Figure 9.1. The relationship between structure and appearance
Chapter 9
Text
The importance of text
Textual materials have a special place in all libraries, including digital libraries. While sometimes a picture may indeed be worth a thousand words, more often the best way to convey complex ideas is through words. The richness of concepts, the detail, and the precision of ideas that can be expressed in text are remarkable. In digital libraries, textual documents come from many sources. They can be created for online use. They can be converted from print or other media. They can be the digitized sound track from films or television programs. In addition, textual records have a special function as metadata to describe other material, in catalogs, abstracts, indexes, and other finding aids. This chapter looks at how textual documents are represented for storage in computers, and how they are rendered for printing and display to users. Metadata records and methods for searching textual documents are covered in later chapters.
Mark-up, page description, and style sheets
Methods for storing textual materials must represent two different aspects of a document: its structure and its appearance. The structure describes the division of a text into elements such as characters, words, paragraphs and headings. It identifies parts of the documents that are emphasized, material placed in tables or footnotes, and everything that relates one part to another. The structure of text stored in computers is often represented by a mark-up specification. In recent years, SGML (Standard Generalized Markup Language) has become widely accepted as a generalized system for structural mark-up.
The appearance is how the document looks when displayed on a screen or printed on paper. The appearance is closely related to the choice of format: the size of font, margins and line spacing, how headings are represented, the location of figures, and the display of mathematics or other specialized notation. In a printed book, decisions about the appearance extend to the choice of paper and the type of binding. Page-description languages are used to store and render documents in a way that precisely describe their appearance. This chapter looks at three, rather different, approaches to page description: TeX, PostScript, and PDF.
Figure 9.1. The relationship between structure and appearance
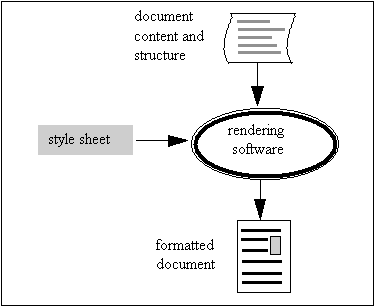
Structure and appearance are related by the design of the document. In conventional publishing, the designer creates a design specification, which describes how each structural element is to appear, with comprehensive rules for every situation that can arise. The specification is known as a style sheet. It enables a compositor to take a manuscript, which has been marked-up by a copy editor, and create a well-formatted document. Figure 9.1 is an outline of the procedure that several journal publishers use to produce electronic journals. Articles received from authors are marked up with SGML tags, which describe the structure and content of the article. A style sheet specifies how each structural element should appear. The SGML mark-up and the style sheet are input to rendering software which creates the formatted document.
In the early days of digital libraries, a common question was whether digital libraries would replace printed books. The initial discussion concentrated on questions of readability. Under what circumstances would people read from a screen rather than printed paper? With experience, people have realized that computers and books are not directly equivalent. Each has strengths that the other can not approach. Computing has the advantage that powerful searching is possible, which no manual system can provide, while the human factors of a printed book are superb. It is portable, can be annotated, can be read anywhere, can be spread out on a desk top or carried in the hand. No special equipment is needed to read it.
Since digital texts and printed materials serve different roles, publishers create printed and online versions of the same materials. Figure 9.2 shows how a mark-up language can be used to manage texts that will be both printed and displayed on computer screens. By using separate style sheets, a single document, represented by structural mark-up, can be rendered in different ways for different purpose. Thus, journal articles can be displayed on screen or printed. The layout and graphic design might be different, but they are both derived from the same source and present the same content.
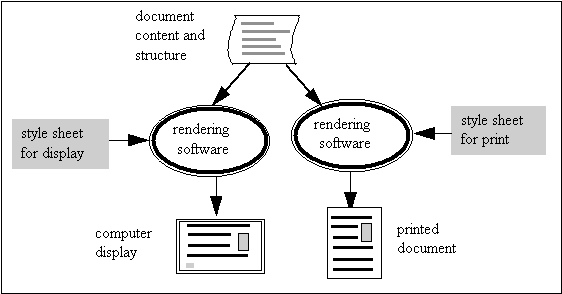
Figure 9.2. Alternative renderings of a single document
Strict control over the appearance of documents via SGML mark-up and style sheets proves to be very difficult. The ways that textual materials are organized, displayed, and interpreted have many subtleties. Mark-up languages can represent almost all structures, but the variety of structural elements that can be part of a document is huge, and the details of appearance that authors and designers could choose are equally varied. For example, many articles in journals published by the ACM contain mathematical notation. Authors often supply their articles in TeX format, which provides precise control over the layout of mathematics. During the production process it is converted to SGML mark-up. When rendered using a style sheet, the output may appear slightly different from the author's original, which can cause problems.
