In this animation some type of model is used to control motion. The animator is responsible for setting up the rules of the model and animation is done by developing motion that corresponds to the rules of the model. Complex motion can be attained, but detailed control of the motion is removed from the hands of the animator.
Much model-based animation is based on physical principles since these are what give rise to what people recognized as 'realistic' motion. See the appendix on physics for a refresher on terminology and equations. However, other models can be used. Physically-based modeling is a special case of the more general constraint modeling. Arbitrary constraints can be specified by the user to enforce certain geometric relationships or relationships appropriate for a specific application area. Mental models can also produce animation based on action-reaction scenarios, problem solving and similar 'intelligent behavior'.
In the discussion that follows, a degree of freedom is any parameter that can be independently specified. The human body has over two hundred degrees of freedom. The orientation of a single rigid object in space has six degrees of freedom, three for position and three for orientation.
One of the simplest models to use in animation is that of linked appendages. Linked appendages naturally fall into a hierarchy that is conveniently represented by a tree structure. In such a representation, the nodes of the tree can be used to define body parts, such as torso, upper arm, lower arm, and hand. In the two-dimensional case, the data at a node is defined so that its point of rotation coincides with the origin.
Branching in the tree occurs whenever multiple appendages emanate from the same part. For example, in a simplified figure, the torso might branch into a neck, two upper arms and two upper legs.
Links in the tree representation hold transformations that take the body part as defined at the origin to its place relative on the body part one level up in the tree. Besides the static relative transformation at the link, there is also a changeable rotation parameter that controls the rotation at the specified joint.
Traversal of the tree produces the figure in a position that reflects the setting of all changeable rotation parameters. Traversal follows a depth first pattern. Essentially whenever a link is followed down the tree hierarchy, its transformations are concatenated to the transformations of its parent node. Whenever a link is traversed back up the tree, the transformation of that node must be restored before traversal continues. A stack of transformations is an efficient way to implement the saving and restoring of transformations as links are followed down and then back up the tree.
struct node {
object *obj;
trans_mat tm;
struct link *link_array;
int num_link;
} node
struct link {
trans_mat rot;
trans_mat pos;
struct node *nptr;
}
struct node root;
main
{
trans_mat TM;
set_ident_tm(TM);
eval_node(TM,root);
}
eval_node(tm,node)
trans_mat tm;
struct node node;
{
trans_mat temp_tm;
concat_tm(node->tm,tm,&temp_tm);
transf_obj(obj,temp_tm,&temp_obj);
display_obj(temp_obj);
for (l=0; l<no_link; l++) {
premul_tm(link_array[l]->rot,temp_tm);
premul_tm(link_array[l]->pos,temp_tm);
eval_node(temp_tm,link_array[l]->node);
}
}
To effect animation, the rotation parameters at the joints (the changeable rotations associated with the links) are manipulated. A completely specified figure position is called a pose. A pose is specified by a vector (pose vector) consisting of values for all joints. In a simple animation, a key position may be interactively determined by the user, followed by interpolation of joint rotations between key positions. Figure positioning by joint angle specification is call forward kinematics.
Unfortunately, getting the figure to a final desired position can be tedious for the user. Often times, it becomes a trial and error process. Enter inverse kinematics.
In inverse kinematics the problem is reversed in the sense that the desired position of the end effector (borrowing terminology from robotics) is given, and the joint angles required to attain that end effector position are calculated. For simple mechanisms, the joint angles can be analytically determined.
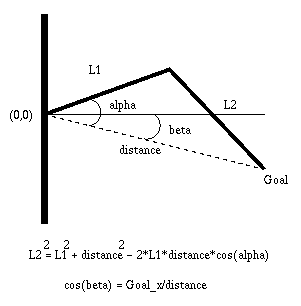
Consider a simple two-link arm in two-dimensional space. With link lengths L1 and L2 for the first and second link respectively and assuming a fixed position for the base of the arm at the first joint, any position beyond |L1-L2| of the base of the link and within L1+ L2 of the base can be reached. Assume for now (without loss of generality) that the base is at the origin. In a simple inverse kinematics problem, the user gives the (x,y) coordinate of the desired position for the end effector. The joint angles, theta1 and theta2, can be solved by considering computing the distance from the base and the goal, and then using the rule of cosines to compute the interior angles. Once the interior angles are computed, then the rotation angles for the two links can be computed.
In this simple scenario, there are only two solution that will give the correct answer; they are symmetric with respect to one another. However, for more complicated armatures, they may be infinitely many solutions that will give the desired end effector location. These are called redundant and are referred to as under constrained systems. Systems for which there is no solution are called over\constrained.
In robotics, where the next motion in time must be solved for, it is not the final set of joint angles that is solved for, but rather the change in joint angles that will give the end effector a step in direction toward the desired goal.
V = J*theta-dot
where V is the linear and rotational acceleration, theta-dot is a vector of joint angles and J, the Jacobian, is a matrix which relates the two and is a function of the current pose.
V = [ax,ay,az,wx,wy,wz]T
Theta = [ theta-1,theta-2,theta-3,...,theta-n]T
J = [ d(ax)/d(theta-1) d(ax)/d(theta-2) d(ax)/d(theta-3) ... d(ax)/d(theta-n)
d(ay)/d(theta-1) d(ay)/d(theta-2) d(ay)/d(theta-3) ... d(ay)/d(theta-n)
.
