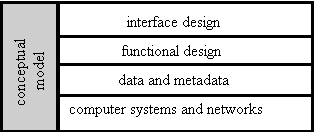
Figure 8.1. Aspects of usability
Chapter 8
User interfaces and usability
The person who uses a library is conventionally called a "patron" or "reader." In computing, the usual term is "user" or "end user". Whatever word is chosen, digital libraries are of little value unless they are easy to use effectively.
The relationship between people and computers is the subject of intensive research, drawing on field as diverse as cognitive science, graphic design, rhetoric, and mathematical modeling of computer systems. Some of the research aims to develop a theoretical understanding of how people interact with computers, so that models of how people process information can be used to design appropriate computer systems. Other research helps the user comprehend the principles behind a computer system, to stimulate productive use of the services and information that it provides. This chapter, however, is less ambitious. It concentrates on the methods that are widely used today, with some illustrations of experimental systems that show promise.
Change is one of the themes of digital libraries and change is one of the problems in designing user interfaces. Traditional libraries are not easy to use effectively, but they change slowly; users develop expertise over many years. Digital libraries evolve so quickly that every month brings new services, new collections, new interfaces, and new headaches. Users do not enjoy having to relearn basic skills, but change appears to be a necessary evil.
Partly because of this rapid change, users have an enormous variety in their levels of expertise. Much of the development of digital libraries has come out of universities, where there are many experts. Colleagues and librarians are at hand to help users, while system administrators configure computers, install software, and track changes in the market place. As the Internet has spread more widely, digital libraries are being used by people who do not have access to such expertise and do not want to spend their own time learning techniques that may be of transitory value. This creates a tension. Advanced features of a library are valuable for the specialist. They enable the skilled user to work faster and be more effective, but digital libraries must also be usable by people with minimal training.
Aspects of usability and user interface design
In discussing the usability of a computer system, it is easy to focus on the design of the interface between the user and the computer, but usability is a property of the total system. All the components must work together smoothly to create an effective and convenient digital library, for both the patrons, and for the librarians and systems administrators.
Figure 8.1. Aspects of usability
Figure 8.1 shows a way to think about usability and the design of user interfaces. In any computer system, the user interface is built on a conceptual model that describes the manner in which the system is used. Here are some typical conceptual models that are used to design digital libraries. In practice, most digital libraries combine concepts from several such models.
The classical library model is to search a catalog or index, select objects from the results, and retrieve them from a repository.
The basic web model is for the user to follow hyperlinks between files.
The Z39.50 protocol supports a conceptual model of searching a collection, and storing sets of results for subsequent manipulation and retrieval.
The right-hand side of Figure 8.1 shows the layers that are needed to implement any conceptual model. At the top is the interface design, the appearance on the screen and the actual manipulation by the user. This covers such considerations as fonts, colors, logos, key board controls, menus, and buttons. The next level down, the functional design, represents the functions that are offered to the user. Typical functions include selection of parts of a digital object, searching a list or sorting the results, help information, and the manipulation of objects that have been rendered on a screen. These functions are made possible by the two bottom sections of the figure: the data and metadata that are provided by the digital library, and the underlying computer systems and networks. Panel 8.1 illustrates these five aspects by showing how they apply to an important application.