|
Panel 9.1 The new Oxford English Dictionary is a fine example of the use of a mark-up language to describe both structure and content, so that the same material can be used as the basis for a variety of products. The first edition of the dictionary was created by James Murray and his colleagues over four decades. Nineteenth century photographs of Murray at work in his grandly named "Scriptorium" in Oxford show a primitive shack filled with slips of paper. The dictionary was a landmark in lexicography, but it existed only as static printed pages. Keeping it up to date by hand proved impossible. To create a new edition of the dictionary, the first stage was to type into a database the entire text of the original edition, identifying all the typographic distinctions. The typography of the original dictionary is loaded with semantic information. Capital letters, bold and italic fonts, parentheses, smaller type sizes, and other formatting conventions convey semantics that are recorded nowhere else. A highly sophisticated computer program was written that extracted this buried semantic information and marked the textual elements with SGML tags. The new dictionary is maintained as a computer database, in which the SGML mark-up is as important as the words of the text. Lexicographers update it continually. A wide variety of publications can be created with minimal effort, including printed books, CD-ROMs and other digital versions. This new Oxford English Dictionary required cooperation between the world's largest team of lexicographers, in Oxford, a team of computational linguists at Waterloo University in Ontario, and corporate support from IBM. |
Converting text
Today, most documents are created digitally, beginning life on a word processor, but libraries are full of valuable documents that exist only on paper. Consequently, there is demand to convert printed documents to computer formats. For important documents, conversion projects capture the appearance and also identify the structure of the original.
The basic conversion technique is scanning. A document is scanned by sampling its image on a grid of points. Each point is represented by a brightness code. In the simplest form, only black and white are distinguished. With a resolution of 300 dots per inch, horizontally and vertically, a good image can be made of most printed pages. If the resolution is increased to 600 dots per inch, or by coding for 8 levels of gray, the clarity becomes excellent, and halftone illustrations can be represented. High-quality artwork requires at least 24 bits per dot to represent color combinations. This creates very large files. The files are compressed for convenience in storage and processing, but even simple black-on-white text files need at least 50,000 bytes to store a single page.
A scanned page reproduces the appearance of the printed page, but represents text simply as an image. In many applications, this is a poor substitute for marked-up text or even simple ASCII characters. In particular, it is not possible to search a page image for specific words. The serious scholar sometimes needs to work from the original and frequently needs to know its appearance. On other occasions, an electronic version that identifies the structure is superior; a marked-up electronic text is more convenient than an image of the original for creating a concordance or for textual analysis, since the text can be tagged to indicate its linguistic structure or its historical antecedents. Therefore the next stage of conversion is to provide an electronic text from the page image.
Optical character recognition is the technique of converting scanned images of characters to their equivalent characters. The basic technique is for a computer program to separate out the individual characters, and then to compare each character to mathematical templates. Despite decades of research, optical character recognition remains an inexact process. The error rate varies with the legibility of the original. If the original document is clear and legible, the error rate is less than one percent. With poor quality materials the error rate can be much higher. For many purposes, an error rate of even a fraction of one percent is too high. It corresponds to many incorrect characters on every page.
Various processes have been devised to get around these errors. One technique is to use several different character recognition programs on the same materials. Hopefully, characters that cause one program difficulty may be resolved by the others. Another approach is to use a dictionary to check the results. However, all high-quality conversion requires human proof reading. In some systems, a computer program displays the converted text on a screen, and highlights doubtful words with suggestions which an editor can accept or correct. One organization that has developed efficient processes of this type is UMI, which converts huge numbers of theses every year. Since most theses received by UMI are new, clean copy, UMI achieves low error rates from optical character recognition combined with manual resolution of doubtful words.
When the individual words have been recognized, the next stage of conversion is to identify the structure of a document and to tag key structural elements, such as headings. This is another aspect where, despite steady progress by researchers, high-quality conversion requires human proof reading and editing.
There is an alternative method of conversion that is widely used in practice: to retype the document from scratch and add mark-up tags manually. This approach is often cheaper than a combination of automatic and human processing. Since the work is labor intensive, it is usually carried out in countries where labor costs are low. One of the largest conversion projects is the Library of Congress's American Memory program. The documents to be converted are selected from the library's historic collections and are often less clear than a recently printed document. The conversion is carried out by contractors who guarantee a specified level of accuracy, but are at liberty to carry out the conversion by any convenient method. All the early contractors decided that the most economical method was to convert the documents by retyping them.
Encoding characters
ASCII
When representing text in a computer, the most basic elements are characters. It is important to distinguish between the concept of a character as a structural element and the various representations of that character, stored within a computer or displayed for reading. A character, such as the capital letter "A", is an abstract concept, which is independent of the encoding used for storage in a computer or the format used to display it.