.
d(wz)/d(theta-1) d(wz)/d(theta-2) d(wz)/d(theta-3) ... d(wz)/d(theta-n)
In determining the Jacobian, the main thing to watch out for is to make sure that all of the variables are in the same coordinate system. It is often the case that joint specific information is specified in the coordinate system local to that joint. In compiling the Jacobian matrix, this information must be converted into some common coordinate system such as the global inertial coordinate system or the end effector coordinate system. Various methods have been developed for computing the Jacobian based on attaining maximum computational efficiency given the required information in specific coordinate systems.
Once the Jacobian has been computed, then the equation above must be solved. It is often the case, however, that the Jacobian is not a square matrix. It is n by 6 where n is typically greater than 6. In such cases, the pseudo-inverse of the Jacobian can be used thusly:
V-dot = J theta-dot
T T
J V = J J theta-dot
+ T -1 T T -1 T
J V = (J J) J V = (J J ) J J theta-dot = theta-dot
because a matrix multiplied by its own transpose will be a (square) n by n matrix. J+ is called the pseudo-inverse of J. .
The first animation system was actually the first graphics system: Sutherland's Sketchpad system. The system used a constraint solving system to maintain user-specified relationships among points and lines. As the user interactively manipulated a geometric element on the screen, the constraint solving system updated other geometric elements producing real-time animation.
In constraint languages, programming is a declarative task. The programmer states a set of relations between a set of objects, and it is the job of the constraint-satisfaction system to find a solution that satisfies these relations. Common computer languages, such as Pascal or C, are imperative computer languages in which a program is specified as a step-by-step procedure. There is an identifiable flow of execution that can be followed as defined by the steps, once the specific input is known.
The advantage of a constraint language, vis a vis an imperative language, is that once the set of relations has been specified, any of the objects can be solved for if the others are given (assuming the set of relations is sufficient to determine the unknown object). In an imperative language, different step sequences have to be specified for each possible problem to be solved. A constraint language has an equality operator, that specifies a relationship that must hold, instead of an assignment operator. which specifies an action that must be taken.
The descriptive nature of constraint languages makes it easy to describe problems, which is one of their major advantages, but is also makes it tempting to consider it a general-purpose problem solver, which it is not. They are no even as powerful as many mechanical problem solvers, such as symbolic-algebra systems.
Constraint satisfaction, like most techniques for solving problems, is composed of two distinct parts: as set of problem-solving rules, and a control mechanism. The problem-solving rules can be fairly general-purpose, such as the rules of arithmetic and algebra, or they can be more application-specific. The control mechanism controls when and how the rules are applied.
A constraint-language program can be regarded as a graph. Objects (variables) are represented as one type of node and operators are represented by another type of node. Operator nodes specify relation ships between objects and, possibly, constants.
The simplest and easiest-to-implement constraint-satisfaction mechanism is call local propagation of known states. In this mechanism, known values are propagated along the arcs. When a node receives sufficient information from its arcs, it fires - calculates one or more values for the arcs that do not contain values, and sends these new values out. These new values then propagate along the arcs, causing new nodes to fire, and so on. The problem-solving rules are local to each node, and only involve information contained on t he arcs connected to that node.
The major disadvantage of local-propagation techniques is that they can only use information local to a node. Many common constraint problems cannot be solved this way, for example, when the constrain graph contains cycles. One method that can solve problem which are beyond the scope of local-propagation is a classical iterative numerical-approximation technique called relaxation. Relaxation makes an initial guess at the values of the unknown objects, and then estimates the error that would be caused by assigning these values to the objects. New guesses are then made, and new error estimates calculated, and this process repeats until the error is minimized. To make relaxation more efficient, it is usually wise to prune branches of graph away that can be satisfied by local propagation, thus isolating the part that really needs relaxation to be solved.
There are other approaches in simplifying the problem before relaxation. These include keeping redundant views of subproblems and graph transformation. Both of these allow for branch substitutions which may remove cycles in the constrain graph. Augmented term rewriting is another mechanism which can be used.
So far we haven't made any mention of computer graphics or computer animation. It should be apparent, however, how such constraint programming languages can be used to specify relationships among geometric elements. This has been used in data generation programs for computer graphics [Brunerlin (sp?)]. It can also be used to produce animation. In fact, all of the model based techniques to be covered in the rest of the section are really types of constraint systems. An set of constraints are specified and then one or more elements are manipulated over time. The animation is produced as the constraint solver repeatedly calculates parameters for the remaining geometric elements such that the prespecifed constraints are satisfied. This was at the heart of Sutherland's system mentioned at the beginning of this section. For example, mechanical structures such as gears and levels can be animated by setting up the constraints which reflect a certain organization of these elements. User manipulation of a flywheel, for example, would then animation the mechanism as the physical structure constraints are solved.
A ridig body is one that does not undergo distortion as a result of forces applied to it. The motion of such bodies is given to us by Newtonian mechanics. This material is also important for understanding the animation of linked appendages.
Assume an object's velocity can be described by a vector V such that its speed is V's magnitudein terms of distance-units/frame. Further, assume that at frame F0 the object's position is defined by P0. At frame F1 the position will be
P1 = P0 + V *(F1-F0)
Of course if the speed is given in distance-units per second then it must be multiplied by the number of frames per second. This assumes that there is a constant velocity, i.e., no acceleration.
This assumes a constant acceleration over the time period. Its position at P1 would be:
P1 = P0 + V0 *(F1-F0) + 1/2*A*(F1-F0)2
This assumes a constant acceleration during the time period. The equations can be derived from calculus; assume v(0) = 0 and s(0) = 0.
a(t) = v'(t) = s''(t) = g v(t) = s'(t) = gt s(t) = 1/2*g*t2
If there is an acceleration, described for example by a vector A, then it's velocity at frame F1 would be:
V1 = V0 + A*(F1-F0)
where V0 is its initial velocity at frame F0 and V1 is its new velocity at frame F1. The velocity that is represented here is linear velocity.