|
Panel 8.1 Page turning is an example that illustrates the distinction between the various aspects of user interface design shown in Figure 8.1. Conversion projects, such as JSTOR or American Memory, have collections of digital objects, each of which is a sets of page images scanned from a book or other printed materials. Conceptual model The conceptual model is that the user interacts with an object in much the same manner as with a book. Often the pages will be read in sequence, but the reader may also go back a page or jump to a different page. Some pages may be identified as special, such as the table of contents or an index. Since many personal computers have screens that are smaller than printed pages and have lower resolution, the conceptual model includes zooming and panning across a single page. Interface design The interface design defines the actual appearance on the screen, such as the choice of frames, icons, colors, and visual clues to help the user. It also includes decisions about how the individual functions are offered to the user. The interface design determines the appearance of icons, the wording on the buttons, and their position on the screen. The design also specifies whether panning and zooming are continuous or in discrete steps. When we built a page turner at Carnegie Mellon University, the interface design maximized the area of the screen that was available for displaying page images. Most manipulations were controlled from the keyboard; the arrow keys were used for panning around an individual page, with the tab key used for going to the next page. An alternative design would have these functions controlled by buttons on the screen, but with less space on the screen for the page images. Functional design To support this conceptual model, the design provides functions that are equivalent to turning the pages of a book. These functions include: go to the first, next, previous, or last page. There will be functions that relate to the content of a specific page, such as: go to the page that has a specific page number printed on it, or go to a page that is designated as the contents page. To support panning and zooming within a page, other functions of the user interface move the area displayed up or and down one screen, and zoom in or out. Data and metadata The functions offered to the user depend upon the digital objects in the collections and especially on the structural metadata. The page images will typically be stored as compressed files which can be retrieved in any sequence. To turn pages in sequence, structural metadata must identify the first page image and list the sequence of the other images. To go to the page with a specific page number printed on it requires structural metadata that relates the page numbers to the sequence of page images, since it is rare that the first page of a set is the page with number one. Zooming and panning need metadata that states the dimensions of each page. Computer systems and networks The user interface is only as good as the performance of the underlying system. The time to transmit a page image across a network can cause annoying delays to the user. One possible implementation is to anticipate demands by sending pages from the repository to the user's computer before the user requests them, so that at least the next pages in sequence is ready in memory. This is known as "pre-fetching". For the Carnegie Mellon page turner, priority was given to quick response, about one second to read and display a page image, even when transmitted over the busy campus network. This led to a pipelined implementation in which the first part of a page was being rendered on the user's computer even before the final section was read into the repository computer from disk storage. |
The desk-top metaphor
Almost all personal computers today have a user interface of the style made popular on Apple's Macintosh computers, and derived from earlier research at Xerox's Palo Alto Research Center. It uses a metaphor of files and folders on a desktop. Its characteristics include overlapping windows on the screen, menus, and a pointing device such as a mouse. Despite numerous attempts at improvements, this style of interface dominates the modern computer market. A user of an early Macintosh computer who was transported through fifteen years and presented with a computer running Microsoft's latest system would find a familiar user interface. Some new conventions have been introduced, the computer hardware is greatly improved, but the basic metaphor is the same.
In the terminology of Figure 8.1, the conceptual model is the desktop metaphor; files are thought of as documents that can be moved to the desktop, placed in folders, or stored on disks. Every windows-based user interface has this same conceptual model, but the interface designs vary. For example, Apple uses a mouse with one button, Microsoft uses two buttons, and Unix systems usually have three. The functions to support this model include open and closing files and folders, selecting them, moving them from one place to another, and so on. These functions differ little between manufacturers, but the systems differ in the metadata that they use to support the functions. The desktop metaphor requires that applications are associated with data files. Microsoft and Unix systems use file naming conventions; thus files with names that end ".pdf" are to be used with a PDF viewer. Apple stores such metadata in a separate data structure which is hidden from users. Finally, differences in the underlying computer systems permit some, but not all, user interfaces to carry out several tasks simultaneously.
Browsers
The introduction of browsers, notably Mosaic in 1993, provided a stimulus to the quality of user interfaces for networked applications. Although browsers were designed for the web, they are so flexible that they are used as the interface to almost ever type of application on the Internet, including digital libraries. Before the emergence of general purpose browsers, developers had to provide a separate user interface for every type of computer and each different computing environment. These interfaces had to be modified whenever the operating systems changed, a monumental task that few attempted and essentially nobody did well. By relying on web browsers for the actual interaction with the user, the designer of a digital library can now focus on how to organize the flow of information to the user, leaving complexities of hardware and operating systems to the browser.
Basic functions of web browsers
The basic function of a browser is to retrieve a remote file from a web server and render it on the user's computer.
To locate the file on the web server, the browser needs a URL. The URL can come from various sources. It can be typed in by the user, be a link within an HTML page, or it can be stored as a bookmark.