Computers store a character, such as "A" or "5", as a sequence of bits, in which each distinct character is encoded as a different sequence. Early computers had codes for the twenty six letters of English (upper and lower case), the ten digits, and a small number of punctuation marks and special symbols. The internal storage representation within most computers is still derived from this limited character set. Most modern computers represent characters using the ASCII code. (ASCII stands for American Standard Code for Information Interchange, but the full form of the name is seldom used.)
Originally, ASCII represented each character by seven bits. This 7-bit encoding is known as standard ASCII. For example, the character "A" is encoded as the 7-bit sequence 1000001. Considered as a binary number, this sequence is the number 65. Hence, it is conventional to state that, in the standard ASCII code, the number 65 represents the character "A". There are 128 different pattern that can be made with seven bits. Standard ASCII associates a specific character with each number between 0 and 127. Of these, the characters 0 to 31 represent control characters, e.g., "carriage return". Table 9.1 shows the ASCII codes 32 to 127, known as the printable ASCII character set. (The space character is considered to be a printable character.)
|
Printable ASCII
|
Table 9.1. The printable character set from 7-bit ASCII
The printable ASCII character set is truly a standard. The same codes are used in a very wide range of computers and applications. Therefore, the ninety six printable ASCII characters are used in applications where interoperability has high priority. They are the only characters allowed in HTML and in many electronic mail systems. Almost every computer keyboard, display, and software program interprets these codes in the same way. There is also an extended version of ASCII that uses eight bits. It provides additional character encodings for the numbers 128 to 255, but it is not as universally accepted as 7-bit ASCII.
Unicode
Textual materials use a much wider range of characters than the printable ASCII set, with its basis in the English language. Other languages have scripts that require different character sets. Some European languages have additional letters or use diacritics. Even Old English requires extra characters. Other languages, such as Greek or Russian, have different alphabets. The Chinese, Japanese, and Korean writing does not use an alphabet. These languages use the Han characters, which represent complete words or syllables with a single character. Even for texts written in current English, the printable ASCII characters are inadequate. Disciplines such as mathematics, music, or chemistry use highly refined notation that require large numbers of characters. In each of these fields, comprehension often depends critically on the use of accepted conventions of notation.
The computer industry sells its products world-wide and recognizes the need to support the characters used by their customers around the world. This is an area in which the much-maligned Microsoft Corporation has been a leader. Since it is impossible to represent all languages using the 256 possibilities represented by an eight-bit byte, there have been several attempts to represent a greater range of character sets using a larger number of bits. Recently, one of these approaches has emerged as the standard that most computer manufacturers and software houses are supporting. It is called Unicode.
In strict Unicode, each character is represented by sixteen bits, allowing for a up to 65,536 distinct characters. Through the painstaking efforts of a number of dedicated specialists, the scripts used in a wide range of languages can now be represented in Unicode. Panel 9.3 lists the scripts that were completed by late 1997.
|
Panel 9.3 Version 2.0 of the Unicode standard contains 16-bit codes for 38,885 distinct characters. The encoding is organized by scripts rather than languages. Where several languages use a closely related set of characters, the set of symbols that covers the group of languages is identified as a single script. The Latin script contains all the characters used by English, French, Spanish, German, and related languages. Unicode 2.0 supports the following scripts:
In addition to the above primary scripts, a number of other collections of symbols are also encoded by Unicode. They include the following: Numbers General Diacritics General Punctuation General Symbols Mathematical Symbols Technical Symbols Dingbats Arrows, Blocks, Box Drawing Forms, & Geometric Shapes Miscellaneous Symbols Presentation Forms Unicode does not cover everything. Several modern languages, such as Ethiopic and Sinhala, will eventually be included. There are also numerous archaic scripts, such as Aramaic, Etruscan, and runes, which will probably be included at some date. One important aspect of Unicode is support for the Han characters used by Chinese, Japanese, and Korean. Unicode supports the Unihan database, which is the result of an earlier project to reconcile the encoding systems previously used for these languages. |
The acceptance of Unicode is not simply through the efforts of linguistic scholars in supporting a wide range of languages. The developers have thought carefully about the relationship between Unicode and existing software. If every computer program had to be changed, Unicode would never be adopted. Therefore, there is a special representation of the Unicode characters, known as UTF-8, that allows gradual transformation of ASCII-based applications to the full range of Unicode scripts.
UTF-8 is an encoding that uses from one to six bytes to represent each Unicode character. The most commonly used characters are represented by a single byte, the next most common by two bytes, the least common by six bytes. The crucial part of the design is that each printable ASCII character is represented by a single byte, which is identical to the corresponding ASCII character. Thus the same sequence of bytes can be interpreted as either Unicode characters (in UTF-8 representation) or as printable ASCII. For example, a page of HTML text, which has been created using printable ASCII characters, requires no modification to be used with a program that expects its data to be in UTF-8 encoding.