Objects can also undergo angular velocity. In two dimensions, uniform circular motion can be described by:
P(Ż) = (r*cosŻ)i + (r*sinŻ)j
where P(Ż) is the position vector of a point as a function of theta. In uniform circular motion, the polar angle Ż changes at a constant rate so that the time derivative of Ż is a constant:
w = dŻ/dt
By integration, we get
Ż = w*t + §
where § is the value of Ż at time t = 0. Assuming Ż = 0 at time t = 0, uniform circular motion can be described by
P(Ż) = (r*cos (w*t) )i + (r*sin (w*t) )j
The velocity of the object at any instant is the derivative of the position vector:
v(t) = dP/dt = (-r*w*sin(w*t))*i + (r*w*cos(w*t))*j
Notice that the instantaneous velocity vector is perpendicular to the position vector. This is true for any circular motion whether or not it is uniform.
In three-dimensions, angular velocity is represented by a vector with magnitude. A point at P0, relative to a point on the axis of rotation, has an instantaneous velocity induced by angular velocity, W, of
V = W x P0
A point's new position can be described as:
P1 = P0*R(Ćt*|W|)
where R(Ż) is the rotation matrix for points about the axis of rotation, W.
Even uniform circular motion gives rise to acceleration because the velocity vector, by virtue of the fact that it is always perpendicular to the position vector, is always changing. By differentiation, it is easy to show
a(t) = -w2p(t)
which shows that a rotates around with r, always pointing radially inward, and is an example of centripetal accelearion.
For more realistic physically based modeling, gravity and reaction to collisions can be incorporated into an object's motion. Note that this further removes detailed control from the hands of the animator. Newton's Laws of Motion can be used to control an object's motion. In particular, f=ma relates forces applied to an object's acceleration. If a constant force is being applied to an object we can simply determine its acceleration and apply the equations above.
Acceleration due to the earth's gravity can be approximated by a constant acceleration, g, that is 32 m/sec2. Given an object's initial position (i.e., height) and the assumption that it was at rest at time t=0, then for any point in the future time we can plug the time into the equations above to get its acceleration, velocity and distance that it's fallen.
V(t1) = V(t0) + A*(t1-t0) P(t1) = P(t0) + V(t0)*(t1-t0) + (1/2)*A*(t1-t0)2
Gravity between two objects is a known force. To incoporate forces, such as gravity between objects, into an animation an object's mass must be known, or given by the user, so that the acceleration due to the force can be calculated. In the case of two objects with comparable masses, M1 and M2, the force of gravity between two masses is given by:
F = G*M1*M2/D2 where G = 6.67x10-11, a universal constant D = distance between centers of mass M1 = mass of object 1 M2 = mass of object 2
If one assumes objects with homogenouse distributions of mass and if the object is symmetric, such as a cube or a sphere, then the center of the object can be used as the center of mass. In more complex objects, the average of all vertices can be used to approximate the center of mass, although this has some obvious shortcomings.
Given the masses of two objects, then, the gravitational force between them can be calculated. Acceleration can be solved for by invoking:
A = F/M
At a given instance, we use the distance between two objects to calculate the gravitational force which in turn gives us the instantaneous acceleration. Acceleration, by definition is the change in velocity so we can add the acceleration to the current velocity of the object to come up with the object's new velocity. Notice that these are vector quantities, having a direction as well as a magnitude.
This brings up an interesting issue which plagues simulations of motion. We can calculate the instantaneous acceleration of both objects for any time t0. If we use this acceleration to calculate the new velocity at the next time step we are implicitly assuming that the calculated acceleration is constant over the time interval. In the case of gravitational fields this is not the case! The force due to gravity is constantly changing because the distance between the centers of mass is constantly changing and, therefore, the acceleration induced by the force of gravity is constantly changing. The assumption of constant acceleration is only reasonable for relatively short time steps for given masses and distance between them. This is an important point to remember because this assumption and its ramifications raise their ugly heads throughout physically-based modeling.
Modeling the effect of gravity on objects helps give the impression of weight but, by itself, would produce pretty boring animations - everything would simply fall downward. What makes it possible for things to be built in the real world is that fact that things are solid and objects can't pass through one another. Incorporating collision detection and collision response is one of the more realistic aspects of physically based modeling. This has two interesting aspects to it. First, it really dictates that the motion of the environment cannot be laid out beforehand. Objects can now interact at unforeseen times and may respond in unforeseen ways. This is one of the fundamental features of model-based animation. The second aspect is that of the sampling problem. Time in computer graphics is descrete and most collision detection takes place at descrete intervals. This means that it is possible to miss a collision alltogether and certainly probable that it won't be detected at the instant of contact. This complicates collision response processing.
First, lets take a look at a simplified case: the colliding of two balls in space. We will assume for now that neither is spinning. In order to determine the outcome of such a collision, we must invoke the principle of the conservation of momentum. Momentum is mass times velocity. Without loss of generality, we can assume one of the balls is initially at rest. The other ball has velocity v. The momentum of the system before collision is
m*v
This must be equal to the momentum after the collision. We will also assume that the masses don't change as a result of the collition, so we have:
m*v= m*v1 + m*v2
So far, one equation and two unknowns.The other principle which must be invoked is the conservation of energy. Here we are conserned with kinetic energy which is defined as:
K = (1/2)*m*v2(t)
We will also assume that there is no heat dissipated in the collision, i.e., the collision is elastic; if some kinetic energy is transformed into heat, the collision is called inelastic. We use the fact that kinetic energy before and after the collision must be conserved to get:
(1/2)*m*v2 = (1/2)*m*v12+ (1/2)*m*v22
so
v = v1 + v2 v2 = v12 + v22
The former equation tells us that v is the vector sum of v1 and v2, i.e., they form a triangle. The latter equation tells us that they obey the Pythagorean theorem, so v1 is perpendicular to v2. If the collision is head-on, then v1 = 0 and v2 = v. If the moving ball missed the other ball, then v1 = v and v2 = 0.