From the URL, the browser extracts the protocol. If it is HTTP, the browser then extracts from the URL the domain name of the computer on which the file is stored. The browser sends a single HTTP message, waits for the response, and closes the connection.
If all goes well, the response consists of a file and a MIME type. To render the file on the user's computer, the browser examines the MIME type and invokes the appropriate routines. These routines may be built into the browser or may be an external program invoked by the browser.
Every web browser offers support for the HTTP protocol and routines to render pages in the HTML format. Since both HTTP and HTML are simple, a web browser need not be a complex program.
Extending web browsers beyond the web
Browsers were developed for the web; every browser supports the core functions of the web, including the basic protocols, and standard formats for text and images. However, browsers can be extended to provide other services while retaining the browser interface. This extensibility is a large part of the success of browsers, the web, and indeed of the whole Internet. Mosaic had three types of extension which have been followed by all subsequent browsers:
Data types. With each data type, browsers associate routines to render files of that type. A few types have been built into all browsers, including plain text, HTML pages, and images in GIF format, but users can add additional types through mechanisms such as helper applications and plug-ins. A helper application is a separate program that is invoked by selected data types. The source file is passed to the helper as data. For example, browsers do not have built-in support for files in the PostScript format, but many users have a PostScript viewer on their computer which is used as a helper application. When a browser receives a file of type PostScript, it starts this viewing program and passes it the file to be displayed. A plug-in is similar to a helper application, except that it is not a separate program. It is used to render source files of non-standard formats, within an HTML file, as part of a single display.
Protocols. HTTP is the central protocol of the web, but browsers also support other protocols. Some, such as Gopher and WAIS, were important historically because they allowed browsers to access older information services. Others, such as Netnews, electronic mail and FTP, remain important. A weakness of most browsers is that the list of protocols supported is fixed and does not allow for expansion. Thus there is no natural way to add Z39.50 or other protocols to browsers.
Executing programs. An HTTP message sent from a browser can do more than retrieve a static file of information from a server. It can run a program on a server and return the results to the browser. The earliest method to achieve this was the common gateway interface (CGI), which provides a simple way for a browser to execute a program on a remote computer. The CGI programs are often called CGI scripts. CGI is the mechanism that most web search programs use to send queries from a browser to the search system. Publishers store their collections in databases and use CGI scripts to provide user access. Consider the following URL:
http://www.dlib.org/cgi-bin/seek?author='Arms'
An informal interpretation of this URL is, "On the computer with domain name "www.dlib.org", execute the program in the file "cgi-bin/seek", pass it the parameter string "author='Arms'", and return the output." The program might search a database for records having the word "Arms" in the author field.
The earliest uses of CGI were to connect browsers to older databases and other information. By a strange twist, now that the web has become a mature system, the roles have been reversed. People who develop advanced digital libraries often use CGI as a method to link the old system (the web) to their newer systems.
Mobile code
Browsers rapidly became big business, with new features added continually. Some of these features are clearly good for the user, while others are marketing features. The improvements include performance enhancements, elaboration to HTML, built-in support for other formats (an early addition was JPEG images), and better ways to add new formats. Two changes are more than incremental improvements. The first is the steady addition of security features. The other is mobile code which permits servers to send computer programs to the client, to be executed by the browser on the user's computer.
Mobile code gives the designer of a web site the ability to create web pages that incorporate computer programs. Panel 8.2 describes one approach, using small programs, called applets, written in the Java programming language. An applet is a small program that can be copied from a web site to a client program and executed on the client. Because Java is a full programming language, it can be used for complex operations. An example might be an authentication form sent from the web site to the browser; the user can type in an ID and password, which a Java applet encrypts and sends securely back to the server.