Transliteration
Unicode is not the only method used to represent a wide range of characters in computers. One approach is transliteration. This is a systematic way to convert characters in one alphabet into another set of characters. For example, the German � is sometimes transliterated oe. A phonetic system of transliteration known as pinyin is frequently used to represent Chinese, especially Mandarin, in the English alphabet. Transliteration may have been acceptable in the days when typewriters were manual devices with a physically constrained character set. With today's computers, transliteration should not be needed and hopefully will soon become ancient history.
Libraries have a more immediate problem. They were using a wide range of alphabets long before the computing industry paid attention to the problem. In fact, libraries were well-advanced in this area in the days when most computers supported only upper case letters. As a result, MARC catalogs and other library systems contain huge volumes of material that are encoded in systems other than Unicode, including pinyin, and face a daunting task of conversion or coexistence.
SGML
Mark-up languages have been used since the early days of computing to describe the structure of the text and the format with which the text is to be displayed. Today, the most commonly used are the SGML family of languages.
SGML is not a single mark-up language. It is a system to define mark-up specifications. An individual specification defined within the SGML framework is called a document type definition (DTD). Many publishers and other agencies have developed their own private DTDs. Examples of DTDs that are of particular importance to scholarly libraries are the Text Encoding Initiative and the Encoded Archival Description, which are described in Panel 9.4.
|
Panel 9.4 Text Encoding Initiative The Text Encoding Initiative (TEI) was an early and very thorough effort to represent existing texts in digital form, with an emphasis on use by humanities scholars. Documents from the past include almost every approach that has ever been used to represent text on paper, velum, papyrus, or even stone. They include print, handwriting, typewriting, and more. The documents include annotation, deletions, and damaged portions that can not be read. Every character set the world has ever known may be present. SGML has proved effective in describing these materials, but designing the DTD provided a challenge. It would have been easy to have created a DTD that was so complex as to be completed unwieldy. The solution has been to create a family of DTDs, built up from components. A core tag set defines elements likely to be needed by all documents and therefore is part of all DTDs. Each DTD is required to add a base set of tags, selected from a choice of tags for prose, verse, drama, dictionaries, or data files. Usually, only one base tag set is appropriate for a given document. Finally, a variety of additional tag sets are available for specialized purposes. (The authors call this the Chicago Pizza model: every pizza has cheese and tomato sauce, one base, and optional extra toppings.) The Encoded Archival Description (EAD) The term finding aid covers a wide range of lists, inventories, indexes, and other textual documents created by archives, libraries, and museums to describe their holdings. Some finding aids provide fuller information than is normally contained within cataloging records; others are less specific and do not necessarily have detailed records for every item in a collection. Some are short; others run to hundreds of pages. The Encoded Archival Description (EAD) is a DTD used to encode electronic versions of archival aids. The first version of the DTD was developed by a team from the University of California at Berkeley. The effort drew on experience from the Text Encoding Initiative. It reflects the conventions and practices established by archivists, and uses the heavily structured nature of finding aids. Much of the information is derived from hierarchical relationships and there are many other interrelationships that must be explicitly recognized when encoding a finding aid for use in a digital library. The EAD has been widely embraced by archivists, who have worked collaboratively to refine the DTD, test it against existing finding aids, and provide extensive documentation. The EAD has become a highly specialized tool, tailored for the needs of a specialized community. For use by that community, it is an important tool that allows them to exchange and share information. |
A DTD is built up from the general concepts of entities and elements. A DTD defines what entities and elements are allowable in a particular class of documents and declares the base character set encoding used for the document. Entities are specified by identifiers that begin with the letter "&" and end with ";". Here are some examples:
α
&logo;
In a typical DTD, the allowable entities include most of the ASCII character set and other characters, known as character entities, but any symbol or group of symbols can be defined as a entity. The name of the entity is simply a name. In standard character sets, "α", is the entity used to encode the first letter of the Greek alphabet, but a DTD could use this code for some totally different purpose. The DTDs used by scientific publishers define as many as 4,000 separate entities to represent all the special symbols and the variants used in different scientific disciplines.
Entities provide a stream of symbols that can be grouped together into elements. A DTD can define any string as the name of an element. The element is bracketed by two tags in angle brackets, with "/" used to denote the end tag. Thus the Text Encoding Initiative uses the tags <del> and </del> to bracket text that has been crossed-out in a manuscript. To mark the words "men and women" as crossed-out, they would be tagged as:
<del>men and women</del>
Examples of elements include the various types of headings, footnotes, expressions, references, and so on. Elements can be nested in hierarchical relationships. Each DTD has a grammar that specifies the allowable relationships as a set of rules that can be processed by a computer program.