The collision is uniquely specified if one of the angles is given, or if the magnitude of one of the resulting momentums is given. Normally, the angle one of the balls is leaving can be determined by the point of impact of the two balls. The only thing left to do is to calculate the time at which the collision takes place which, for this case, can be done analytically with no problem.
Now let's look at another common problem: ground plane collisions of spheres under the force of gravity. Since gravity is the only force acting on objects, it is easy to calculate their acceleration. Given their initial position and velocity, one can analytically determine the time at which they will impact a ground plane. The impact will exert a force upward. If the collision is totally elastic, then the resulting velocity vector of the ball will simply have its y component (assuming that's 'up' in our coordinate system) negated. This same idea holds if collisions with walls are being modeled with no gravity; the velocity vector is reflected about the plane of contact.
General collisions are determined by object-object intersection calculations. In simple cases, such as simple translation of a polyhedral object in an otherwise static environment, collisions can be determined analytically. In general, however, analytic solutions are not possible for collisions of arbitratry objects undergoing arbitrary transformations. Typically at each time step, an object-object intersection test has to be performed for each pair of objects. In order to reduce the calculations involved, bounding box tests, sorted lists of objects, and spatial bucket sorts can be used to quickly determine non-intersection cases.
However, such descrete sampling still presents problems. First of all, it's possible to miss an intersection altogether if small objects moving fast with respect to sampling interval. One way to prevent this is to use a larger bounding box for a fast moving object. This will help alert the algorithm of a possible intersection.
Even when collisions are detected they are typcially not detected exactly at the moment of impact. In complicated environments were collisions in rapid succession are possible, such as in bowling or billiard simulations, handling impacts precisely may be important. One solution is to'back up' the simulation to the first point of contact. This will probably occur in the middle of a time step and can be computationally costly if there are many collisions requiring repeated time step suspention. The alternative is to acknowledge that the actual point in time that the collision happened has already been missed and just introduce a correction factor at the next time interval. For example, a tight spring can be used to model collision interaction. Springs exert forces according to Hook's Law:
F = -Kx
where x is the distance of displacement from the resting position and K is the spring constant. The farther one object is through another at a particular time step, then the more force will be exerted by the spring mechanism. This may be feasible for simple environments or in simulations which do not have to be precise.
Complicated motion of an object involving rotation is dealt with easier if we divide the problem into mostion of the center of mass and a rotation about the center of mass. It should be easy to understand that the center of mass of a system of masses m1, m2,...,mn at positions p0, p1, ...,pn is:
p = (1/M)*·mi*pi
where M = ·mi is the total mass of the system. In graphics, the vertices defining the geometry of an object are often used as a finite collection of mass points which are used to calculate the center of mass. In the continuous case of the mass being distributed along a plane or throughout a volume, the center of mass is defined by integrals rather than sums.
The center of mass of a uniform region (constant mass density) lies on any line which is an axis of symmetry of the region. A region that is the union of two non-overlapping reagions has its center of mass on a line joining the center of masses of the two regions. Using these principles in repeated applications can often times determine the center of mass uniquely without evaluating the integrals or resorting to using the vertices as mass points.
Consider a rigid body rotating about a fixed axis with angular speed w. A particle of mass m, situated at radius r and circulating with speed v about it has angular momentum:
L = r*(m*v)
about a point on the axis. Since v = wr for rotation about the axis:
L = m*r2*w
Summing over all particles in the body, we obtain the total angular momentum of the body about the axis of rotation:
L = ·mi*ri2*w
since in a rigid body all particles have the same angular speed w. The coefficient of w is called the moment of inertia.
I = ·mi*ri2 L = Iw
Of course, for objects which have mass distributed continuously through some chunk of space, the summation turns into an integral. More generally, the distribution of mass for symmetrical objects requires three moments of inertia, one about each axis:
Ix = ş(y2+z2)dm Iy = ş(x2+z2)dm Iz = ş(x2+y2)dm
i.e., the sum of the masses of each partical making up the object (dm) multiplied by the square of its perpendicular distance from the axis. For standard objects, there are simple formulas for calculating these moments of inertia. For example, a box centered at the origin with width a in x, b in y, and c in z, centered around the origin, has moments:
Ix = m/12*(b2+c2) Iy = m/12*(a2+c2) Iz = m/12*(a2+b2)
Often, these moments for a bounding box are used for arbitrary objects.
For non-symmetrical object, calculate the three products of inertia.
Ixy = şxy dm Ixz = şxz dm Iyz = şyz dm
These moments and products of inertia are usually arranged in a 3x3 inertial tensor matrix for use in the equations of motion:
Ix -Ixy -Ixx Jk = -Ixy Iy -Iyz -Ixz -Iyz Iz
Products and moments of inertia can be transformed between coordinate systems. [Include equations for translating and rotating the products and moments]
Spheres are handy to use because they are radially symmetric. That means that collisions are easy to calculate, the center of mass is the geometric center of the sphere and most forces can be accurately modeled by assuming they are applied on the center of mass.