|
Panel 8.2 Java is a general purpose programming language that was explicitly designed for creating distributed systems, especially user interfaces, in a networked environment. If user interface software is required to run on several types of computer, the conventional approach has been to write a different version for each type of computer. Thus browsers, such as Netscape Navigator, and electronic mail programs, such as Eudora, have versions for different computers. Even if the versions are written in a standard language, such as C, the differences between the Microsoft Windows, or Unix, or Macintosh force the creator of the program to write several versions and modify them continually as the operating systems change. A user who wants to run a new user interface must first find a version of the user interface for the specific type of computer. This must be loaded onto the user's computer and installed. At best, this is an awkward and time-consuming task. At worst, the new program will disrupt the operation of some existing program or will introduce viruses onto the user's personal computer. Computer programs are written in a high-level language, known as the source code, that is easily understood by the programmer. The usual process is then to compile the program into the machine language of the specific computer. A Java compiler is different. Rather than create machine code for a specific computer system, it transforms the Java source into an intermediate code, known as Java bytecode, that is targeted for a software environment called a Java Virtual Machine. To run the bytecode on a specific computer a second step takes place, to interpret each statement in the bytecode to machine code instructions for that computer as it is executed. Modern browsers support the Java Virtual Machine and incorporate Java interpreters. A Java applet is a short computer program. It is compiled into a file of Java bytecode and can be delivered across the network to a browser, usually by executing an HTTP command. The browser recognizes the file as an applet and invokes the Java interpreter to execute it. Since Java is a fully featured programming language, almost any computing procedure can be incorporated within a web application. The Java system also provides programmers with a set of tools that can be incorporated into programs. They include: basic programming constructs, such as strings, numbers, input and output, and data structures; the conventions used to build applets; networking services, such as URLs, TCP sockets, and IP addresses; help for writing programs that can be tailored for scripts and languages other than English; security, including electronic signatures, public/private key management, access control, and certificates; software components, known as JavaBeans, which can plug into other software architectures; and connections to databases. These tools help programmers. In addition, since the basic functions are a permanent part of the web browser, they do not have to be delivered across the Internet with every applet and can be written in the machine code of the individual computer, thus executing faster than the interpreted bytecode. When a new computing idea first reaches the market, separating the marketing hype from the substance is often hard. Rarely, however, has any new product been surrounded by as much huff and puff as the Java programming language. Java has much to offer to the digital library community, but it is not perfect. Some of the defects are conventional technical issues. It is a large and complex programming language, which is difficult to learn. Interpreted languages always execute slowly and Java is no exception. Design decisions that prevent Java applets from bringing viruses across the network and infecting the user's computer also constrain legitimate programs. However, Java's biggest problems is non-technical. Java was developed by Sun Microsystems which set out to develop a standard language that would be the same in all versions. Unfortunately, other companies, notably Microsoft, have created incompatible variants. |
Java is not the only way to provide mobile code. An alternative is for an HTML page to include a script of instructions, usually written in the language known as JavaScript. JavaScript is simpler to write than Java and executes quickly. A typical use of JavaScript is to check data that a user provides as input, when it is typed, without the delays of transmitting everything back to the server for validation. Do not be confused by the names Java and JavaScript. The two are completely different languages. The similarity of names is purely a marketing device. Java has received most of the publicity, but both have advantages and both are widely used.
Recent advances in the design of user interfaces
The design of user interfaces for digital libraries is part art and part science. Figure 8.1 provides a systematic framework for developing a design, but ultimately the success of an interface depends upon the designers' instincts and their understanding of users. Each part of the figure is the subject of research and new concepts are steadily being introduced to the repertoire. This section looks at some of the new ideas and topics of research. In addition, Chapter 12 describes recent research into structural metadata. This is a topic of great importance to user interfaces, since the manner in which digital objects are modeled and the structural metadata associated with them provide the raw material on which user interfaces act.
Conceptual models
Several research groups have been looking for conceptual models that help users navigate through the vast collections now available online. There are few landmarks on the Internet, few maps and signposts. Using hyperlinks, which are the heart of the web, the user is led to unexpected places and can easily get lost. Users of digital libraries often work by themselves, with little formal training, and nobody to turn to for help. This argues for interfaces to be based on conceptual models that guide users along well-established paths, although, with a little ingenuity, some people are remarkably adept at finding information on the Internet. Observations suggest that experienced people meet a high percentage of their library needs with networked information, but less experienced users often get lost and have difficult evaluating the information that they find. Panel 8.3 describes two research projects that have explored novel conceptual models for digital libraries.