Simplified versions of SGML
SGML is firmly established as a flexible approach for recording and storing high-quality texts. Its flexibility permits creators of textual materials to generate DTDs that are tailored to their particular needs. Panels 9.1 and 9.3 describe some examples. Publishers of scientific journals have developed their own DTDs, which they use in-house to mark-up journal articles as they are created and to store them on computers. Digital library projects, such as JSTOR and American Memory, use simple DTDs that are derived from the work of the Text Encoding Initiative.
The disadvantage of SGML's flexibility is the complexity of the software needed to process it. While a program to parse and render a simple DTD is not hard to write, it is a forbidding task to create a general-purpose package that can parse any DTD, combine information from any style sheet and render the document either on a computer screen or printer. The market for such software is quite small. Only one company has persevered and created a general package for rendering SGML. Even this package is not perfect; it does not implement all of SGML, runs only on some types of computers, and uses its own private form of style sheets. Hence, full SGML is unsuitable for use in digital libraries that emphasize interoperability with other systems.
HTML
The web has stimulated the development of simplified versions of SGML. HTML, the mark-up language used by the web, can be considered an unorthodox DTD. In many ways, however, it diverges from the philosophy of SGML, because it mixes structural information with format. HTML may have begun life as structural mark-up, relying on browsers to determine how to format the text for display, but its subsequent development has added a large number of features that give the designer of web pages control over how their material appears when rendered for screen display or printing. Panel 9.5 illustrates how far HTML has diverged from purely structural mark-up.
|
Panel 9.5 HTML provides a variety of tags that are inserted into documents. Usually tags are in pairs; e.g., the pair of tags below indicates that the enclosed text is a main heading. <h1>This is a main heading</h1> A few tags are self-contained and do not bracket any text. An example is <hr>, which indicates a horizontal rule. Elements are often embedded or nested within each other. For example, a list can contain many paragraphs and tables can contain other tables. The following examples are typical of the features provided by HTML. There are many more and several of these features have a wide selection of options. They illustrate how HTML combines structural mark-up with formatting and support for online applications. Structural elements Many of the tags in HTML are used to describe the structural elements of a document. They include the following.
Formatting Other tags in HTML define the appearance of the document when it is rendered for display on a computer or printed. They include the following.
Online services A final group of HTML tags are designed for online applications. They include the following.
|
HTML has grown from its simple beginnings and is continuing to grow. Depending on the viewpoint, these additions can be described as making HTML more powerful, or as adding complexity and inconvenience. Nobody would argue the great value of some additions, such as being able to embed images, through the <img> tag, which was introduced in Mosaic. The value of other additions is a matter of opinion. Simple formatting commands, such as <center> introduced by Netscape, can do little harm, but other features have added a great deal of complexity. Perhaps the most notable are the use of tables and frames. These two additions, more than any other, have changed HTML from a simple mark-up language. No longer can an author learn HTML in a morning or a programmer write a program to render HTML in a week.
The tension between structural mark-up in HTML and formatting to control appearance has become a serious problem. As discussed in the last chapter, many creators of web pages want to control what the user sees. They have difficulty accepting that they do not determine the appearance of a document, as seen by the user, and use every opportunity that HTML provides to control the appearance. An unfortunate trend is for designers to use structural elements to manipulate the design; many web pages are laid out as a single huge table, so that the designer can control the margins seen by the user. Skilled designers construct elegant web pages using such tricks. Less skilled designers impose on the users pages that are awkward to use. The worst abuses occur when a designer imposes a page layout that will not fit in the window size that the user chooses or over-rides a user preference, perhaps preventing a user with poor eyesight from using a large type size.
Almost all new features that have been added to HTML have come from the developers of browsers adding features, to enhance their products or to keep pace with their competitors. Some were indeed improvements, but others were unnecessary. The World Wide Web Consortium and the Internet Engineering Task Force provide valuable coordination and attempt to provide standards, but the fundamental control of HTML is exercised by the two principal browser manufacturers, Netscape and Microsoft.
XML
XML is a variant of SGML that attempts to bridge the gap between the simplicity of HTML and the power of full SGML. Simplicity is the key to the success of HTML, but simplicity is also its weakness. Every time a new feature is added to HTML it becomes less elegant, harder to use, and less of a standard shared by all browsers. SGML is the opposite. It is so flexible that almost any text description is possible, but the flexibility comes at the cost of complexity. Even after many years, only a few specialists are really comfortable with SGML and general-purpose software is still scarce.