However, for arbitrary polyhedra, such is not the case. Collisions are not only difficult to detect, but the response to collisions and applied forces in general are more difficult to model because one can no longer get by with the assumption that a force is always applied to the center of mass. The mass of an object is arbitrarily distributed throughout its volume. When a force is applied to an object at a specific point (as opposed to, say, gravity), if that point is offset from the center of mass of the object with respect to the direction of the force, then angular acceleration is induced. If a force vector F is applied at point p offset from the center of mass of the object by vector r, then the torque is:
N = r x F
Remeber that vectors must be expressed in same coordinate system. Forces are usually given in a world coordinate system whereas we often want rigid body motion in terms of its body-fixed frame.
If multiple forces and torques are acting on a body, the net linear force and net torque can be found by using the equation above and summing. This effectively removes the torque component from the linear force.
The problem statement is as follows. Given the current position, orientation, linear velocity and angular velocity of an object, and an applied force to some point on the object, calculate the object's new position, orientation and velocities at some next time step.
The linear force can be applied to the center of mass of the object with the familiar f=ma to get the acceleration produced by the given force. The acceleration can then be used, as previously described, to get the new linear velocity and position for the center of mass.
The torque produced by the applied force is used to calculate the angular acceleration. If the products of inertia are zero and either the local frame is at the center of mass or the origin of the local frame is fixed in world space, then
Nx = Ixw'x + (Iz - Iy) wywz Ny = Iyw'y + (Ix - Iz) wxwz Nz = Izw'z + (Iy - Ix) wxwy
where N is the torque as calculated from the applied force, I is the moment of inertia calculated from the mass distribution of the object, w is the angular velocity in the current time step (initially zero, for example) and w' is the unkown, the angular acceleration. The w' can be easily solved for and then used to update the angular velocity for the next time step and to calculate the new orientation of the object.
If the above conditions are not met, the more general form of the equations are:
fx = m*(ax-cx*(wy2 + wz2) + cy*(wy*wx - wz') + cz*(wx*wz + wy') fy = m*(ay+cy*( wx*wy + wz') - cy*( wx2 + wz2 ) + cz*(wy*wz - wx') fz = m*(az+cx*( wx*wy + wy') - cy*( wy*wz + wx' ) - cz*( wx2 + wy2 ) Nx = m*(az*cy - ay*cz) + Ixwx' + (Iz - Iy)*wy*wz + Ixy*(wx*wz - wy') - Ixz*(wx*wy + wz') + Iyz*(wz2 - wy2) Ny = m*(ax*cz - az*cx) + Iywy' + (Ix - Iz)*wz*wx + Iyz*(wy*wx - wz') - Ixy*(wy*wz + wx') + Ixz*(wx2 - wz2) Nz = m*(ay*cx - ax*cy) + Izwz' + (Iy - Ix)*wx*wy + Ixz*(wz*wy - wx') - Iyz*(wz*wx + wy') + Ixy*(wy2 - wx2)
Standard numerical techniques can be used to solve the system of equations. The present position and velocities are known, and the linear and angular accelerations are unknown. This gives us six equations and six unknowns. Methods such as Runge-Kutta can be used to numerically integrate the equations.
[Need to get simulation of friction - balancing blocks paper?]
Some objects are not rigid structures. They exhibit flexibility. Physically, this means that when forces are applied to them at a point, the effect propagates through the object in some non-uniform manner. A simple way to simulate flexible body motion is to model the object as a collection of mass points connected by springs. A simplifying assumption is that, in a polyhedral model, all vertices are points of equal mass and all edges are springs with the same spring constant. The initial lenghts of the edges are used as the equilibrium lengths of each spring.The user has to specify a single mass and a single spring constant.
When a force is applied at a point on an object, such as due to a collision with another object, the entire force can be concentrated at one vertex and then propagated throughout the object by the spring network. Alternatively, if the object collides face on, for example, the force can be distributed equally to all vertices of a face. In either case, there is an initial set of vertices to which the force is applied at the start of the simulation. At the next simulation time step (which may or may not be equal to the animation time step), the forces induce an acceleration of the initial vertex set which then displace them relative to their neighboring vertices. This can either expand or contract the springs which connect the vertices and that, in turn, induces restoring forces exerted on the vertices connected to the springs. At the next time step, more vertices have forces acting on them, more vertices get displaced and more vertices have forces applied to them as a result of spring restoration forces. Thus the initial force applied at a vertex or face of an object propagates through the vertex-edge connectivity of the object.
For each mass element, F=ma is solved for the acceleration. This acceleration is assumed constant during the sub-frame time interval (Ćt) and a forward finite difference method is used to integrate the acceleration for the velocity and position. Euler differencing can be used:
v(t+Ćt) = v(t) + a(t)*Ćt x(t+Ćt) = x(t) + v(t)*Ćt
The fewer sub-frame time steps we take, the faster the simulation runs. This puts an upper bound on the vibrational frequencies of the objects we can simulate. In order for the simulation to remain stable, we must take steps small enough to sample the system at more than twice the highest natural vibrational frequency.
The spring element is assumed to perfectly obey Hooke's law which states that the force, F, exerted by a spring at its end points is linearly proportional to the displayment, x, fo the length of the spring from some equilibrium length:
F = -Kx
The Hinge element is responsible for maintaining the shape of the surface of the object. The object is modeled as connected triangles. Along the shared edge of two adjacent triangles we define a hinge element which acts upon the four masses to maintain an equilibrium angle between the normals of the two triangles. The hinge is assumed to follow an analogous statement of Hooke's law for angular displacement:
T = -KS
where T is the hinge torque magnitude, S is the angular displacement of the hinge from equilibrium, and K is the hinge constant. Given the angular displacement, S, of the normals, we compute the torque (T') produced by the hinge about the hinge axis. We apply this torque to the outlying (off axis) masses in the form of forces derived from the following vector equations, each of which is three equations in three unknowns (x,y,z components). The forces are applied in a direction parallel to the normal of each triangle.