|
Panel 8.3 The standard user interface on personal computers is derived from an abstraction of a desktop. Several interesting experiments in digital libraries have searched for metaphors other than the desktop. Since these were research projects, the interfaces will probably never be used in a production system, but they are important for developing concepts that can be used in other interfaces and illustrating a design process that is based on systematic analysis of user needs and expectations. DLITE DLITE is an experimental user interface developed by Steve Cousins, who was then at Stanford University, as part of the Digital Libraries Initiative. DLITE was created as a user interface of the Stanford InfoBus. It uses concepts from object oriented programming, with each component being implemented as a CORBA object. The InfoBus and CORBA are described in Chapter 13. Conceptual model The conceptual model is based on an analysis of the tasks that a user of digital libraries carries out. The following key requirements were identified:
The model describes digital libraries in terms of components; the four major types are documents, queries, collections, and services. These components are represented by icons that can be manipulated directly by the user in viewing windows on the screen. For example, dragging a query onto a search service, causes the search to be carried out, thus creating a collection of results. DLITE allows end users to create task-specific interfaces by assembling interface elements on the screen. Functional design The functional design of DLITE was motivated by two considerations: the ability to add new services with minimal effort, and rapid response for the user. For these reasons, the functional design is divided into two sections, known as the user interface clients and the user interface server. The clients carries out the manipulations of the four types of components. Several can run at the same time. The server provides the interface to the external services and can operate even when the clients are shut down. Extensibility is provided by the server. When a new service is added, a new interface will need to be programmed in the server, but no modification is needed in existing clients. Support for a variety of computers and operating systems is provided by having separate client programs for each. Pad++ Pad++ is a user interface concept that was conceived by Ken Perlin at New York University and has been developed by researchers from several universities and research centers. Its fundamental concept is that a large collection of information can be viewed at many different scales. The system takes the metaphor of the desktop far beyond the confines of a computer display, as though a collection of documents were spread out on an enormous wall. User interactions are based on the familiar ideas of pan and zoom. A user can zoom out and see the whole collection but with little detail, zoom in part way to see sections of the collection, or zoom in to see every detail. This spatial approach makes extensive use of research in human perception. Since people have good spatial memory, the system emphasizes shape and position as clues to help people explore information and to recall later what they found. When Pad++ zooms out, details do not grow ever smaller and smaller. This would create a fussy image for the user and the program would be forced to render huge numbers of infinitesimal details. Features have thresholds. Below a certain scale, they are merged into other features or are not displayed at all. Using a process known as "semantic zooming", objects change their appearance when they change size, so as to be most meaningful. This approach is familiar from map making. A map of a large area does not show individual buildings, but has a notation to represent urban areas. Pad++ is not intended as a universal interface for all applications. For some applications, such as exploring large hierarchical collections in digital libraries, Pad++ may be the complete user interface. At other times it may be a visualization component, alongside other user interface concepts, within a conventional windowing system. Computer systems Pad++ provides an interesting example of user interface research into the relationship between system performance and usability. Panning and zooming are computationally complex operations; slow or erratic performance could easily infuriate the user. Several versions of the Pad++ concept have been developed, both freestanding and as part of web browsers. Each contains internal performance monitoring. The rendering operations are timed so that the frame refresh rate remains constant during pans and zooms. When the interface starts to be slow, medium-sized features are rendered approximately; the details are added when the system is idle. |
Interface design
Interface design is partly an art, but a number of general principles have emerged from recent research. Consistency is important to users, in appearance, controls, and function. Users need feedback; they need to understand what the computer system is doing and why they see certain results. They should be able to interrupt or reverse actions. Error handling should be simple and easy to comprehend. Skilled users should be offered shortcuts, while beginners have simple, well-defined options. Above all the user should feel in control.
Control creates a continuing tension between the designers of digital libraries and the users, particularly control over graphic design and the appearance of materials. Many designers want the user to see materials exactly as they were designed. They want to control graphical quality, typography, window size, location of information within a window, and everything that is important in good design. Unfortunately for the designer, browsers are generic tools. The designer does not know which browser the user has, what type of computer, how fast the network, or whether the display is large or small. Users may wish to reconfigure their computer. They may prefer a large font, or a small window, they may turn off the display of images to reduce network delays. Therefore, good designs must be effective in a range of computing environments. The best designers have an knack of building interfaces that are convenient to use and attractive on a variety of computers, but some designers find difficulty in making the transition from traditional media, where they control everything, to digital libraries and the web. A common mistake is over-elaboration, so that an interface is almost unusable without a fast network and a high-performance computer.
