SAXTransformerFactory class is important for most such pipeline usage. You could use code like this to set up to get a factory matching the code fragments shown later:
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.sax.*;
String stylesheetURI = ...;
String documentURI = ...;
ContentHandler contentHandler = ...;
LexicalHandler lexicalHandler = ...;
TransformerFactory tf
SAXTransformerFactory stf;
SAXSource stylesheet;
tf = TransformerFactory.newInstance ();
if (!tf.getFeature (SAXTransformerFactory.FEATURE)
|| !tf.getFeature (SAXSource.FEATURE))
throw new Exception ("not enough API support");
stylesheet = new SAXSource (new InputSource (stylesheetURI));
stf = (SAXTransformerFactory) tf;
Most Java XSLT engines, such as SAXON (available at http://saxon.sourceforge.net) and Xalan (available at http://xml.apache.org/xalan-j) fully support the additional SAX-oriented APIs, although that is not required.
The approach that's most flexible involves a TransformerHandler initialized to apply a specific XSLT transform. These are event consumer stages, set up to push their results through to other stages. They support only the ContentHandler, LexicalHandler and DTDHandler interfaces, but not DeclHandler. This is best used in conjunction with the SAXResult class, which packages both non-DTD SAX handlers so they can collect the output of a transform. After getting the factory as shown in the preceding code, make sure it supports SAXResult, then get and use the handler in a manner such as the following:
XMLReader producer;
SAXResult out;
TransformerHandler handler;
if (!tf.getFeature (SAXResult.FEATURE))
throw new Exception ("not enough API support");
handler = stf.newTransformerHandler (stylesheet);
out = new SAXResult ();
out.setContentHandler (contentHandler);
out.setLexicalHandler (lexicalHandler);
// no DTD support from the SAXResult class!!
handler.setResult (out);
producer = XMLReaderFactory.createXMLREader ();
producer.setContentHandler (handler);
producer.setDTDHandler (handler);
producer.setProperty ("http://xml.org/sax/properties/lexical-handler",
handler);
producer.parse (inputURI);
This style of usage is particularly well suited to XML pipelines. It's just a DTD-deprived pipeline stage, except that the output setup needs a non-SAX class. The reason that approach is particularly useful for pipeline processing is that both the input and output to the XSLT transform use SAX event streams, so it can easily be spliced between any two parts of an event pipeline. It also means you can use "push" mode event producers, which invoke SAX callbacks directly.
You can also get an pull-style API, using an XMLFilter that is initialized to apply a specific XSLT tran form. Such filters may be used as event producers, only at one end of a SAX pipeline. After getting the factory as shown in the previous code listing, you would make sure it supports this functionality, then get and use the filter like this.
XMLFilter producer;
if (!tf.getFeature (SAXTransformerFactory.FEATURE_XMLFILTER))
throw new Exception ("not enough API support");
producer = stf.newXMLFilter (stylesheet);
producer.setContentHandler (contentHandler);
producer.setProperty ("http://xml.org/sax/properties/lexical-handler",
lexicalHandler);
producer.parse (inputURI);
Such a call would use the XSLT stylesheet to preprocess input to the handlers you provide. The SAXResult class, shown here, supports a similar processing model. If your transformer can accept one of those, a pull-mode Transformer.transform() call pushes preprocessed results into a ContentHandler and LexicalHandler, like the XMLFilter.parse() call.
You can also use SAX in a pull-mode Transformer.transform() call by using a SAXSource object. That lets you provide an InputSource (as shown earlier) as well as an XMLReader, which may be set up with a particular ErrorHandler and EntityResolver (not shown). To use that in a SAX event pipeline, you can make that reader be an XMLFilter that preprocesses the input to the XSLT transform.
You can combine both SAXSource and SAXResult objects to get a kind of "pull" mode pipeline including one XSLT transform stage, without even needing to use the SAXTransformerFactory class. To get multiple XSLT transform stages without needing intermediate storage (XML text, a DOM tree, or so on), use the TransformerHandler class as shown earlier, postprocessing results through in a SAXResult. Or if you prefer, package an XMLFilter from a SAXTransformerFactory to preprocess data through a SAXSource that you provide to the Transformer.transform() call. (I recommend sticking to the pure TransformerHandler approach, since it's not as confusing.)