T' = R1' x F1 -T' = R2 x F2
where T' is the torque about the hinge axis, R1' and R2' are perpendicular rays from the hinge axis to the outlying masses, F1 and F2 are the forces applied normal to the triangles at the outlying (off axis) masses (call them mass 1 and mass 2), and x means vector cross product.
In order to uphold the conservation laws, we must now apply 'balancing' forces to the masses on the hinge axis (call them mass 3 and mass 4). To compute these forces we must find the location of the center of mass of the hinge system, locate the masses relative to the center of mass and solve the linear and angular conservation equations (6equations in 6 unknowns) for the forces F3 and F4 to apply to the hinge axis masses 3 and 4:
(R1xF1) + (R2xF2) + (R3xF3) + (R4xF4) = 0.0 F1 + F2 + F3 + F4 = 0.0
where Ri is the position of mass 'i' relative to the center of mass of the hinge system, Fi is the force to be applied to mass i, and x is the vector cross product. However, if the center of mass of the hinge system falls close to the midpoint of the hinge axis we can ignore the calculations needed to satisfy the conservation of angular momentum. In these cases we approximate F3 and F4 by the negative of the average of F1 and F2 and satisfy conservation of linear momentum only. This approximation works especially well for flat sheets approximated by equilateral triangles.
The aerodynamci drag element allows the model to account for air friction. It also assumes a triangulated surface representation as defined for the hinge. This element approximates the velocity, area, and orientation of the triangular surface and approximates the force of air friction on the surface. The aerodynamci drag force, D, experienced by a body is defined by the following formula:
D = .5CpV2A
where D is the force of aerodynamic drag, Cis the coefficient of drag, p is the density of the surrounding air, Vis the velocity relative to the air (relative wind), and A is the cross-sectional area. We simplify this relationship by merging the coefficient of drag and air density (assumed constant) into a single parameter. In reality, the coefficient of drag, C, of an object varies with its orientation to the relative wind. Again, we simplify and assume a constant C. The cross-sectional area is the true area times the cosine of the angle between the velocity vector and the surface normal. This simplified product is then assumed to be the aerodynamic drag on the object. This force is evenly distributed to the vertex masses of the triangle. The air is currently represented as a constant velocity field. An improved model would stochastically represent both the velocity and the density at all points in space.
The special case in which a flexible material slides over the surface of a character. The normal problems in animation flexible materials are exacerbated because of the near-constant contact (i.e., collisions) that occur between the clothing material and the underlying support.
One popular approach to producing animation is to have elements obeying rules which govern their behavior. There are usually three classes of techniques which are discussed in the literature depending on the number of elements being controlled and the sophistication of the control strategy: particle systems, flocking, and autonomout behavior. See the table below for a comparison of some generalizations made about these techniques.
| type of animation | participants | intelligence | physics-based? | collision | control |
|---|---|---|---|---|---|
| particle systems | many | none | yes | detect & respond | force fields |
| flocking | some | some | some | avoidance | global tendency |
| behavioral | few | high | no | avoidance | rules |
A couple things are worth noting. First, these categories really represent a continuum of techniques possible. There is no magic number of elements above which a system would be called a particle system and below which would be called flocking. These categories are just general terms which have found their way into the literature. Second, nothing prevents someone from mixing and matching attributes. For example, for a given effect, it would be prefectly reasonable to create a system just a few elements which respond according to simple physical principles.
Particle systems and flocking systems can be characterized by emergent behavior: a global effect generated by local rules. For example, one can speak of a flock of birds having a certain motion even though there is not any control specific to the flock as an entity.
Much of the following discussion is taken from Reeves' paper on particle systems.
A particel system is a large collection of which, taken together, represent a fuzzy object. Because there is typcially a large number of particles, simplifying assumptions are used in rendering them and in calculating their motions. Different authors make different simplifying assumptions. Some of the common assumptions made are:
Particles are often modeled as having a finite life-span so that during an animation there may be hundreds of thousands of particles used, but only thousands active at any one time. In order to avoid excessive orderliness, randomness is introduced into most of the modeling and processing of particles. In computing a frame of motion for a particle system, the following steps are taken:
Particle generation: Particles are generated according to a controlled stochastic process.
One method is to, at each frame, generate a random number using some distribution distribution centered at the desired average number of particles per frame with a desired variance. The distribution could be uniform or Gaussian or whatever:
where Rand() returns a random number from -1.0 to +1.0 in the desired distribution.
A second method is to use the screen size of the fuzzy object to control the number of particles generated.
Of course, the average-number and variance could be function of time to enable more control over the particle system by the animator.
Particle attributes: The attributes of a particle determine it's motion status, its appearance, and its life in the particle system. Typical attributes are:
Each of the attributes are initialized when the particle is created. Again, to avoid uniformity, values are typcially randomized in some controlled way. The position and velocity are updated according to the objects motion. The shape parameters, color, and transparency control the objects appearance. The lifetime attribute is a count of how many frames the particle will exist.
Particle termination: At each new frame, each particles lifetime attribute is decremented by one. When the attribute reaches zero, the particle is removed from the system.