One unnecessary problem in designing interfaces is that Netscape and Microsoft, the two leading vendors of browsers, deliver products that have deliberately chosen to be different from each other. A user interface that works beautifully on one may be a disaster on the other. The manufacturers' competitive instincts have been given priority over the convenience of the user. If a designer wishes to use some specialized features, the user must be warned that the application can not be used on all browsers.
Functional design
Digital libraries are distributed systems, with many computers working together as a team. Research into functional design provides designers with choices about what functions belong on which of the various computers and the relationships between them. Between a repository, where collections are stored, and the end user, who is typically using a web browser, lies an assortment of computer programs which are sometimes called middleware. The middleware programs act as intermediaries between the user and the repository. They interpret instructions from users and deliver them to repositories. They receive information from repositories, organize it, and deliver it to the user's computer. Often the middleware provides supporting services such as authentication or error checking, but its most important task is to match the services that a user requires with those provided by a repository.
Figures 8.2 and 8.3 show two common configurations. In both situations a user at a personal computer is using a standard web browser as the front end interface to digital library services, illustrated by a repository and a search system.
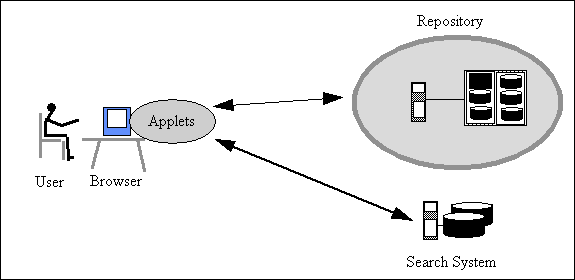
Figure 8.2. User interface with interface scripts
Figure 8.2 shows middleware implemented as independent computer programs, usually CGI scripts, that run on server computers somewhere on the network. The browser sends messages to the interface in a standard protocol, probably HTTP. The scripts can run on the remote service or they can communicate with the service using any convenient protocol. In the figure, the link between the interface scripts and the search system might use the Z39.50 protocol. The technical variations are important for the flexibility and performance of the system, but functionally they fill the same need. This configuration has the disadvantage that every action taken by the user must be transmitted across the network to be processed and the user then waits for a response.
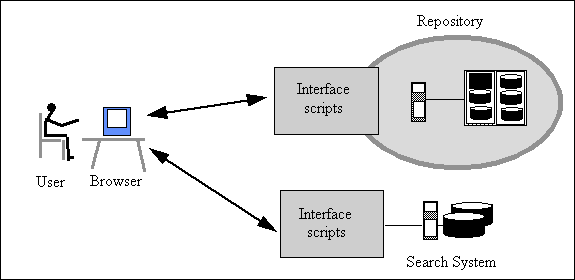
Figure 8.3. User interface with mobile code (applets)
Figure 8.3 shows a more modern configuration, where mobile code is executed on the user's computer by the browser. The code might be Java applets. Until used, the code is stored on the remote server; it is loaded into the user's computer automatically, when required. This configuration has many advantages. Since the user interface code runs on the user's computer it can be very responsive. The protocol between the user interface and the services can be any standard protocol or can be tailored specially for the application.
A presentation profile is an interesting concept which has recently emerged. Managers of a digital library associate guidelines with stored information. The guidelines suggest how the objects might be presented to the user. For example, the profile might recommend two ways to render an object, offering a choice of a small file size or the full detail. The user interface is encouraged to follow the profile in rendering the data, but has the option of following different approaches. An potential use of presentation profiles is to permit specialized interfaces to support people who have physical difficulties in using the standard presentation.
