 A DSP-based decompressor
unit for high-fidelity MPEG-Audio over TCP/IP networksA DSP-based decompressor
unit for high-fidelity MPEG-Audio over TCP/IP networks
A DSP-based decompressor
unit for high-fidelity MPEG-Audio over TCP/IP networksA DSP-based decompressor
unit for high-fidelity MPEG-Audio over TCP/IP networks[ Home | Contents | Component and tool archive ]
Previous chapter: Digital Signal Processing, next chapter: Design of the DSP hardware
The most common language for implementing advanced DSP algorithms is C, and a free GCC C-compiler was available for the chosen DSP, so Whitney's MPEG-audio core was written in C as well, with the speed-critical parts optimized in hand-written assembler. The actual ISO/IEC 11172-3 MPEG-1 Audio specification is copyrighted and cannot be reproduced in this report, but an overview of the decoding algorithm and the finished C-code is presented. The code is not described line-by-line and the assembler optimizations are so special and regarded out-of-scope for this thesis that they are not described either.
Since it is often troublesome to develop and debug code running on other hardware than the development system, as is the case with the DSP development kit, the code was written to be run on a normal Unix system, in a manner that would make the final porting to the native DSP easy. That way, advantage could be taken of the native Unix debugger such as GDB and memory integrity-checking tools such as Purify. However this multi-platform support also resulted in a lot of conditional compiler-directives, which might make the code harder to browse in certain places where the platforms differ substantially.
When the C-code was ready and tested, it was cross-compiled for the DSP using the special C3x/C4x GCC. The resulting code could either be downloaded into the C31 development kit and run in a real DSP, or simulated using a C31 simulator embedded in the GDB debugger. The former method was used for testing the speed of the code, while the latter was used for tracking down bugs in the assembler-optimized parts of the MPEG algorithm.
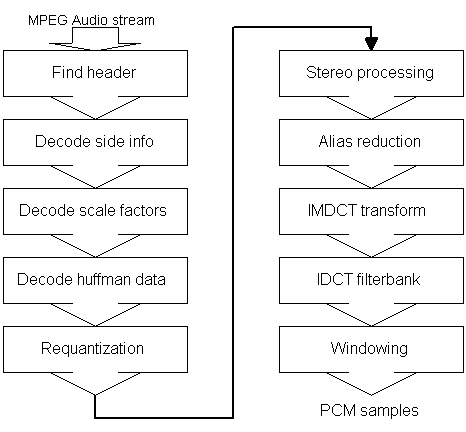
Figure 5: MPEG-1 Layer-3 audio decoder flowchart
All MPEG bitstreams are divided in separate chunks of bits called frames. There is a fixed number of frames per second for each MPEG format, which means that for a given bitrate and sampling frequency, each input frame has a fixed size and produces a fixed number of output samples. In MPEG Audio, frames are independant of each other, which means that it is trivial to fast-forward and back-up in a bitstream - you just skip forward or backward to the next or previous frame. Consequently, the first step in the decoding process is to find the beginning of a frame, and this is done by searching for a synchronization bit-pattern. After this is found, the frame header and side-information can be read. This contains information on how the frame was encoded, so the decoder knows what to do with the data contained in the frame, which is read after the side-information.
The first data transmitted after the header, is the scalefactors. They control the gain for each frequency band. After this comes the actual frequency energies, quantized and huffman-encoded. The decoders task is to huffman-decode, re-quantize, and transform the energies into the time-domain so a sample-output can be made. The huffman encoding in the encoder selectively uses many different huffman trees, according to the data contents, to minimize the total bit-length. The huffman decoder has to select the appropriate huffman tree, and then traverse the tree for each energy-symbol in the frame data, to arrive at the decoded value. When the huffman-decoder has decoded the values, they have to be re-scaled using the scalefactors into real spectral energy values.
If the stream is encoding a stereo signal, each channel can be transmitted separately in every frame, but often the encoder chooses to utilize redundancies between the two channels by transmitting the sum and the difference instead. If this is the case, the decoder has to perform stereo-processing to recover the original two channels. After the stereo recovery, the frequency values in each frequency band are symmetrically added together to smooth out aliasing distortions that appear due to the quantising.
So far the signals have all been in the frequency domain, and to synthesise the output samples, a transform is applied that is the reverse of the time-to-frequency transform used in the encoder. In layer-3, two transforms are done after each other to get better frequency resolution than in the other layers. Both transforms are essentially critically sampled Discrete Cosinus Transforms (DCT's). This means that if no quantizing had been done, the decoder would have reconstructed the original signal perfectly. To avoid discontinuities between transformed blocks, which would result in very perceptible noise and clicks, the transforms use a 50% overlap. This means that if the blocksize is X, the encoder only advances the input pointer X/2 samples for each transformed block. The decoder does the reverse - every re-transformed blocks samples are overlapped with half of the previous blocks samples. This process smoothes out any discontinuities. After the transform is done in the decoder, the only thing left before sample-output is low-pass filtering. This is needed to reconstruct the original signal which was low-pass filtered at the encoder input as well. The low-pass filtering is realised by convolution with a sinc-shaped wave. Technically, every output sample becomes a weighted average of the surrounding 512 time-domain transformed samples, and the shape of the 512 weights is predefined in the MPEG-audio standard.
The main C-code and coding conventions can be found in Appendix D.
Apart from the exact implementation of the MPEG-1 Layer-3 decoding algorithm, code had to be written to allow the streaming of data from the DSP's serial input port into the algorithms input. This was solved by a ring-buffer, filled by the DSP's serial input port interrupt routine, and having the decoder wait for enough data to arrive in the buffer to be able to decode at least a whole MPEG frame. When the buffer is full, the DSP sets the parallel port BUSY signal which stops the host from sending more MPEG data until the buffer has more space.
At the output side of the decoding algorithm, there is a double buffer where the decoder decodes data into one of the buffers while the other buffer is being read-out to the D/A converter for playback. When the playing buffer is ready, the buffers are switched and the decoder starts decoding the next buffer. The buffersize is equal to the sample length of four MPEG frames. For glitchfree playback, the decoder has to be fast enough to decode four MPEG frames before the last four in the buffer are played back. It was not possible to achieve this speed with just algorithmical optimizations in the C-code, so hand-optimized DSP assembler had to be used for the most speed-critical parts (defined as the parts of the code that are looped through most times per decoded frame).
The inverse DCT transforms were algorithmically optimized using Lee's fast IDCT method, described in a web document published by Intel.
Previous chapter: Digital Signal Processing, next chapter: Design of the DSP hardware
This document may be freely distributed for educational purposes. See the copyright notice for additional information.