Particle animation: Typcially, each active particle in a particle system is animated through out its life. This includes, not only its position and velocity, but also its display attributes: shape, color, transparency. To animate the particle's position in space, the velocity is updated, average velocity is computed and used to update the particle's position, and the particle's velocity is updated. Gravity, other global force fields (e.g. wind), local force fields (vortices), and collisions with objects in the environment are typically used to update the particle's velocity. The particle's color and transparency can be a function of global time, its own life-span remaining, its height, etc. The particle's shape can be a function of its speed (magnitude of veloctiy).
Particle rendering: In order to simplify rendering, each particle can be modeled as a point light source so that each particle adds color to the pixel or pixels it covers, but is not involved in visible surface algorithms (except to be hidden) or shadowing.
In some applications, shadowing effects have been determined to be an important visual cue. The density of particles between a position in space and a light source can be used to estimate the amount of shadowing. See Blinn's paper Ebert's paper, and Reeves' paper for some of these considerations.
For more information, see Reeves' paper on particle systems or Sims' paper on particles animation and rendering
Flocking can be characterized by typcially having a medium number of participants each of who are controlled by relatively simple set of rules which operate locally. The participants exhibit some limited intelligence and are governed by some relatively simple physics. The physics-based modeling typcially includes collision avoidance, gravity, and drag.
For purposes of this discussion, we'll stay with the birds-making-a-flight analogy although it should be realized that, in general, we're talking about any collection of participants which exhibits this kind of group behavior,i.e., emergent behavior. In order to use the flock anology but acknowledge that it refers to more a more general concept, we'll follow Reynold's example and use boid to refer to a member of the generalized flock. Much of this discussion is taken from his paper.
There are two main forces at work in keeping a bunch of boids behaving like a flock: collision avoidance and flock centering. These are competing tendencies and must be balanced with collision avoidance taking precedence when push comes to shove (is that a pun?).
Collision avoidance is relative to both other members of the flock as well as other obstacles in the environment. Avoiding collision with other members in the flock means that some spacing must be maintained between the members even though all members are usually in motion and that motion usually has some element of randomness associated with it in order to break up unnatural-looking regularity.
Flock centering has to do with each member trying to be just that - a member - a member of a flock. As Reynold's points out in his paper, a global flock centering force doesn't work well in practice because it prohibits flock splitting, such as that often observed when a flock passes around a pillar. Flock centering should be a localized tendency so that birds in the middle of a flock will stay that way and birds on the border of a flock will have a tendency to veer toward their neighbors on one side. Localizing the flocking behavior also enables the reduction of the order-of-complexity of the controlling procedure.
One of the activities carried out in programming a flocking model when using localized rules is that of simulating an area of perception. Examples of this are that a boid should:
In addition ot collision avoidance and flock centering, a third force which is useful in controlling the boid's behavior is velocity matching. velocity matching helps both to avoid collision as well as keep a flock-centered boid flock-centered.
Negotiating the Motion: In producing the motion, we have three low-level controllers (in priority order): collision avoidance, velocity matching, and flock centering. Each of these produces a directive that indicates desired speed and direction (a velocity vector). The next task is to negotiate a resultant velocity vector given the various requests. Reynold's refers to the programmatic entity that does this as the navigation module. As Reynolds points out, averaging the requests is usually a bad idea in that requests can cancel each other out and result in non-intuitive motion. He suggests a prioritized acceleration allocation strategy in which there is a finite amount of prioritization available, say one unit. A prioritization value is generated by the low-level controllers in addition to the velocity vector and the prioritization is allocated according to priority order of controllers. If the amount of prioritization runs out, then one or more of the controllers receives less that what they requested. If less than the amount of total possible prioritization is not allocated, then the values are normalized (to sum to the value of one, in our example). A weighted average is then used to compute the final velocity vector. Governors may be used to dampen the resulting motion such as clamping the maximum velocity and/or clamping the maximum acceleration.
N-squared complexity: One of the problems with flocking systems, in which knowledge about neighbors is required and the number of members of a flock can get somewhat large, is that it becomes n-squared complexity. Even when interactions are limited to some k nearest neighbors, it is still required to find those k nearest neighbors out of the n total population. A common way to get a handle on this type of processing is to use a 3D bucket sort approach so that a boid only needs to consider other boids in its own bucket and maybe the immediately adjacent neighbors. This doesn't completely get rid of the n-squared problem, but in practice it is effective.
Collision avoidance: There are several strategies which can be used in avoiding collisions. The ones mentioned here are from Reynold's paper or from his ' course notes. These, in one way or another, model the boid's field of view and visual processing. Trade-offs must be made between complexity of computation and effectiveness:
Modeling flight: Specific to modeling flight, but also of more general use, is a description of the forces involved in aerodynamics. A local coordinate system of roll, pitch and yaw is commonly used to discuss the orientation of the flying object. The main forces involved are: lift, gravity, thrust, and drag. For straight and level flight, lift cancels gravity and thrust exceeds drag. Increasing the pitch increases lift and drag. In a turn, lift is not directed exactly upward. Because of the tilt (roll) of the flying object, it has a verticle component and a horizontal component. In order to maintain altitude, the verticle component of lift cancels with gravity. Therefore, in a turn, speed must be increased in order to increase lift in order to keep the verticle lift component equal to gravity. The turn is in the direction of the horizontal component. In order for the object to be directed into the turn, there must be some yaw.
For additional information, see Reynold's web page on boids.
Besides the simulation of physical processes, mental processes can also be simulated. The most common method of simulation of simple acts of cognition is by using a rule-based system. Basically, a database is made up of a bunch of cause-and-effect rules which the objects being animated (usually called actors) must follow. [Get Zelter's articles and Haumann's]
Forward and inverse kinematics are useful for positioning articulated figures. For realistic physically based motion, the forces acting on an articulated figure also have to be taken into consideration.