XML is a subset of SGML that has been designed explicitly for use with the web. The design is based on two important criteria. The first is that it is simple to write computer programs that manipulate XML. The second is that it builds on the familiar world of HTML, so that people and systems can migrate to XML with a minimum of pain.
The underlying character set for XML is 16-bit Unicode, and in particular the UTF-8 stream encoding. This permits documents to be written in standard ASCII, but supports a wide range of languages and character sets. For convenience, some character entities are pre-defined, such as < and > for the less-than and greater-than symbols. XML does not specify particular methods for representing mathematics, but a there is a separate effort, MathML, tackling the problems of mathematics.
Standard HTML is acceptable as XML with minimal modifications. One modification is that end tags are always needed. For example, in HTML, the tags <p> and </p> delimit the beginning and end of a paragraph, but the </p> is optional, when followed by another paragraph. In XML the end tag is always needed. The other major modification concerns HTML tags that do not delimit any content. For example, the tag <br> indicates a line break. Standard HTML does not use an </br> tag. With XML, a line break is tagged either with the pair <br></br> or with the special shortened tag <br/>.
Since XML is a subset of SGML, every document is based on a DTD, but the DTD does not have to be specified explicitly. If the file contains previously undefined pairs of tags, which delimit some section of a document, the parser automatically adds them to the DTD.
The developers of XML have worked hard to gain wide acceptance for their work. Their strategy follows the philosophy of the Internet mainstream. The design has been an open process hosted by the World Wide Web Consortium. From the start, members of the design team wrote demonstration software that they have distributed freely to interested parties. Leading corporations, notably Microsoft and Netscape, have lent their support. This deliberate building of consensus and support seems to have been successful, and XML looks likely to become widely adopted.
Style sheets
Mark-up languages describe the structure of a document. SGML and XML use tags to describe the semantics of a document and its component parts. It does not describe the appearance of a document. Thus, SGML tags might be used to identify a section of text as a chapter heading, but would not indicate that a chapter heading starts a new page and is printed with a specific font and alignment. A common need is to take a document that has SGML or XML mark-up and render it for according to a specific design specification. For example, a publisher who creates journal articles according to a DTD may wish to render them in two different ways: printed output for conventional publication, and a screen format for delivery over the Internet and display on a computer screen. The first will be rendered in a format that is input to a typesetting machine. The second will be rendered in one of the formats that are supported by web browsers, usually HTML or PDF.
The process requires that the structural tags in the mark-up be translated into formats that can be displayed either in print or on the screen. This uses a style sheet. For example, a DTD may define an element as a heading of level two, denoted by <h2> and </h2> tags. The style sheet may state that this should be displayed as 13 points Times Roman font, bold, left aligned. It will also specify important characteristics such as the appropriate line spacing and how to treat a heading that falls near the bottom of the page. A style sheet provides detailed instructions for how to render every conceivable valid document that has been marked-up according to a specific DTD.
In creating style sheets, the power of SGML is a disadvantage. Readers are accustomed to beautifully designed books. Much of this beauty comes from the skill of the craftsmen who carry out the composition and page layout. Much of their work is art. The human eye is very sensitive; the details of how statistical tables are formatted, or the layout and pagination of an art book have never been reduced to mechanical rules. Style sheets can easily be very complex, yet still fail to be satisfactory when rendering complex documents.
Since SGML is a general framework, people have been working on the general problem of specifying style sheets for any DTD. This work is called Document Style Semantics and Specification Language (DSSSL). The developers of DSSSL are faced with a forbidding task. To date, DSSSL rendering programs have been written for some simple DTDs, but the general task appears too ambitious. It is much easier to create a satisfactory style sheet for a single DTD, used in a well-understood context. Many books and journals are printed from SGML mark-up, with special-purpose style sheets, and the results can be excellent.
With HTML, there has been no formal concept of style sheets. The mark-up combines structural elements, such as various types of list, with formatting tags, such as those that specify bold or italic fonts. The tags provide general guidance about appearance, which individual browsers interpret and adapt to the computer display in use. The appearance that the user sees comes from a combination of the mark-up provided by the designer of a web page, the formatting conventions built into a browser, and options chosen by the user. Authors of HTML documents wishing for greater control can embed various forms of scripts, applets, and plug-ins.
