Chapter 4. General concepts
- Table of Contents
- 4.1. Multitasking
- 4.2. Filesystem hierarchy
- 4.3. Devices
This chapter gives an introduction to some general UNIX and GNU/Linux concepts. It is important to read this chapter thoroughly if you do not have any UNIX or GNU/Linux experience. Many concepts covered in this chapter are used in this book and in GNU/Linux.
4.1. Multitasking
4.1.1. Introduction
One of UNIX's traditional strengths is multitasking. Multitasking means that multiple programs can be run at the same time. You may wonder why this is important, because most people use only one application at a time. Multitasking is a bare necessity for UNIX-like systems. Even if you have not started any applications, there are programs that run in the background. For instance, some programs provide network services, while others show a login prompt and wait until a user logs in on a (virtual) terminal. Programs that are running in the background are often called daemon processes[1].
4.1.2. Processes and threads
After a program is loaded from a storage medium, an instance of the program is started. This instance is called a process. A process has its own protected memory, named the process address space. The process address space has two important areas: the text area and the data area. The text area is the actual program code; it is used to tell the system what to do. The data area is used to store constant and runtime data. The operating system gives every process time to execute. On single processor systems processes are not really running simultaneously. In reality a smart scheduler in the kernel divides CPU time among processes, giving the illusion that processes run simultaneously. This process is called time-sharing. On systems with more than one CPU or CPU cores, more than one process can run simultaneously, but time-sharing is still used to divide the available CPU time among processes.
New processes are created by duplicating a running process with the fork(2) system call. Figure Figure 4-1 shows a fork() call in action schematically. The parent process issues a fork() call. The kernel will respond to this call by duplicating the process, and naming one process the parent, and the other process the child.
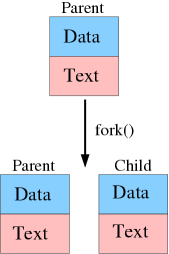
Forking can be used by a program to create two processes that can run simultaneously on multiprocessor machines. However, this is often not ideal, because both processes will have their own process address space. The initial duplication of the process memory takes relatively much time, and it is difficult to share data between two processes. This problem is solved by a concept named multithreading. Multithreading means that multiple instances of the text area can run at the same time, sharing the data area. These instances, named threads, can be executed in parallel on multiple CPUs.
4.2. Filesystem hierarchy
4.2.1. Structure
Operating systems store data in filesystems. A filesystem is basically a tree-like structure of directories that hold files, like the operating system, user programs and user data. Most filesystems can also store various metadata about files and directories, for instance access and modification times. In GNU/Linux there is only one filesystem hierarchy, this means GNU/Linux does not have drive letters (e.g. A:, C:, D:) for different filesystems, like DOS and Windows. The filesystem looks like a tree, with a root directory (which has no parent directory), branches, and leaves (directories with no subdirectories). The root directory is alway denoted with a slash ("/"). Directories are separated by the same character.
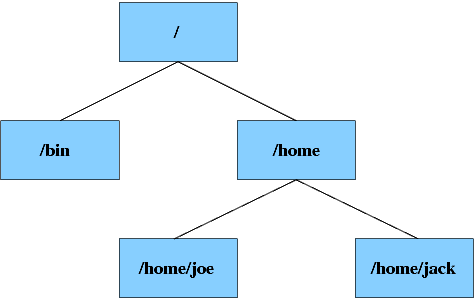
Figure 4-2 shows the structure of a filesystem. You can see that the root directory / has two child directories: bin and home. The home directory has two child directories, joe and jack. The diagram shows the full pathname of each directory. The same notation is used for files. Suppose that there is a file named memo.txt in the /home/jack directory, the full path of the file is /home/jack/memo.txt.
Each directory has two special entries, ".", and "..". The first refers to the directory itself, the second to the parent directory. These entries can be used for making relative paths. If you are working in the jack directory, you can refer to the the /home/joe directory with ../joe.
4.2.2. Mounting
You might wonder how it is possible to access other devices or partitions than the hard disk partition which holds the root filesystem. Linux uses the same approach as UNIX for accessing other filesystems. Linux allows the system administrator to connect a device to any directory in the filesystem structure. This process is named mounting. For example, one could mount the CD-ROM drive to the /cdrom directory. If the mount is correct, the files on the CD-ROM can be accessed through this directory. The mounting process is described in detail in Section 8.6.