If torques at rotational joints are used to control the motion, then we call it forward dynamics. If the desired path of the end effector is known and the forces required to move along that path are solved for, then we call it inverse dynamics.
Consider a simple 2D case of a base joint, a link, a joint, and another link. A pose is defined by specifying two angles. Animation could be done by specifying a function theta = fi(t), i = 1,2. For each time, t, two thetas are produced. This is forward kinematics. It is up to the animator to supply the functions fi(t).
Assume origin of global frame, frame0, at base joint; frame 1's x-axis aligned with link 1; frame 2's x-axis aligned with link 2. Assume length of link 1 is L1 and length of link 2 is L2. Point P, defined locally in frame 2 has coordinates 2P = (x2,y2). Point P defined in frame 1 coordinates:
1P = 2P*2T1 = ( x2*cos(theta2)-y2*sin(theta2) + L2, y2*sin(theta2)+x2*cos(theta2) )
and similarly,
0P = 1P*1T0 = ( x1*cos(theta1)-y1*sin(theta1) + L1, y1*sin(theta1)+x1*cos(theta1) )
so
0P = 2P * 2T1 *1T0 = 2P * 2T0
Now, the animator doesn't want to be required to specify the functions f1 and f2. S/he wants to specify the motion of the end effector, the tip of the final link. For example, instead of specifying the shoulder to be at thirty degrees and the elbow at twenty-seven degrees, the animator wants to specify the hand to be at (52,47), or, perhaps, the same place the handle of a cup is. The equations above can be used to solve for theta1 and theta2, given (x0,y0), the coordinates of the tip of the final link in global coordinates.
In such a simple system, it is possible to analytically solve directly for theta1 and theta2, given a desired position for the end effector. This is an example of inverse kinematics.
We can also analyze the linkage to produce equations that relate changes in joint angles to changes in linear and angular velocity at the tip. Specifically, for at give velocity of theta, theta2', around the z-axis at the second joint, z2:
2v =(theta2'* z2) x L2 2w = theta2'*z2
Notice that this is in the coordinate system of the second link. To transform these velocities into coordinates of the first list, we get:
Using modified Denevit & Hartenberg parameters, link i-1, then the axis of rotation zi, then link i occurs. Three parameters are to specify the relationship of zi to zi-1. The fourth parameter is the rotation about the axis. Given a point in coordinate frame i, call it iP, we can calculate the coordinates of that point in frame i-1, i-1P, by the following:
i-1Ti = Rot(zi,thetai) Transl(zi,di) Transl(xi-1,ai-1) Rot(xi-1,alphai-1) i-1P = iP i-1Ti where alpha - rotation about x a - translation along x d - translation along z (translational joint) theta - rotation about z (rotational joint)
The subscripts relating parameters to links are taken according to conventions established in the robotics literature. The main difference here is that a point is post-multiplied by the transformation matrix, T, instead of being pre-multiplied by it, as is the robotics convention.
The modified Denevit & Hartenberg parameters differ from the origin al Denevit & Hartenberg parameters in that the translation of the final transformation matrix, T, is not dependent on theta in the modified version.
Notice that's what important here is the final transformation matrix, T. Denevit & Hartenberg is just a standard set of parameters for specifying the relation of successive links. Any specification will do.
Jacobian derivation for simple linkage 2D, two-joint linkage change in end position v. change in thetas put in matrix form Jacobian for complex linkages look at angular as well as linear velocity Jacobian is 6xN matrix V = JŻ need to compute psuedo-inverse of Jacobian: J+ = JT(JJT)-1 use of Jacobian in inverse dynamics tau = JTÄ full dynamics equation in robotics tau = H(q)q'' + G(q) + C(q,q') + J+(q)Ä + V(q') q,q',q'' joint position, velocity and acceleration H - inertia matrix G - terms due to gravity C - Coreolis and Centrifugal effects J - statis case V - viscous forces optimize solution for center angle: a penalty method Ż = (J+J-I)z doesn't contribute anything to x' (velocities) Ż = J+x' + (J+J-I)z z = -weight*gradiate of H H(Ż) = summation of [(żi-żci)/deltażi]2
Facial animation specifically addresses the generation of facial expressions and mouth movements. There are two basic approaches: parameterized key positions and physically based models.
The face is typically modeled by a mesh of surface patches. In the parameterized approach, some subset of the mesh vertices are placed in a key position and a parameter value is associated with the position. As the parameter value is varied, the mesh vertices' positions are interpolated between key positions. Facial animation is performed by appropriately varying parameter values. Unfortunately, because of the flexibility of the face, this can result in a large number of parameters that are difficult for a user to deal with efficiently.
In a simple physically based approach, the mesh edges and vertices can be used to represent springs and mass nodes. By controlling spring constants and masses, the face can be animated by moving a small number of vertices. Unfortunately, the results this model produces fall short of being perfect.
More advanced implementations of facial animation model the bone structure and muscle groups as they slide over the bone structure. In this case, more accurate modeling of the physics and geometry involved produces very good results. However, there is a computational price to be paid for the higher quality of animation (no surprise there).
See the NSF Facial Animation Workshop or Scott King's overview
Walking is another speical purpose animation domain. More specialized that general articulated figure animation, this addresses the particular problems of balance and alternating points of support for a walking figure. [Get Girard's dissertaion]
For one approach, see Alerk Amin's Voxel Space Automata
Go back to Table of Contents
Go to Previous Chapter: Chapter 4. Techniques
to Aid Motion Specification
Go to Appendices