Panel 9.6 describes CSS (Cascading Style Sheets) and XLS (Extensible Style Language) (XSL), methods for providing style sheets for HTML and XML. The developers of XML have realized that the greatest challenge to be faced by XML before it becomes widely accepted is how to control the appearance of documents and have been supportive of both CSS and XSL. It is still too early to know what will succeed, but the combination is promising. These methods have the important concept of laying down precise rules for the action to take when the styles specified by the designer and the user disagree.
|
Panel 9.6 Mark-up languages describe the structural elements of a document. Style sheets specify how the elements appear when rendered on a computer display or printed on paper. Cascading Style Sheets (CSS) were developed for use with HTML mark-up. The Extensible Style Language (XSL) is an extension for XML mark-up. Just as XML is a simplified version of full SGML that provides a simple conversion from HTML, XSL is derived from DSSSL and any CSS style sheet can be converted to XSL by a purely mechanical process. The original hope was that XSL would be a subset of DSSSL, but there are divergences. Currently, XSL is only a specification, but there is every hope that, as XML becomes widely adopted, XSL will become equally important. Rules In CSS a rule defines styles to be applied to selected elements of a document. Here is a simple rule: h1 {color: blue} This rule states that for elements "h1", which is the HTML tag for top-level headings, the property "color" should have the value "blue". More formally, each rule consists of a selector, which selects certain elements of the document, and a declaration, enclosed in braces, which states a style to be applied to those elements. The declaration has two parts, a property and a value, separated by a colon. A CSS style sheet is a list of rules. Various conventions are provided to simplify the writing of rule. For example, the following rule specifies that headings h1 and h2 are to be displayed in blue, using a sans-serif font. h1, h2 {font-family: sans-serif; color: blue} Inheritance The mark-up for an HTML document defines a structure which can be represented as a hierarchy. Thus headings, paragraphs, and lists are elements of the HTML body; list items are elements within lists; lists can be nested within each other. The rules in CSS style sheets also inherit from each other. If no rule explicitly selects an element, it inherits the rules for the elements higher in the hierarchy. For example, consider the pair of rules: body {font-family: serif} Headings h1 and h2 are elements of the HTML body, but have an explicit rule; they will be displayed with a sans-serif font. In this example, there is no explicit rule for paragraphs or lists. Therefore they inherit the styles that apply to body, which is higher up the hierarchy, and will be displayed with a serif typeface. Cascading Style sheets must be associated with an HTML page. The designer has several options, including embedding the style at the head of a page, or providing a link to an external file that contains the style sheet. Every browser has its own style sheet, which may be modified by the user, and a user may have a private style sheet. Since several style sheets may apply to the same page, conflicts can occur, where rules conflict. A series of mechanisms have been developed to handle these situations, based on some simple principles. The most fundamental principle is that, when rules conflict, one is selected and the others are ignored. Rules that explicit select elements have priority over rules that are inherited. The most controversial convention is that when the designer's rule conflicts directly with the user's, the designer's has precedence. A user who wishes to over-ride this rule can mark a rule with the flag "!important", but this is awkward. However, it does permit special style sheets to be developed, for instance for users who have poor eyesight and wish to specify large font sizes. |
Page-description languages
Since creators and readers both give high priority to the appearance of documents, it is natural to have methods that specify the appearance of a document directly, without going via structural mark-up. The methods differ greatly in details, but the underlying objective is the same, to render textual materials with the same graphic quality and control as the best documents printed by traditional methods. This is not easy. Few things in life are as pleasant to use as a well-printed book. Over the years, typography, page layout, paper manufacturing, and book binding have been refined to a high level of usability. Early text formatting methods were designed for printed output, but display on computer screens has become equally important. This section looks at three page-description languages: TeX, PostScript, and PDF. These three languages have different objectives and address them differently, but they are all practical, pragmatic approaches that perform well in production systems.
TeX
TeX is the earliest. It was developed by Donald Knuth and is aimed at high-quality printing, with a special emphasis on mathematics. The problems of encoding mathematics are complex. In addition to the numerous special characters, the notation relies on complex expressions that are not naturally represented as a single sequence of characters. TeX provides rules for encoding mathematics as a sequence of ASCII characters for input, storage, and manipulation by computer, with tags to indicate the format for display.
Most users make use of one of two TeX packages, plainTeX or LaTex. These packages define a set of formatting tags that cover the majority of situations that are normally encountered in typesetting. Closely allied with TeX is a system for designing fonts called Metafont. Knuth has taken great pains to produce versions of his standard font for a wide range of computer systems.
TeX remains unsurpassed for the preparation of printed mathematical papers. It is widely used by authors and journals in mathematics, physics, and related fields.
PostScript
PostScript was the first product of the Adobe corporation, which spun off from Xerox in 1984. PostScript is a programming language, to create graphical output for printing. Few people ever write programs in PostScript, but many computers have printer routines that will take text or graphics and create an equivalent PostScript program. The program can then be sent to a printer controller that executes the PostScript program and creates control sequences to drive the printer.