4.2.3. Common directories
The Filesystem Hierarchy Standard Group has attempted to create a standard that describes which directories should be available on a GNU/Linux system. Currently, most major distributions use the Filesystem Hierarchy Standard (FHS) as a guideline. This section describes some mandatory directories on GNU/Linux systems.
Please note that GNU/Linux does not have a separate directory for each application (like Windows). Instead, files are ordered by function and type. For example, the binaries for most common user programs are stored in /usr/bin, and their libraries in /usr/lib. This is a short overview of the important directories on a Slackware Linux system:
-
/bin: essential user binaries that should still be available in case the /usr is not mounted.
-
/dev: device files. These are special files used to access certain devices.
-
/etc: the /etc directory contains all important configuration files.
-
/home: contains home directories for individual users.
-
/lib: essential system libraries (like glibc), and kernel modules.
-
/root: home directory for the root user.
-
/sbin: essential binaries that are used for system administration.
-
/tmp: a world-writable directory for temporary files.
-
/usr/X11R6: the X Window System.
-
/usr/bin: stores the majority of the user binaries.
-
/usr/lib: libraries that are not essential for the system to boot.
-
/usr/sbin: nonessential system administration binaries.
-
/var: variable data files, like logs.
4.3. Devices
4.3.1. Introduction
In GNU/Linux virtually everything is represented as a file, including devices. Every GNU/Linux system has a directory with special files, named /dev. Each file in the /dev directory represents a device or pseudo-device. A device file has two special numbers associated with it, the major and the minor device number. The kernel knows which device a device file represents by these device numbers. The following example shows the device numbers for the /dev/zero device file:
$ file /dev/zero
/dev/zero: character special (1/5)
The file(1) command can be used to determine the type of a file. This particular file is recognized as a device file that has 1 as the major device number, and 5 as the minor device number.
If you have installed the kernel source package, you can find a comprehensive list of all major devices with their minor and major numbers in /usr/src/linux/Documentation/devices.txt. An up-to-date list is also available on-line at through the Linux Kernel Archives[2].
The Linux kernel handles two types of devices: character and block devices. Character devices can be read byte by byte, block devices can not. Block devices are read per block (for example 4096 bytes at a time). Whether a device is a character or block device is determined by the nature of the device. For example, most storage media are block devices, and most input devices are character devices. Block devices have one distinctive advantage, namely that they can be cached. This means that commonly read or written blocks are stored in a special area of the system memory, named the cache. Memory is much faster than most storage media, so much performance can be gained by performing common block read and write operations in memory. Of course, eventually changes have to be written to the storage media to reflect the changes that were made in the cache.
4.3.2. ATA and SCSI devices
There are two kinds of block devices that we are going to look into in detail, because understanding the naming of these devices is crucial for partitioning a hard disk and mounting. Almost all modern computers with an x86 architecture use ATA hard disks and CD-ROMs. Under Linux these devices are named in the following manner:
/dev/hda - master device on the first ATA channel
/dev/hdb - slave device on the first ATA channel
/dev/hdc - master device on the second ATA channel
/dev/hdd - slave device on the second ATA channel
On most computers with a single hard disk, the hard disk is the master device on the first ATA channel (/dev/hda), and the CD-ROM is the master device on the second ATA channel. Hard disk partitions are named after the disk that holds them plus a number. For example, /dev/hda1 is the first partition of the disk represented by the /dev/hda device file.
SCSI hard disks and CD-ROM drives follow an other naming convention. SCSI is not commonly used in most low-end machines, but USB drives and Serial ATA (SATA) drives are also represented as SCSI disks. The following device notation is used for SCSI drives:
/dev/sda - First SCSI disk
/dev/sdb - Second SCSI disk
/dev/sdc - Third SCSI disk
/dev/scd0 - First CD-ROM
/dev/scd1 - Second CD-ROM
/dev/scd2 - Third CD-ROM
Partitions names are constructed in the same way as ATA disks; /dev/sda1 is the first partition on the first SCSI disk.
If you use the software RAID implementation of the Linux kernel, RAID volumes are available as /dev/mdn, in which n is the volume number starting at 0.