Computer systems and networks
The performance of computer systems and networks has considerable impact on the usability. The creator of a digital library can make few assumptions about the equipment that a user possesses, beyond the basic knowledge that every user has a personal computer attached to the Internet. However, this simple statement covers a multitude of situations. Some personal computers are more powerful than others; the quality of displays vary greatly. Some people have their own private computer, which they can configure as they wish; others may share a computer, or use more than one computer. Any digital library must assume that users will have a variety of computers, with various operating systems and environments. The environments include the various versions of Microsoft's Windows, the Macintosh, and a plethora of types of Unix. Differences between operating systems can be minimized by using a web browser for the user interface, but performance differences are not so simple.
The usability of a computer system depends upon the speed with which it responds to instructions. The designer of a digital library has little or no knowledge of the quality of network connections between the user and the library. Connections vary from spectacularly fast to frustratingly slow and even the best connections experience occasional long pauses. A user interface that is a delight to use over a 10 million bits/second local network may be unusable over an erratic, dial-up link that rarely reaches its advertised speed of 14 thousand bits/sec. Thus digital libraries have to balance effective use of advanced services, requiring fast equipment and up-to-date software, with decent service to the users who are less well provided.
Improving the responsiveness of browsers
Web browsers incorporate several tricks to improve the responsiveness seen by the user. One is internal caching. Information that has been used once is likely to be used again, for example when the user clicks the "back" button on a web browser; some graphics may be repeatedly constantly, such as logos and buttons. Web browsers retain recently used files by storing them temporarily on the disk of the user's personal computer. These files may be HTML pages, images, or files of mobile code, perhaps in JavaScript. When the user requests a file, the browser first checks to see if it can read the file from the local cache, rather than reach out across the Internet to retrieve it from a distant server.
Another family of methods that improve the responsiveness of browsers is to carry out many operations in parallel. Browsers display the first part of a long file before the whole file has arrived; images are displayed in outline with the details filled in later as more data arrives. Several separate streams of data can be requested in parallel. In aggregate, these techniques do much to mitigate the slow and erratic performance that often plagues the Internet.
Mirroring and caching
A key technique to enhance the performance of systems on the Internet is to replicate data. If a digital library collection is to be used by people around the world, duplicate copies of the collection are made at several sites, perhaps two in Europe, two in the United States, one in Australia, and one in Japan. This is called mirroring. Each user selects the mirror site that provides the best performance locally. Mirroring also provides back-up. If one site breaks down, or a section of the network is giving trouble, a user can turn to another site.
While mirroring is a technique to make copies of entire collections, caching is used to replicate specific information. A cache is any store that retains recently used information, to avoid delays the next time that it is used. Caches are found within the computer hardware to help computer processors run quickly; they are found in the controllers that read data from computer disks; they are used to improve the speed and reliability of the domain name system which converts domain names to Internet addresses. Digital libraries have caches in many places. Organizations may run local caches of documents that have been read recently; a digital library that store large collections on slow but cheap mass storage devices will have a cache of information stored on faster storage devices.
All methods of replicating data suffer from the danger that differences between the versions may occur. When information has been changed, some users may be receiving material that is out of date. Elaborate procedures are needed to discard replicated information after a stated time, or to check the source to see if changes have taken place. Caches are also vulnerable to security break-ins. A computer system is only as secure as its weakest link. A cache can easily be the weakest link.
Reliability and user interfaces
Few computer systems are completely reliable and digital libraries depend upon many subsystems scattered across the Internet. When the number of independent components is considered, it is remarkable that anything ever works. Well-designed computer systems provide the user with feedback about the progress in carrying out tasks. A simple form of feedback is to have an animation that keeps moving while the user interface is waiting for a response. This at least tells the user that something is happening. More advanced feedback is provided by an indication of the fraction of the task that has been completed with an estimate of the time to completion. In all cases, the user needs a control that allows a time consuming operation to be canceled.
The term "graceful degradation" describes methods that identify when a task is taking a long time and attempt to provide partial satisfaction to the user. A simple technique is to allow users of web browsers to turn off the images and see just the text in web pages. Several methods of delivering images allow a crude image to be displayed as soon as part of the data has been delivered, with full resolution added later.