Explicit support for fonts is one of PostScript's strengths. Much of the early success of the Apple Macintosh computer came from the combination of bit-mapped designs on the screen with PostScript printers that provided a quality of output previously available only on very expensive computers. With both laser printing and screen display, characters are built up from small dots. Simple laser printers use 300 dots per inch and typesetting machines may have a resolution of 1,200 dots per inch or more, but most computer screens are about 75 dots per inch. The fonts that appear attractive on a computer screen are not quite the same as the ones used for printing, and the displays of text on a screen must be fitted to the coarse resolution. Usually, the operating system functions that display text on a screen are different from the PostScript commands used for printing. Unless great care is taken, this can lead to different page breaks and other unacceptable variations.
Although PostScript is primarily a graphical output language, which had its initial impact representing computer output to laser printers, PostScript programs are used in other applications, as a format to store and exchange representations of any text or graphical output. PostScript is not ideal for this purpose, since the language has many variations and the programs make assumptions about the capabilities of the computer that they will be executed on. PDF, which built on Adobe's experience with PostScript, is a better format for storing page images in a portable format that is independent of any particular computer.
Portable Document Format (PDF)
The most popular page description language in use today is Adobe's Portable Document Format (PDF), which is described in Panel 9.7. Adobe has built on its experience with PostScript to create a powerful format and a set of tools to create, store, and display documents in it.
|
Panel 9.7 Adobe's Portable Document Format (PDF) is an important format. It is also interesting as an example of how a corporation can create a standard, make it available to the world, and yet still generate good business. PDF is a file format used to represent a document that is independent of applications and computer system. A PDF document consists of pages, each made up of text, graphics, and images, with supporting data. However, PDF pages can go beyond the static print view of a page, by supporting features that are only possible electronically, such as hyperlinks and searching. PDF is an evolution of the PostScript programming language, which was also created by Adobe. One way to generate PDF is by diverting a stream of data that would usually go to a printer and storing it as a PDF file. Alternatively, the file can be converted from PostScript or other formats. The file can then be stored, transmitted over a network, displayed on a computer, or printed. Technical reasons for PDF's success Technically, PDF has many strengths. When viewed on a computer screen, most PDF documents are very legible while retaining the design characteristics of print. Except when they include bit-mapped images, the files are of moderate size. If the computer that is displaying a PDF document does not have the fonts that were used to generate it, font descriptors enable the PDF viewer to generate an artificial font that is usually close to the original. The electronic additions are simple to use and provide many of the features that users want. They include hyperlinks, either within the document or to external URLs. The viewers provide a tool for searching for words within the text, though searching across documents is a problem. Annotations are provided. Printer support is excellent. There is even a method that creators can use to prevent users from printing or otherwise using a document in ways that are not approved. PDF is not perfect. It has problems distinguishing between certain types of file, or working with unusual fonts, but overall it has become a important format for online documents. Business reasons for PDF's success After a hesitant introduction, Adobe has been shrewd in its marketing of PDF. The company provides excellent PDF viewers for almost every known type of computer; they are freely available over the Internet. Adobe makes its money from a family of products that are used by people who create PDF files, not from the users of these files. Adobe owns the copyright in the PDF specification, but, to promote its use as an interchange format, gives broad permissions to anyone to create PDF files, to write applications that produce PDF output, and to write software that reads and processes PDF files. Potentially, competitors could create products that undercut those that Adobe sells, but the company accepts that risk. |
PDF is widely used in commercial document management systems, but some digital libraries have been reluctant to use PDF. One reason is technical. PDF is best suited for representing documents that were generated from computer originals. PDF can also store bit-mapped images, and Adobe provides optical character recognition software to create PDF files, but many of PDF's advantages are lost when the used to store image files. The file sizes can be unpleasantly large and much of the flexibility that digital libraries require is lost.
In addition, some digital libraries and archives reject PDF because the format is proprietary to a single company. There is a fear that the decision to use PDF in a digital library is more vulnerable to future events than using a format blessed by one of the standards bodies. This reasoning appears misguided. PDF had its first success with corporate America, which welcomes well-supported, commercial products. The academic and scholarly community can accept that a format maintained by a corporation may be more stable in the long term than official standards that are not backed by good products and a wide user base. The definition of the format is widely published and the broad use of PDF in commercial applications guarantees that programs will be available for PDF, even if Adobe went out of business or ceased to support it.
Structure versus appearance of documents
This chapter began with a discussion of two requirements for storing documents in digital libraries: representations of structure and of appearance. They should not be seen as alternatives or competitors, but as twin needs, both of which deserve attention. In some applications a single representation serves both purpose, but a large number of digital libraries are storing two versions of each document. Textual materials are at the heart of digital libraries and electronic publishing. Authors and readers are very demanding, but the methods exist to meet their demands.
Last revision of content: January 1999
Formatted for the Web: December 2002
(c) Copyright The MIT Press 2000