This framework takes a different approach to building pipelines than XMLFilterImpl or XMLFilter. Two key characteristics are its built-in support for all the SAX2 handlers, including the extension handlers, and its exclusive focus on the postprocessing model. In addition, it has several utility filters and some factory methods that can automate construction and initialization of pipelines. The core interface is EventConsumer:
public interface EventConsumer
{
public ContentHandler getContentHandler ();
public DTDHandler getDTDHandler ();
public Object getProperty (String id)
throws SAXNotRecognizedException;
public void setErrorHandler (ErrorHandler handler);
} With that interface, pipelines are normally set up beginning with the last consumer and then working toward the first consumer. There is a formal convention that states pipeline stages have a constructor that takes an EventConsumer parameter, which is used to construct pipelines from simple textual descriptions (which look like Unix-style command pipelines). That convention makes it easy to construct a pipeline by hand, as shown in the following code. Stages are strongly expected to share the same error handling; the error handler is normally established after the pipeline is set up, when a pipeline is bound to an event producer.
There is a class that corresponds to the pure consumer mode XMLFilterImpl, except that it implements all the SAX2 event consumer interfaces, not just the ones in the core API. LexicalHandler and DeclHandler are fully supported. This class also adds convenience methods such as the following:
public class EventFilter
implements EventConsumer, ContentHandler, DTDHandler,
LexicalHandler, DeclHandler
{
... lots omitted ...
// hook up all event consumer interfaces to the producer
// map some known EventFilters into XMLReader feature settings
public static void bind (XMLReader producer, EventConsumer consumer)
{ /* code omitted */ }
// wrap a "consumer mode" XMLFilterImpl
public void chainTo (XMLFilterImpl next)
{ /* code omitted */ }
... lots omitted ...
}
Example 4-4 shows how one simple event pipeline works using the GNU pipeline framework. It looks like it has three pipeline components (in addition to the parser), but in this case it's likely that two of them will be optimized away into parser feature flag settings: NSFilter restores namespace-related information that is discarded by SAX2 parser defaults (bind() sets namespace-prefixes to true and discards that filter), and ValidationFilter is a layered validator that may not be necessary if the underlying parser can support validation (in which case the validation flag is set to true and the filter is discarded). Apart from arranging that validation errors are reported and using the GNU DOM implementation instead of Crimson's, this code does exactly what the first SAX-to-DOM example above does.[22]
[22]There is a generic DomConsumer class that bootstraps using whatever JAXP sets up as the default DOM. Such a generic consumer can't know the implementation-specific back doors needed to implement all the bells and whistles DOM demands.
import gnu.xml.pipeline.*;
public Document SAX2DOM (String uri)
throws SAXException, IOException
{
DomConsumer consumer;
XMLReader producer;
consumer = new gnu.xml.dom.Consumer ();
consumer = new ValidationConsumer (consumer);
consumer = new NSFilter (consumer);
producer = XMLReaderFactory.createXMLReader ();
producer.setErrorHandler (new DefaultHandler () {
public void error (SAXParseException e)
throws SAXException
{ throw e; }
});
EventFilter.bind (producer, consumer);
producer.parse (uri);
return consumer.getDocument ();
}There are some interesting notions lurking in this example. For instance, when validation is a postprocessing stage, it can be initialized with a particular DTD and hooked up to an XMLReader that walks DOM nodes. That way, that DOM content can be incrementally validated as applications change it. Similarly, application code can produce a SAX event stream and validate content without saving it to a file. This same postprocessing approach could be taken with validators based on any of the various schema systems.
There are a variety of other utility pipeline stages and support classes in the gnu.xml.pipeline package. One is briefly shown later (in Example 6-7). Others include XInclude and XSLT support, as well as a TeeConsumer to send events down two pipelines (like a tee joint used in plumbing). This can be useful to save output for debugging; you can write XML text to a file, or save it as a DOM tree, and watch the events that come out of a particular pipeline stage to find problematic areas.
Even if you don't use that GNU framework, you should keep in mind that SAX pipeline stages can be used to package significant and reusable XML processing components.
|  | |
| 4.4. Turning SAX Events into Data Structures |  | 5. Other SAX Classes |

Copyright © 2002 O'Reilly & Associates. All rights reserved.