User interfaces for multimedia information
The types of material in digital libraries are steadily becoming more varied. User interface designs for collections of textual material may be inadequate when faced with collections of music, of maps, of computer software, of images, of statistical data, and even of video games. Each is different and requires different treatment, but some general principles apply.
Summarization. When a user has many items to choose from, it is convenient to represent each by some small summary information that conveys the essence of the item. With a book, the summary is usually the title and author; for a picture, a thumbnail-sized image is usually sufficient. More esoteric information can be difficult to summarize. How does a digital library summarize a computer program, or a piece of music?
Sorting and categorization. Libraries organize information by classification or by ordering, but many types of information lack easily understood ways of organization. How does the library sort musical tunes? Fields guides to birds are easy to use because they divide birds into categories, such as ducks, hawks, and finches. Guides to wild flowers are more awkward, because flowers lack the equivalent divisions.
Presentations. Many types of information require specialized equipment for the best presentation to the user. High-quality digitized video requires specialized displays, powerful computers, high-speed network connections, and appropriate software. A digital library should make full use of these capabilities, if they exist, but also needs to have an alternative way to present information to users with lesser equipment. This inevitably requires the digital library to offer a selection of presentations.
To design digital libraries for different types of information, it is abundantly clear that there is no single solution. User interfaces have to be tailored for the different classes of material and probably also for different categories of user. Panel 8.4 describes one good example of a user interface, the Informedia digital library of digitized segments of video.
|
Panel 8.4 Informedia is a research program at Carnegie Mellon University into digital libraries of video. The leader is Howard Wactlar. The objects in the library are broadcast news and documentary programs, automatically broken into short segments of video, such as the individual items in a news broadcast. The emphasis is on automatic methods for extracting information from the video, in order to populate the library with minimal human intervention. As such it is definitely a research project, but it is a research project with a practical focus. It has a large collection of more than one thousand hours of digitized video, obtained from sources such as Cable Network News, the British Open University, and WQED television. Chapter 12 describes some of the techniques that have been developed to index and search video segments automatically. Informedia has also proved to be a fertile source of user interface concepts. Video skimming Research projects often achieve results that go beyond what was expected at the start. Informedia's video skimming is an example. One of the challenges with video or audio material is to provide users with an quick overview of an item. The reader of a book can look at the contents page or flick through the pages to see the chapter headings, but there is no way to flick through a video. Video skimming uses automatic methods to extract important words and images from the video. In combination, the selected words and images provide a video abstract that conveys the essence of the full video segment. The user interface The Informedia user interface uses the conceptual model of searching an index of the collection to provide a set of hits, followed by browsing through the items found. Queries can be entered by typing, or by speech which is converted to words by a speech recognition program. After searching, the user interface presents ranked results. Each video clip is represented by an image; when the mouse is moved over the image, a text summary is provided. The image is selected automatically as representative of the video segment as it relates to the current query. The summary is created through natural language processing, forming a written representation of the video. The user can then click on an image to view the segment. The interface design is a video viewer with controls, such as "play" or "stop", that are similar to the control on a normal video player. Most users are familiar with these controls. The Informedia interface is sufficiently intuitive that it can be used by people who have not been trained on the system. The interface maximizes feedback to the user at each step. Much of the testing has been with high school students in Pittsburgh. |
User interfaces and the effectiveness of digital libraries
During the past few years, the quality of user interface design has improved dramatically. It is now assumed that new users can begin productive work without any training. Most importantly, there are now numerous examples of fine interfaces on the Internet that others can use as models and inspiration. Standards of graphical design gets better every year. For D-Lib Magazine, we redesigned our materials three times in as many years. Each was considered elegant in its day, but needed a face lift a year later.
Good support for users is more than a cosmetic flourish. Elegant design, appropriate functionality, and responsive systems make a measurable difference to the effectiveness of digital libraries. When a system is hard to use, the users may fail to find important results, may mis-interpret what they do find, or may give up in disgust believing that the system is unable to help them. A digital library is only as good as the interface it provides to its users.
Last revision of content: January 1999
Formatted for the Web: December 2002
(c) Copyright The MIT Press 2000